-
Dashboard
-
Overall community analytics
-
Comment Analysis
Inspiration
Reddit moderation in 2026 has a new problem that toxic-content filters weren't built for: the quiet flood of structurally-templated, low-effort comments — often LLM-assisted — that aren't quite spammy enough to remove individually but collectively drown out genuine community signal.
Mods face an impossible choice: let it through and watch discourse degrade, or carpet-bomb removals and false-positive real humans who used ChatGPT to fix their grammar. Neither is acceptable.
We wanted to build a tool that augments mod judgment rather than replacing it — one that ranks risk, surfaces the worst, and puts every final decision in human hands.
What it does
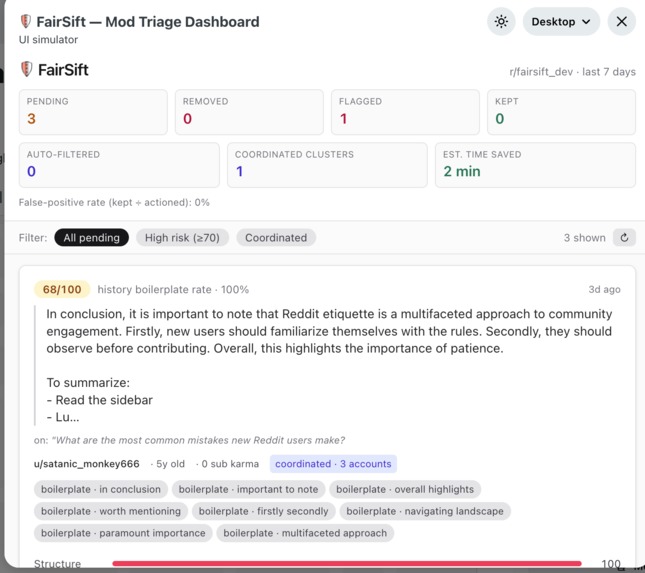
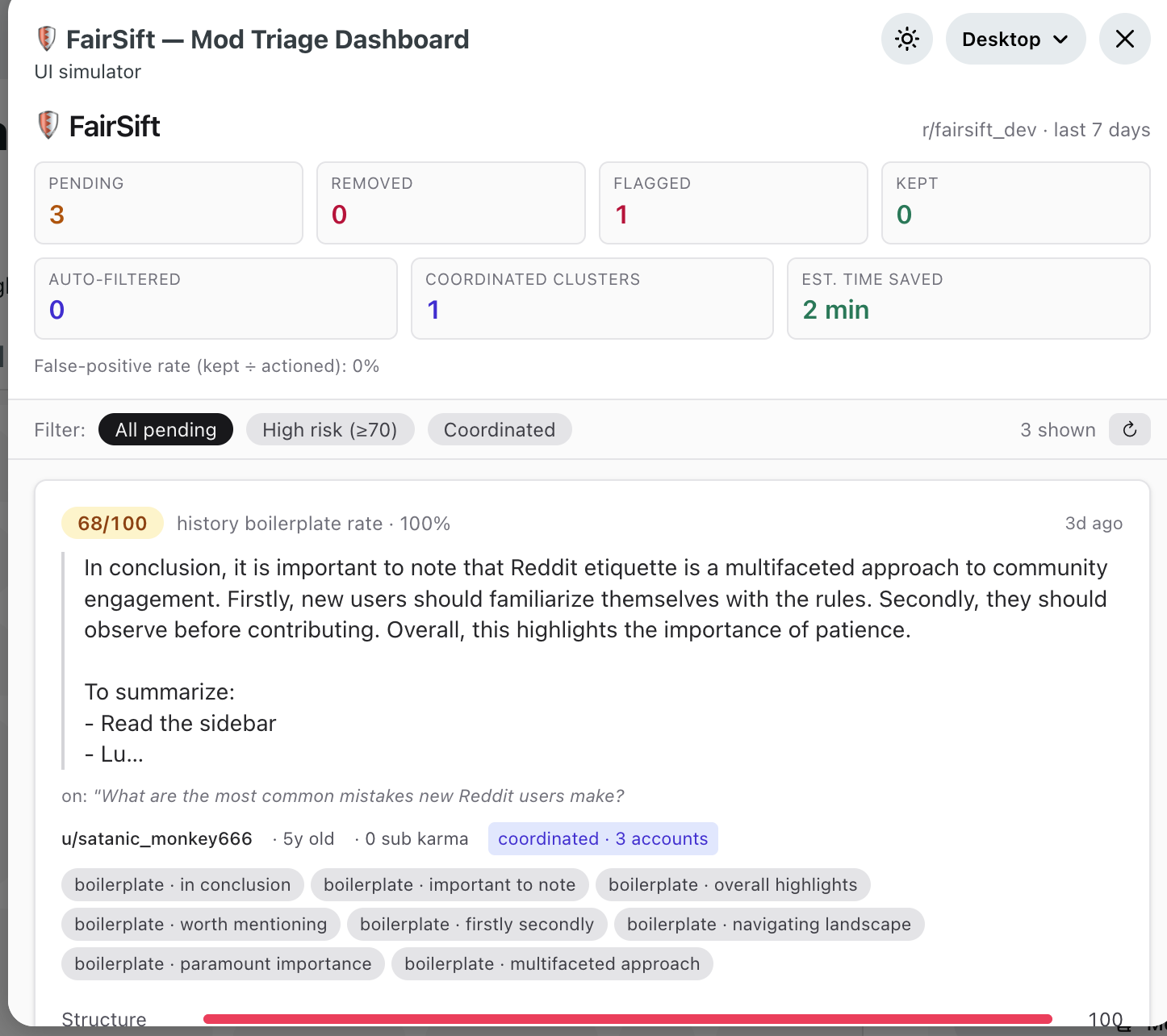
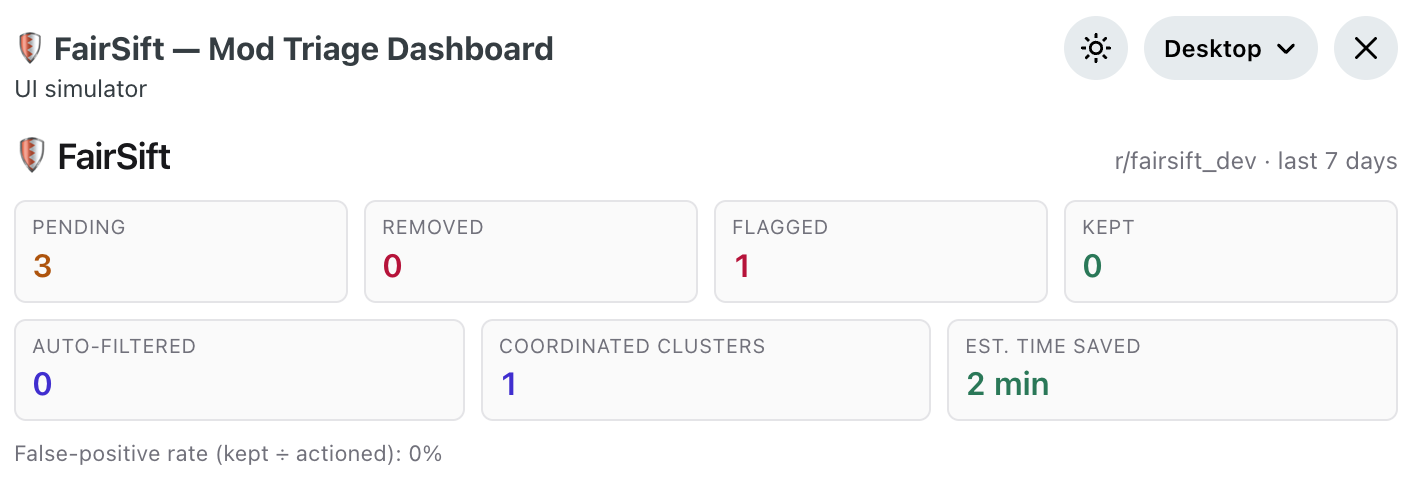
FairSift is a three-tier composite-scoring moderation tool that automatically evaluates every new comment in your subreddit and surfaces the highest-risk ones in a triage dashboard.
