-
-

thumbnail
-
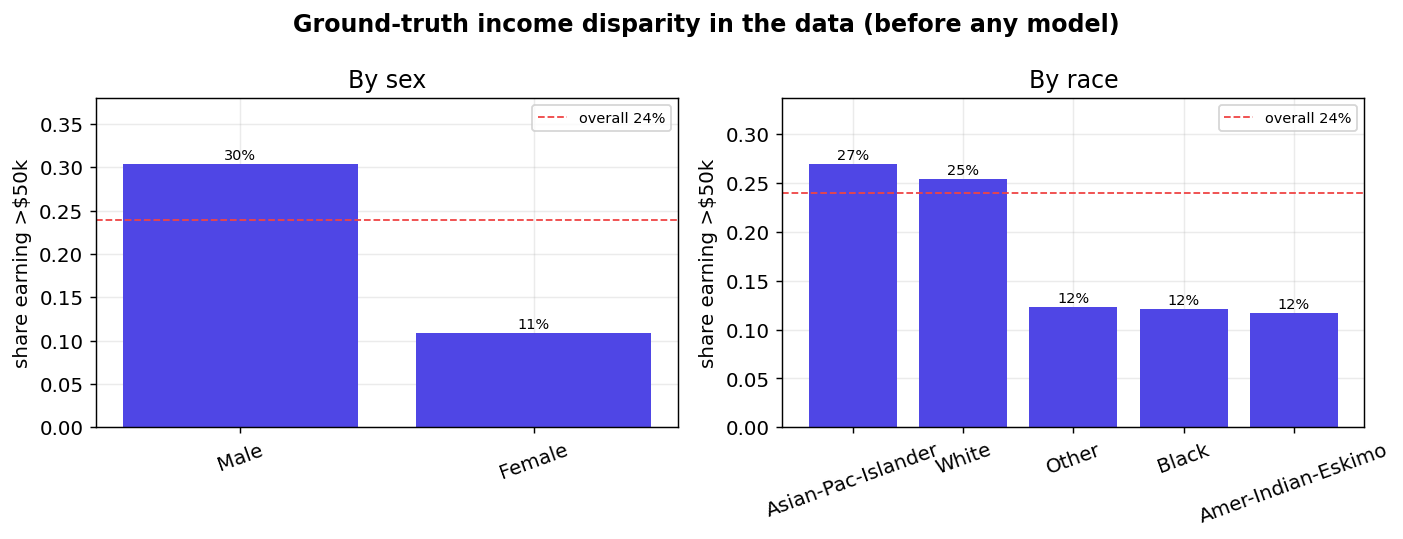
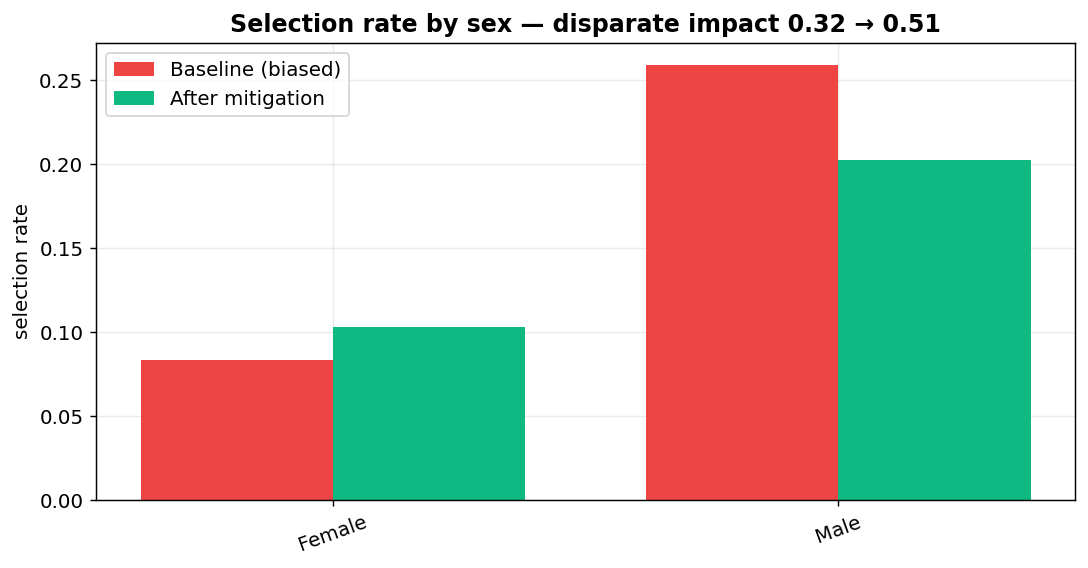
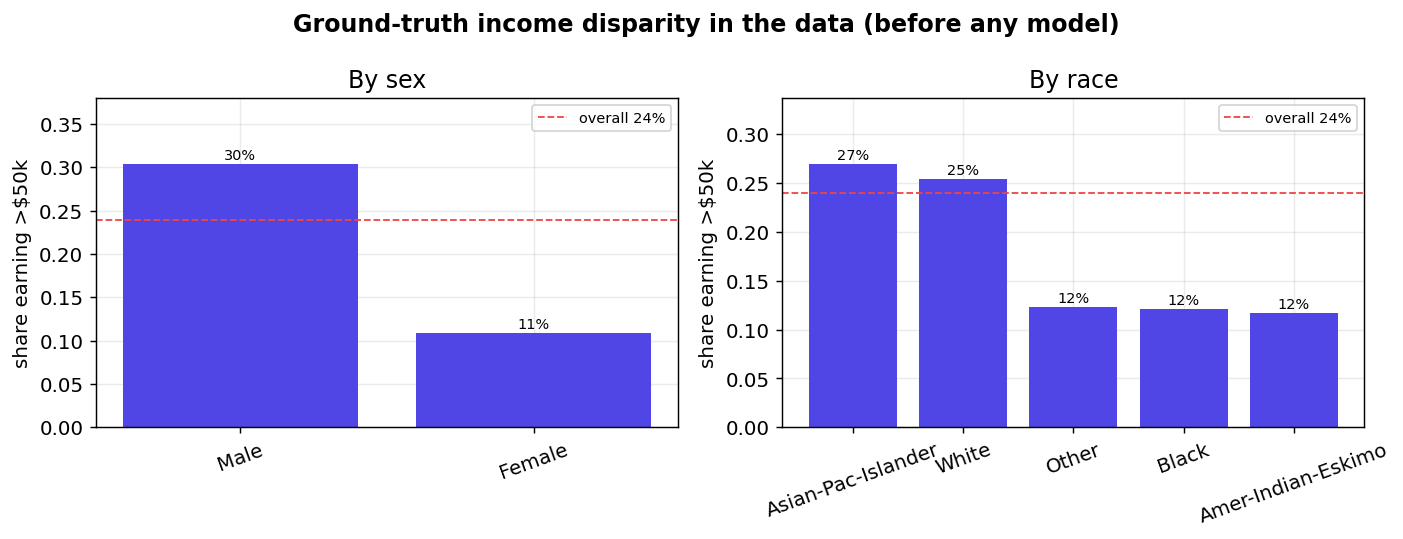
fig_before_after_sex
-
fig_base_rates
-
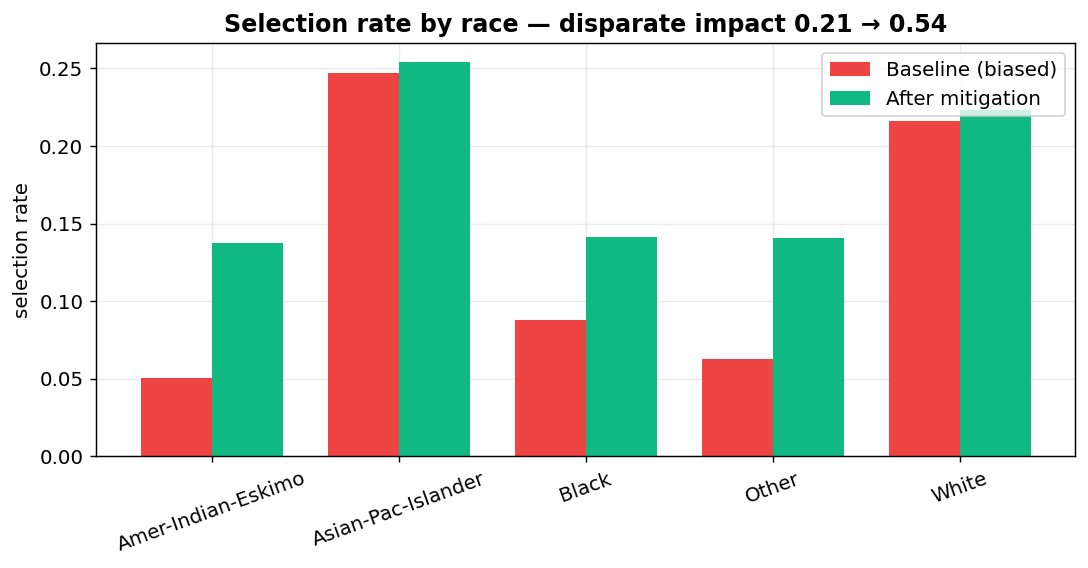
fig_before_after_race

Inspiration
Machine-learning models increasingly decide who gets a loan, an interview, or a benefit — and they're judged on a single number: accuracy. But a model can be highly accurate and still systematically deny opportunities to women or to a racial group. The harm is invisible in the headline metric, so nobody notices. We wanted to make that invisible harm visible, measurable, and fixable — for anyone, not just ML researchers.
What it does
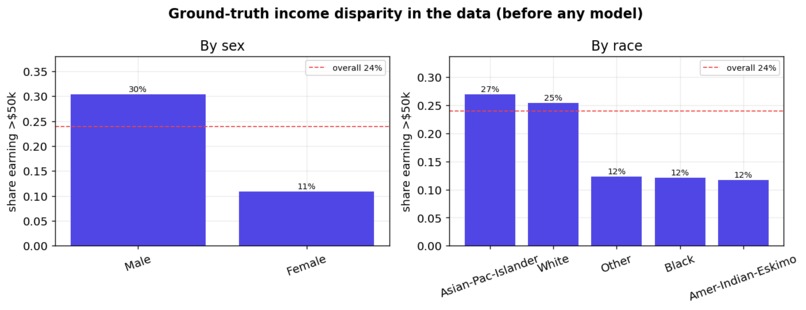
FairLens audits a real income classifier trained on the UCI Adult / Census Income dataset (48,842 people). It:
- trains a strong gradient-boosting model (87.6% accuracy, 0.93 ROC-AUC);
