-
-

Our team is a blend of social & business and top technical skills.
-
One-slider for the pitch

Video trailer on FAIRLY: https://vimeo.com/1178985436?share=copy&fl=sv&fe=ci Landing Page https://fairlygenaizurich.lovable.app/ One-Slider link
Inspiration
Imagine the compliance officer of an advertising company has to provide a proof that the VLM model that they use is not misleading and unbiased.
Current models frequently exhibit "associative shortcuts" that can have damaging real-world consequences.
Even when companies attempt to be responsible, most internal audits are performed in a vacuum. There is a critical lack of methodological documentation. Without a standardized record of how an audit was conducted - which prompts were used, which hierarchies were tested, and how "fairness" was quantified - it is impossible to show progress
Currently, a comprehensive bias audit is a luxury good. It requires a massive, costly investment in external consultants and bespoke forensic auditors. This creates a "Fairness Gap" where only the largest corporations can afford to be compliant.
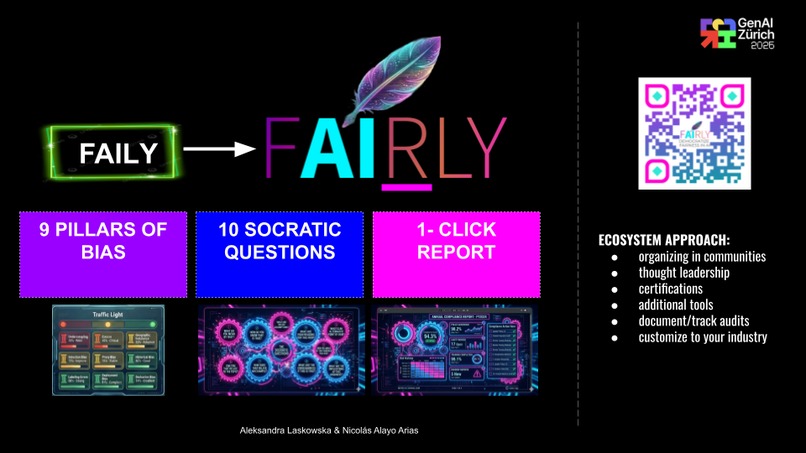
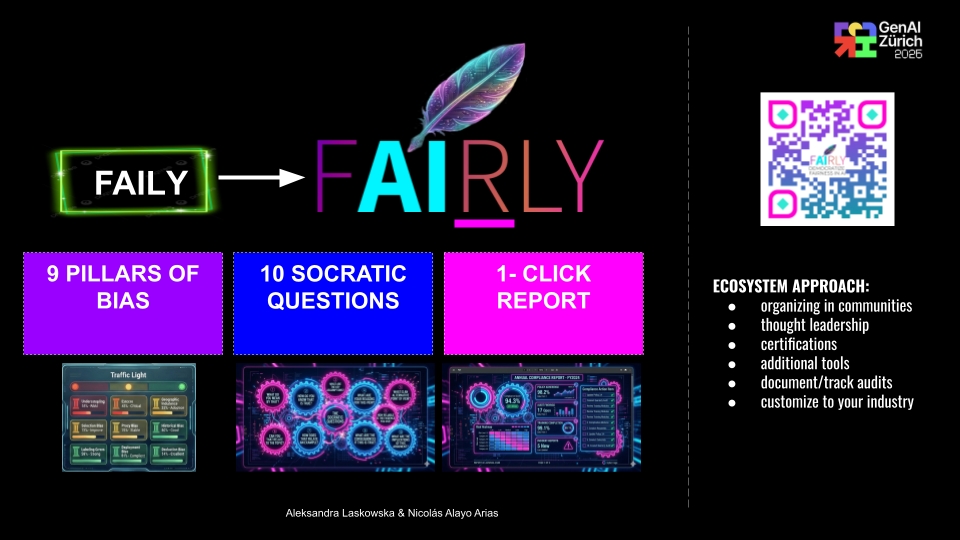
FAIRLY is a commitment to transforming AI from a black box of inherited prejudice into a transparent tool for objective evaluation. And by making it easier - democratizing fairness. But it is more then just a platform. ** IT IS AN ECOSYSTEM** of social scientists, policy makers, ML architects to make sure that the bias is detected and managed in existing and ongoing VLMs.
What it does
FAIRLY provides companies with a clean, equitable, and fair benchmark library designed to audit these hidden biases.
- The tool uses the FHIBE hierarchical architecture to perform a deep-tissue scan of the model.
- FARILY evaluates whether the model relies on memorized stereotypes rather than actual visual evidence.
- It aims to provide companies with a clean, equitable benchmark that translates ethical data into "Fairly Report.pdf" - document ready for assurance.
- "Benchmark Constructor": not all bias is equal in every context. Our "Toggle System" allows users to create context-relevant evaluations (e.g., prioritizing "Age Robustness" for a pension fund ad campaign) to ensure the audit fits the industry.
- Audit Version Control - we treat fairness as a journey, not a destination. By documenting and archiving past audits, companies can use historical data as a benchmark for progress.
How we built it
The Diagnostic Framework: to move from theory to technical execution, we decomposed the abstract concept of "bias" into 9 distinct, measurable dimensions. Each dimension is mapped directly to the FHIBE hierarchical labels and operationalized through a "Socratic" battery of 10 targeted questions per bias type: Undersampling, Label Noise, Geographic Imbalance, Style Invariance, Environmental Sensitivity, Pose Robustness, Occupational Defaulting, Contextual Harms, Erasure.
We don't just ask the model "is this biased?" We probe it using a mix of data outputs to capture the full spectrum of its "reasoning":