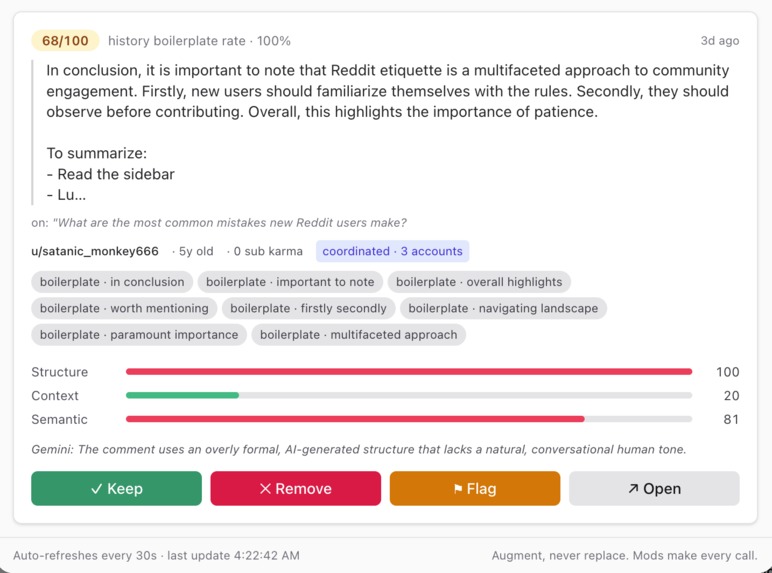
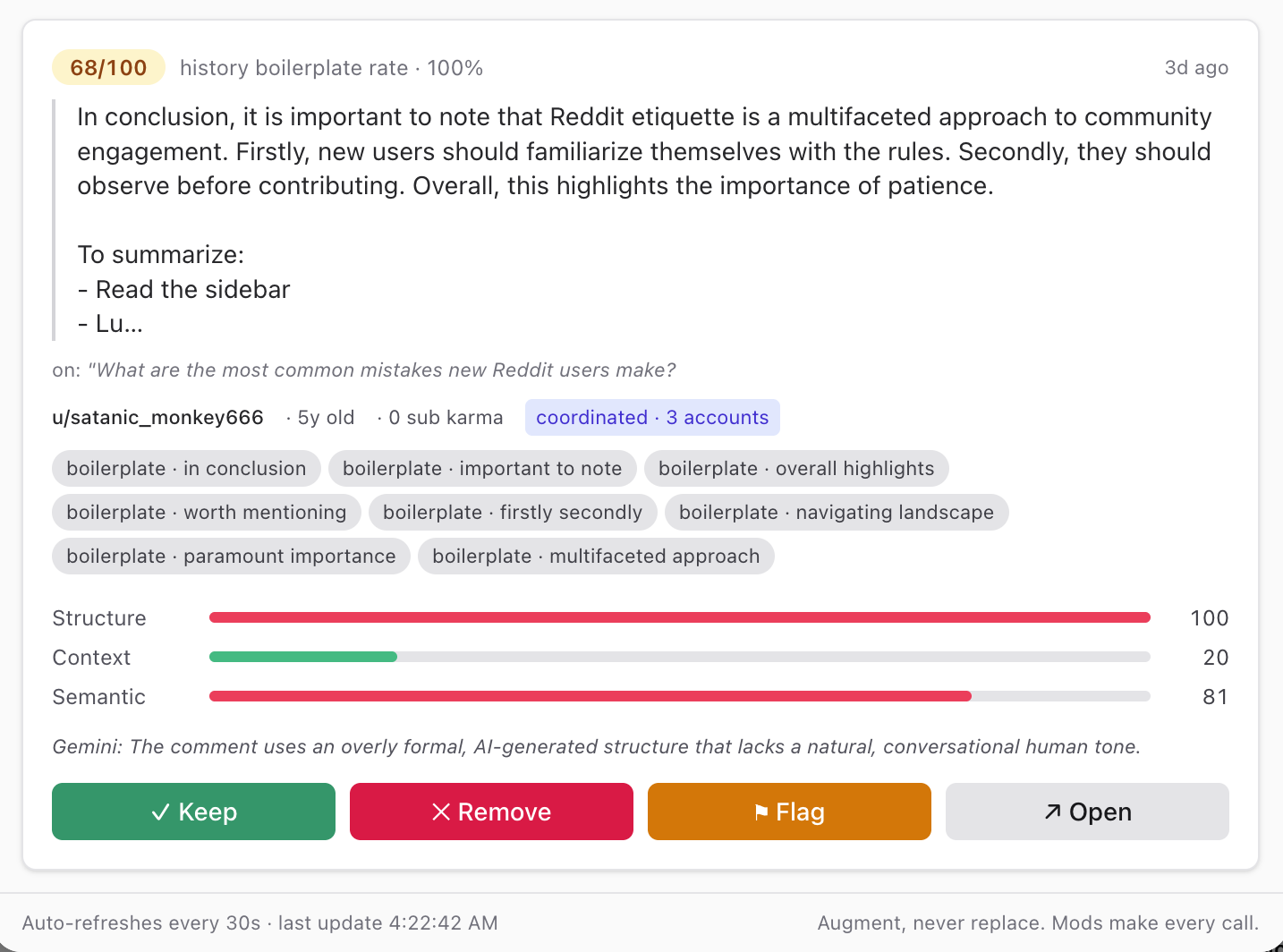
Tier 1 — Local heuristics (instant, zero cost): Structural fingerprints typical of low-effort AI output — list scaffolds, markdown section headers, em-dash clause stacks, boilerplate transition phrases, classic LLM openers ("As an AI…", "Here are key takeaways:"), generic Reddit advice, and a Redis-backed velocity check for users posting at inhuman speed.
Tier 2 — Account context (Reddit API only): Account age, site-wide karma, subreddit-scoped karma, and a fingerprint of the user's recent in-subreddit comment history — measuring length uniformity (low coefficient of variation = template-like output) and boilerplate hit rate across their last 25 comments. New accounts with any structural signal get a built-in escalation boost.
Tier 3 — Semantic review (Google Gemini, optional): A JSON-mode prompt to gemini-3.1-flash-lite that scores value-add (0–10) and tone organicism (0–10), plus a "summary-only" flag. Cached per comment for 10 minutes via Devvit's cache() helper to avoid duplicate billing.
The three scores are composited — weighted ( 0.45 \cdot T_1 + 0.20 \cdot T_2 + 0.35 \cdot T_3 ) — into a final 0–100 RiskScore. Comments above the mod-configurable escalation threshold land in a React triage dashboard with one-click Keep / Remove / Flag actions. Every decision writes a structured [FairSift] mod note for audit.
Beyond the core pipeline:
