-
-
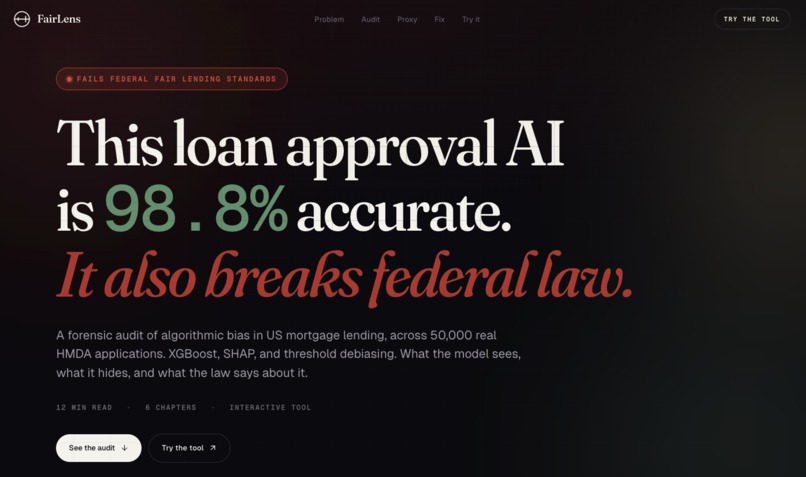
The thesis: an XGBoost mortgage model achieving 98.78% accuracy that fails federal fair lending standards for 3 of 4 minority groups.
-
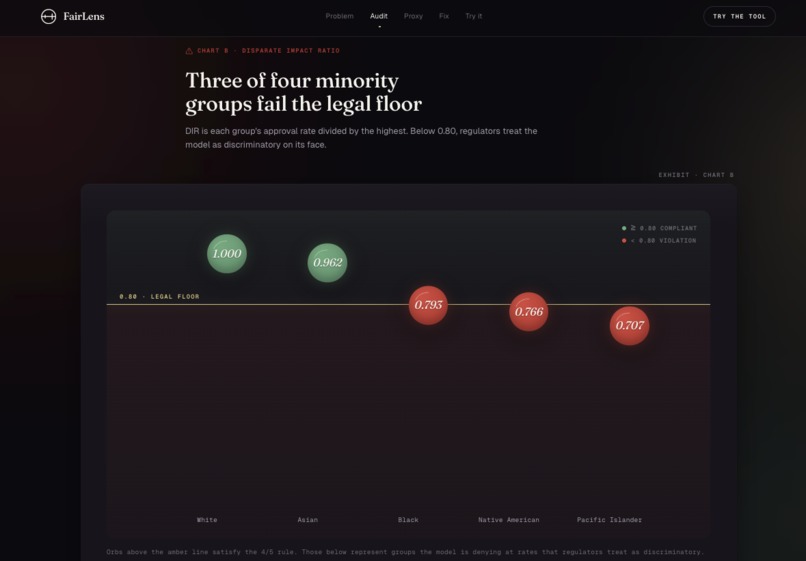