- audits it for bias by sex and race using legally-grounded fairness metrics (the U.S. EEOC four-fifths rule and equalized odds);
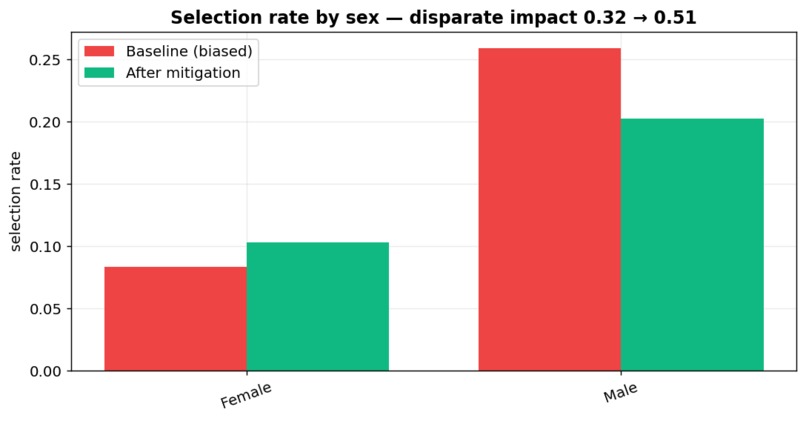
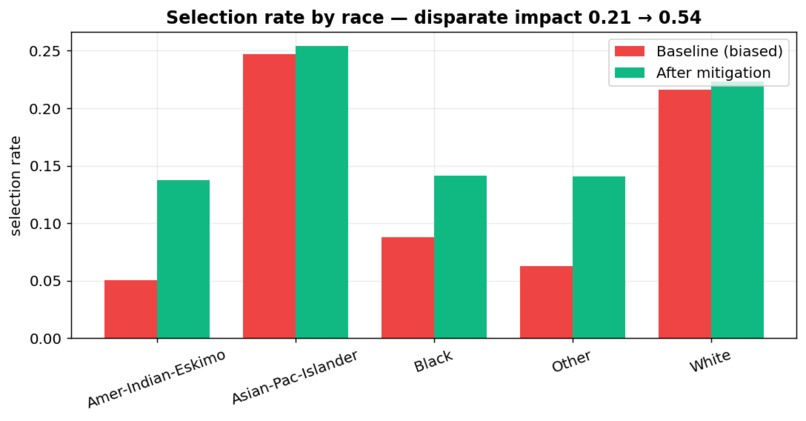
- shows it fails the four-fifths rule badly — a disparate-impact ratio of 0.32 by sex and 0.21 by race (anything under 0.80 is legal "adverse impact");
- applies a mitigation that closes most of the gap for ~1 accuracy point;
- wraps it in an interactive dashboard where you slide the decision threshold and toggle the fix to watch fairness change in real time.
How we built it
- Data cleaning (pandas): normalized three different spellings of "missing," recovered 3,620 hidden missing values, mode-imputed, and dropped a leak column (
fnlwgt) and a redundant one (education). - Modeling (scikit-learn):