- Coordinated-attack detection — SHA-1 fingerprints of normalized comment bodies in a 1-hour Redis window. If 3+ accounts post the same body, all are force-escalated regardless of individual scores.
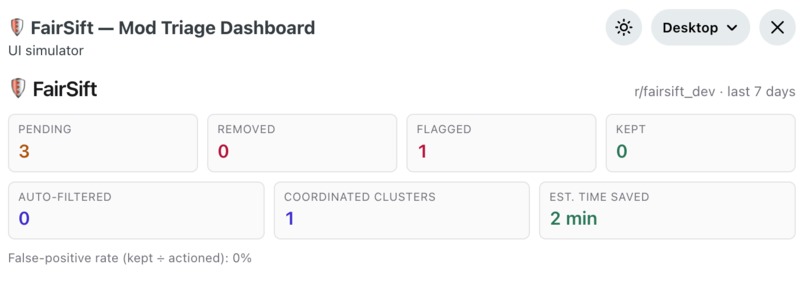
- Analytics header — 7-day rolling counts of queued/kept/removed/flagged, false-positive rate, coordinated clusters caught, and estimated mod-minutes saved.
- Auto-filter mode (off by default) — at a mod-set threshold the tool soft-removes to the Mod Queue while still surfacing it in triage.
- Compliance triggers —
onCommentDeleteandonPostDeleteimmediately scrub Redis to honor Devvit's user-data-deletion rules.
How we built it
The stack is entirely within Devvit's Web platform:
- Server: Hono router on
@devvit/web, handling triggers, menu actions, settings validation, and triage API routes. Every trigger handler is idempotent — a 10-minute Redisseen:{cid}key prevents duplicate scoring on Devvit's at-least-once delivery. - Pipeline: Pure TypeScript modules —
tier1-heuristics.ts,tier2-context.ts,tier3-semantic.ts,scorer.ts,fingerprint.ts,runner.ts— each independently testable with no cross-module side effects. - Client: React 19 + Tailwind v4 webview dashboard. Five components —
TriageDashboard,TriageCard,AnalyticsHeader,RiskBreakdown,ActionMatrix— with optimistic UI so the mod's queue updates instantly on action. - Storage: All in Devvit's per-install Redis namespace. Sorted-set triage queue (max 200 items, scored by risk), hash-per-day analytics, TTL-bounded velocity and fingerprint keys. Zero cross-subreddit data leakage.