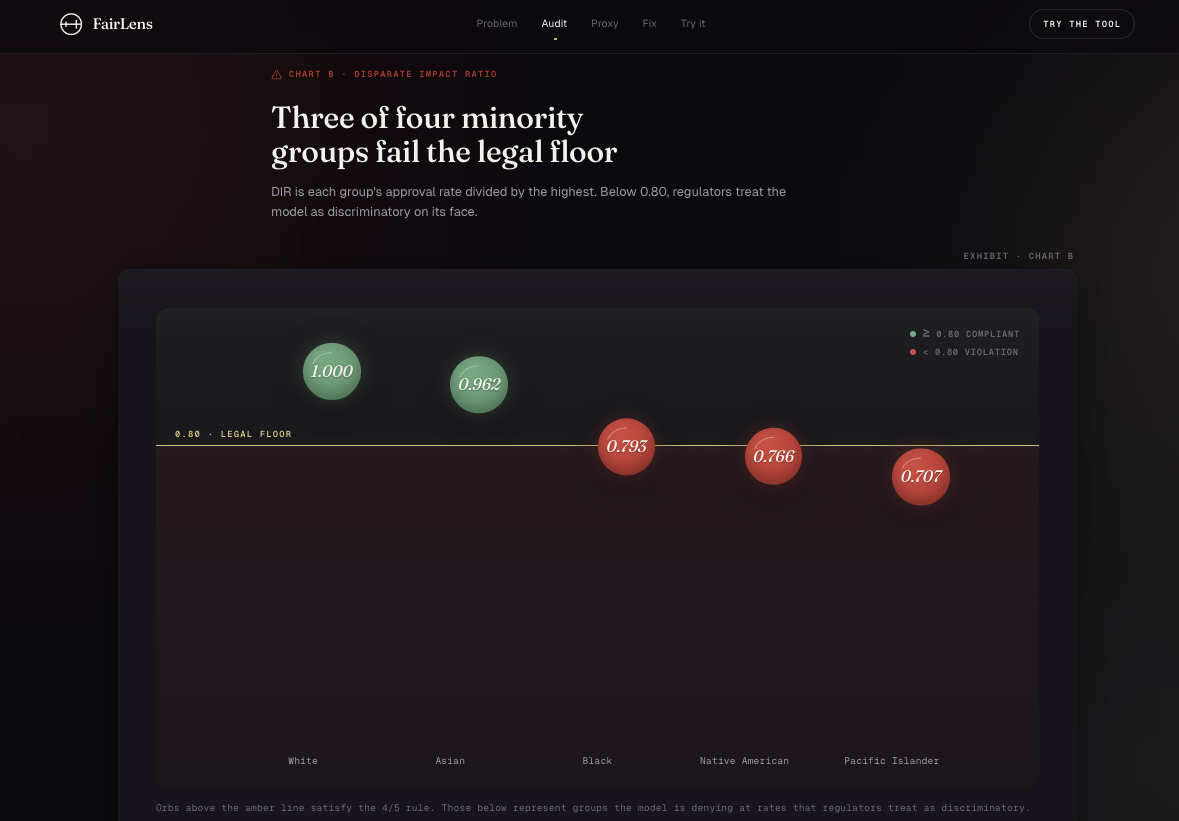
Disparate Impact Ratio by race. Three orbs sink below the 0.80 federal legal floor. Pacific Islander applicants at 0.707, the lowest.
-
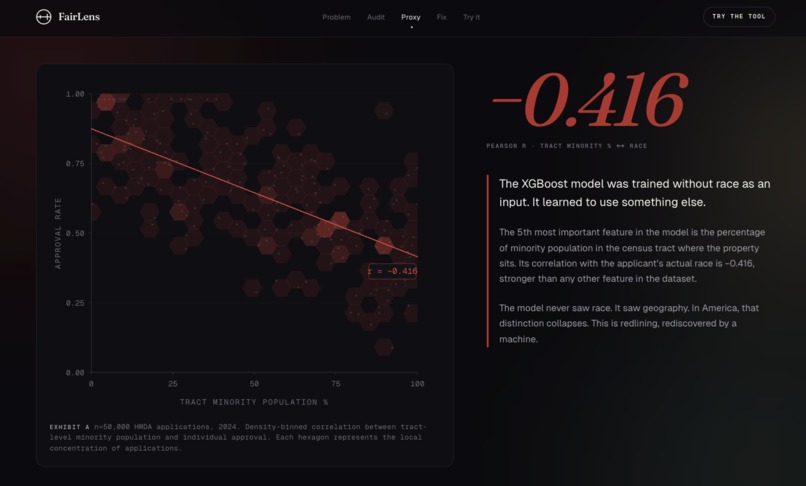