HistGradientBoostingClassifieron one-hot-encoded features, 70/30 stratified split. - Fairness audit (Fairlearn): per-group selection / true-positive / false-positive rates, disparate-impact ratio, and equalized-odds difference.
- Mitigation (Fairlearn
ThresholdOptimizer): group-aware thresholds for equalized odds — no retraining required. - Dashboard (Streamlit + Plotly): live threshold slider, attribute selector, and a before/after comparison that shows the exact accuracy cost of fairness.
A fully-executed Jupyter notebook documents the entire data-science narrative.
Challenges we ran into
The sneakiest bug was in cleaning: calling .str.strip() before handling nulls silently turned every NaN into the literal string 'nan', hiding 3,620 missing values and making the data look clean when it wasn't — a good reminder that data-ethics work starts with honest data. Deployment surfaced another: the host provisioned Python 3.14, which had no prebuilt wheels for our pinned libraries, so we loosened them to wheel-available releases.
Accomplishments that we're proud of
Turning an abstract "AI ethics" concern into concrete, defensible numbers tied to actual U.S. anti-discrimination law (the four-fifths rule) — and shipping it as a tool a non-expert can actually operate.
What we learned
- Accuracy and fairness are independent; you have to measure fairness on purpose.
- "Fairness through unawareness" (just dropping sex/race) fails, because proxies like
relationshipandmarital-statusre-encode the protected attribute. - There is no single definition of fairness — the honest move is to show the trade-off, not hide it.
What's next for FairLens
Upload-your-own-CSV auditing, more mitigation methods (reweighing, exponentiated gradient), and an exportable PDF "fairness report" for compliance teams.
Built With
- fairlearn
- jupyter
- matplotlib
- pandas
- plotly
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.