-Dichotomous (Yes/No): For clear-cut presence or erasure. -Likert Scales: To measure the strength of an association. -Integers/Floats: To extract raw confidence scores and probability distributions.
The Technical Framework: Inspired by MLflow’s approach to machine learning lifecycle management, we built FAIRLY as an end-to-end bias evaluation toolkit. The architecture consists of a Python/FastAPI backend and a React (shadcn/ui) frontend, utilizing a local SQLite database to ensure corporate data privacy. We engineered a 'Bring Your Own Model' integration, allowing seamless connections to custom APIs (like OpenAI or Claude) or open-source models via Featherless.ai. The core engine dynamically crosses dataset metadata (using the FHIBE dataset) with targeted prompt templates to run automated, stratified inferences, storing all artifacts locally for compliance tracking.
Challenges we ran into
Challenge 1: Quantifying the "Wicked Problem": The most significant hurdle was operationalizing bias. It isn't a single indicator; it’s a shifting vector of several variables that pulsate and reshape as models continue to learn and reinforce their own patterns on the go.
Challenge 2: The Nuance of "Neutrality": Defining what a "unbiased" baseline looks like in a world with historical systemic skews was a constant philosophical and technical tension.
Accomplishments that we're proud of
The Fusion of Perspectives: We successfully bridged the gap between the Social Scientist and the Machine Learning Engineer.
By uniting these roles, we ensured the tool isn't just a collection of cold code, but a mirror of social reality. We are inspired by how essential this cross-disciplinary dialogue is; it proved that to "unite for good," we must first speak the same language of ethics and tensors.
What we learned
The Multi-Metric Reality: We realized that bias is too complex for a single "score." It requires a multidimensional approach to capture the nuance of human identity.
A Process, Not a Person: We discovered that our customer isn't a specific job title, but a corporate process. From legal to R&D, anyone aiming for data compliance and ethical integrity is a stakeholder.
What's next for FAIRLY
Industry-Specific Narratives: We plan to expand our "Customer Stories" beyond Advertising into high-stakes sectors like Healthcare diagnostics, Criminology, and HR Hiring to prevent automated discrimination.
Socratic Adaptive Learning: We will implement a "Customizable Bias Temperature" setting. Using a Socratic method, the platform will ask the model (and the user) probing questions, allowing the system to learn and refine its detectors based on user approval or rejection.
Rolling Audits - installing the ability to check the progress of the bias in models at specific cadence.
Audit Version Control - we treat fairness as a journey, not a destination. By documenting and archiving past audits, companies can use historical data as a benchmark for progress.
Regulatory Box-Ticking - compliance/regulatory checklists adjusted to EU AI ACT, Brazilian Bill No. 2338/2023, South Korea's Basic AI Act.
Built With
- fastapi
- python
- react
- sqlite
- typescript





Log in or sign up for Devpost to join the conversation.