-
-

saved response view
-

uploaded files view
-
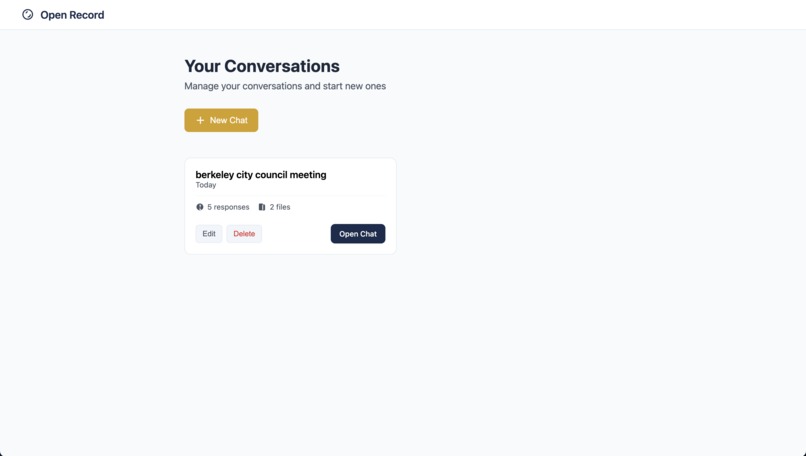
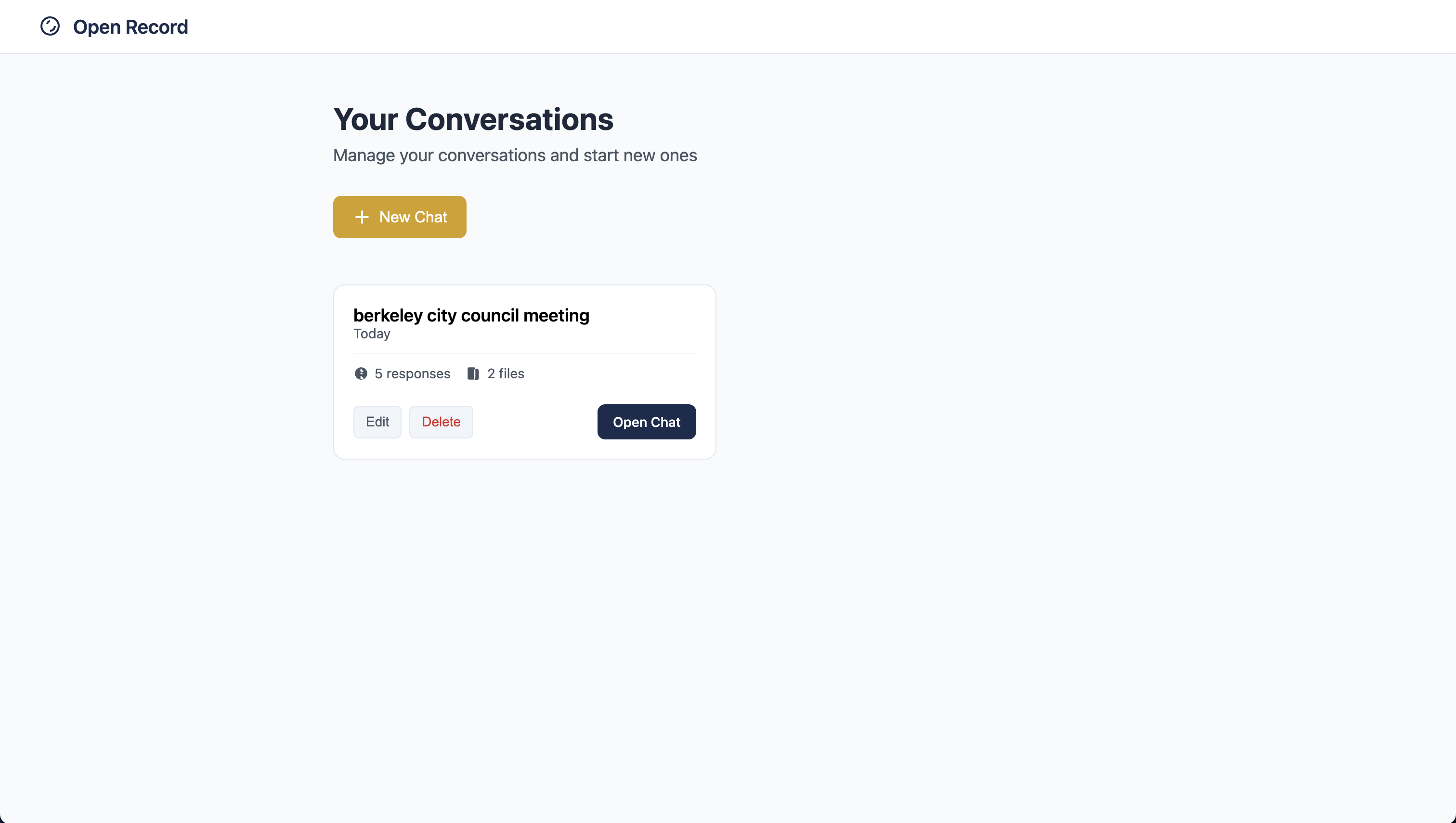
dashboard view