- Build: Vite 8 + TypeScript 5.8 with separate
tsconfigper layer (client / server / shared), bundled to a singledist/server/index.cjsand a webviewdist/client/.
Challenges we ran into
Scoring calibration was the hardest problem. A naive uniform-weight average meant that a strong Tier 1 signal (obvious LLM boilerplate) could be diluted to below-threshold by a clean Tier 2 (old account, high karma). Real LLM-spam is often posted by established-looking accounts specifically to evade naive filters. We ended up with a hybrid: a weighted composite plus direct escalation overrides for cases where a single tier's evidence is strong enough on its own — for example, Tier 1 ≥ 75, or Tier 1 ≥ 45 with Gemini agreement ≥ 45, or any structural signal combined with a new/low-trust account.
The Devvit trigger delivery model is at-least-once, not exactly-once. Without the idempotency layer, every duplicate delivery would double-queue a comment and double-count analytics. The checkAndMarkSeen pattern with a 10-minute Redis TTL was essential.
Icon compression: Devvit enforces a 500 KB app icon limit. Our original PNG was 949 KB. We had to quantize it to a 128-color palette with dithering to get it under the limit without visible quality loss.
App slug length: Devvit app slugs are limited to 16 characters. Our original name "authenticity-firewall" (21 chars) had to be rethought entirely — leading to the cleaner brand name "FairSift."
Accomplishments that we're proud of
- A pipeline that actually catches what existing tools miss. Section headers in comments, numbered-list scaffolds, repeated em-dash clauses, "here are key takeaways:" intros — patterns that are invisible to keyword filters but obvious to a human mod — now surface automatically.
- Zero auto-bans, by design. The tool's philosophy is enforced at the architecture level. There is no code path that bans, restricts, or distinguishes a user without a mod clicking a button.
- New-account deterrence without false-positiving established users. The escalation formula ( T_1 \geq 10 \;\land\; T_2 \geq 30 ) means a brand-new account with even one mild structural signal surfaces for review — while the same comment from a 5-year-old account with high sub karma quietly passes.
- Full compliance surface. Deletion triggers, explicit TTLs on every Redis key, mod-only server-side checks on every API route, and a documented Privacy Policy and Terms of Service — not afterthoughts.
- Coordinated-attack detection for free. The fingerprinting system costs one Redis SADD per comment and catches copy-paste brigading that individual scoring would miss entirely.
What we learned
Moderation tooling requires a fundamentally different scoring philosophy than spam detection. Spam filters optimize for precision — a false positive gets a human unfairly banned. Moderation triage tools should optimize for recall — a false negative means a mod never sees something they should have reviewed. Getting the weighting and escalation logic to reflect that difference took multiple calibration passes.
We also learned that Devvit's cache() helper is genuinely powerful for keeping external API costs manageable. Wrapping the Gemini call in a 10-minute per-comment cache means repeated mod opens of the same triage card cost nothing, and a burst of 50 comments referencing the same viral post only bills the API once per unique body.
What's next for FairSift
- Mod feedback loop: After 100+ Keep/Remove decisions, surface threshold recommendations — "your current settings yield a 23% false-positive rate; try
tier1Threshold=12for better balance." - Decision-derived patterns: When a mod removes a card, extract its dominant text features and offer to add them to
customBoilerplatePatternswith one click. - Daily mod-modmail digest: A scheduled 9 AM summary of the prior 24 hours — queued, actioned, clusters caught.
- Cross-subreddit opt-in network: If multiple installs see the same fingerprint within an hour, flag it as a network-level coordinated attack across communities.
Filter()integration: Offer "send to ModQueue with AI reasoning" as a softer middle tier between Keep and Remove, for mods who want a safety net rather than an immediate action.
Built With
- devvit
- typescript
- vite

Log in or sign up for Devpost to join the conversation.