Inspiration
Open Record was inspired by the growing crisis in local journalism. While national outlets continue to expand, smaller newspapers and student-run publications are shutting down or burning out—struggling to keep up with the overwhelming volume of public information they’re expected to monitor. Since 2005, over 2,500 local newspapers in the U.S. have closed. One of the biggest bottlenecks is the time and effort required to review and analyze public meeting recordings, budget documents, and long transcripts. We wanted to build a tool that not only helps journalists read and summarize content—but actually helps them uncover the stories that matter.
What it does
Open Record is more than just a chatbot; it’s a proactive research assistant designed specifically for local journalists. Users can upload audio or video files, such as city council meetings, select one or more recordings, and ask complex questions. The system can summarize discussions, identify key issues, pull direct quotes with timestamps, and even analyze trends across multiple meetings. Journalists can also save important chatbot messages for easy reference. But Open Record goes beyond reactive Q&A: it’s a system that finds the questions worth asking. Instead of spending hours combing through transcripts, journalists are handed the most relevant insights automatically.
How we built it
We used the Groq Whisper API to transcribe city council recordings with high accuracy and speaker diarization. These transcripts were then segmented and embedded using Google Cloud’s Vertex AI Embeddings API. We stored those embeddings in Supabase, which served as our vector database for efficient retrieval. User queries are handled through a Retrieval-Augmented Generation (RAG) system powered by Anthropic’s Claude 3, which generates contextual answers grounded in the retrieved transcript chunks. This full-stack pipeline allows for fast, accurate, and traceable responses across large civic datasets.
Challenges we ran into
We encountered several technical challenges throughout development. One major hurdle was orchestrating a seamless workflow across multiple services: transcription, vector embedding, storage, and LLM querying all had to be coordinated carefully to function as a unified system. We also ran into difficulties with prompt engineering—specifically, how to guide Claude 3 to stay grounded in the retrieved transcript data. We had to experiment with different chunking strategies to balance semantic accuracy with latency and cost, especially when working with long, multi-speaker transcripts. Finally, ensuring speaker attribution remained accurate through diarization and preprocessing was a nuanced problem that required fine-tuning.
Accomplishments that we're proud of
We’re proud to have built a fully functional, end-to-end RAG system capable of operating across multiple long-form documents and audio files. Open Record handles messy, real-world civic content and delivers structured, journalist-ready insights. Along the way, we gained experience working with cutting-edge tools like Groq, Claude, Supabase, and Vertex AI—all while solving a problem with real social impact.
What we learned
Building Open Record gave us a deep, hands-on understanding of Retrieval-Augmented Generation systems—from embedding generation and vector storage to prompt tuning and output evaluation. We learned how to preprocess and clean noisy, multi-speaker data for better semantic results. We explored the trade-offs between chunk size, latency, and answer quality in a RAG pipeline. Most importantly, we learned how to design an AI system not just for accuracy, but for usefulness—delivering insights that real people, like student journalists, can act on.
What's next for Open Record
Next, we plan to integrate semantic search so users can explore all their previously uploaded files by topic. We also hope to incorporate Google Document AI to analyze structured documents like city budgets, giving users an even broader view of public decision-making. Ultimately, our vision is to build a fully automated pipeline that ingests new public meeting data overnight and delivers a tailored morning briefing—helping local journalists cover more ground with less effort, and empowering communities to hold their governments accountable.
Built With
- claude
- fastapi
- gcp
- groq
- supabase

Log in or sign up for Devpost to join the conversation.