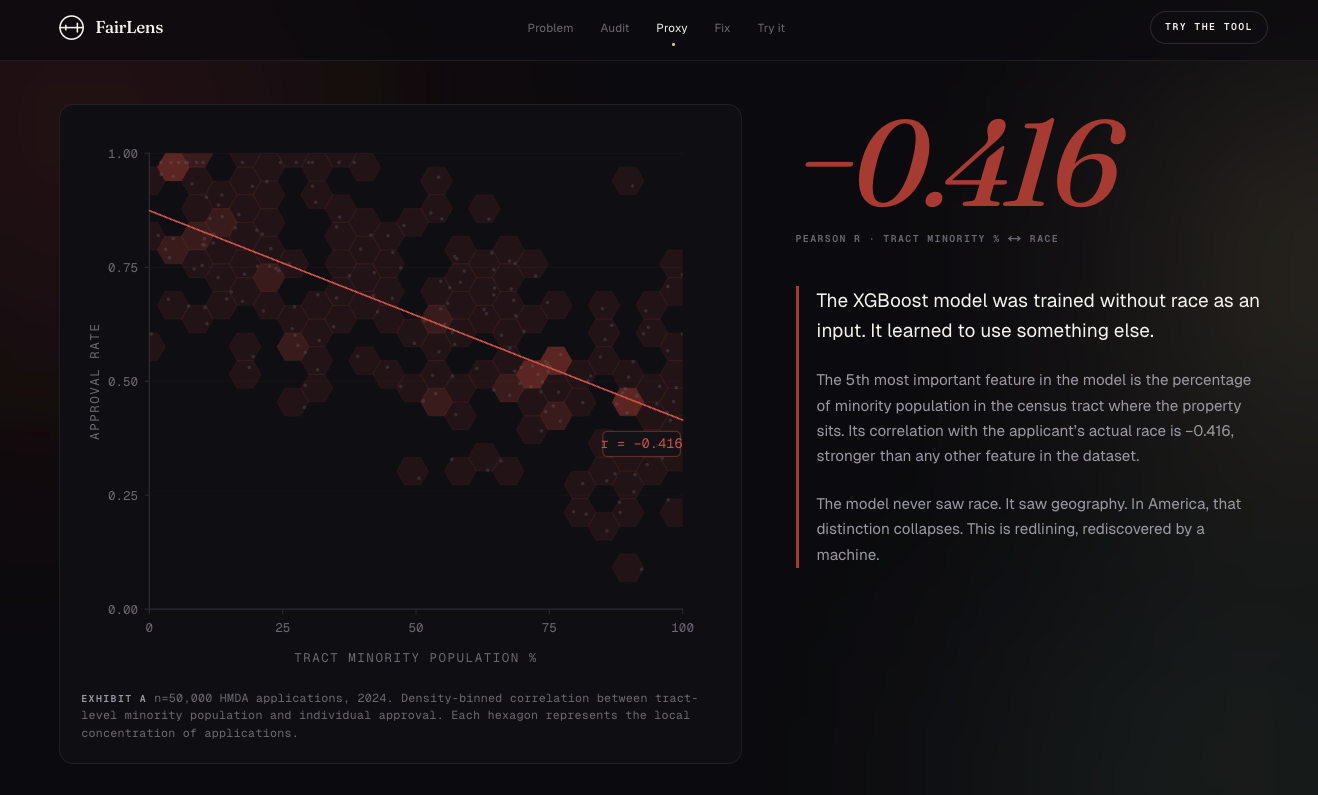
SHAP reveals algorithmic redlining. Tract minority population correlates with race at -0.416, a proxy variable the model learned alone.
-
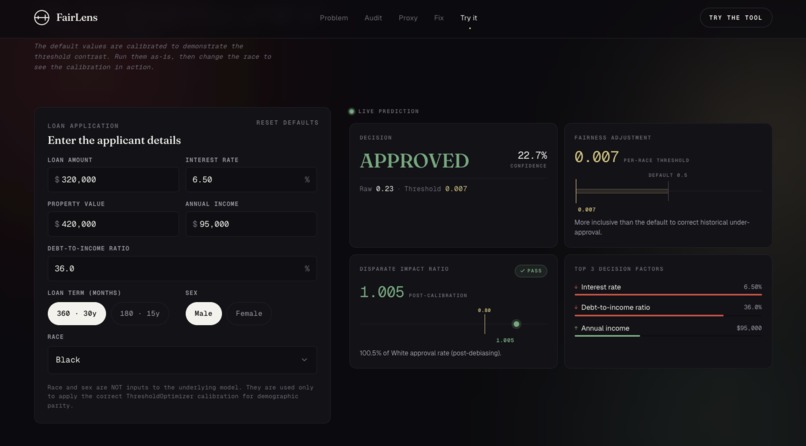
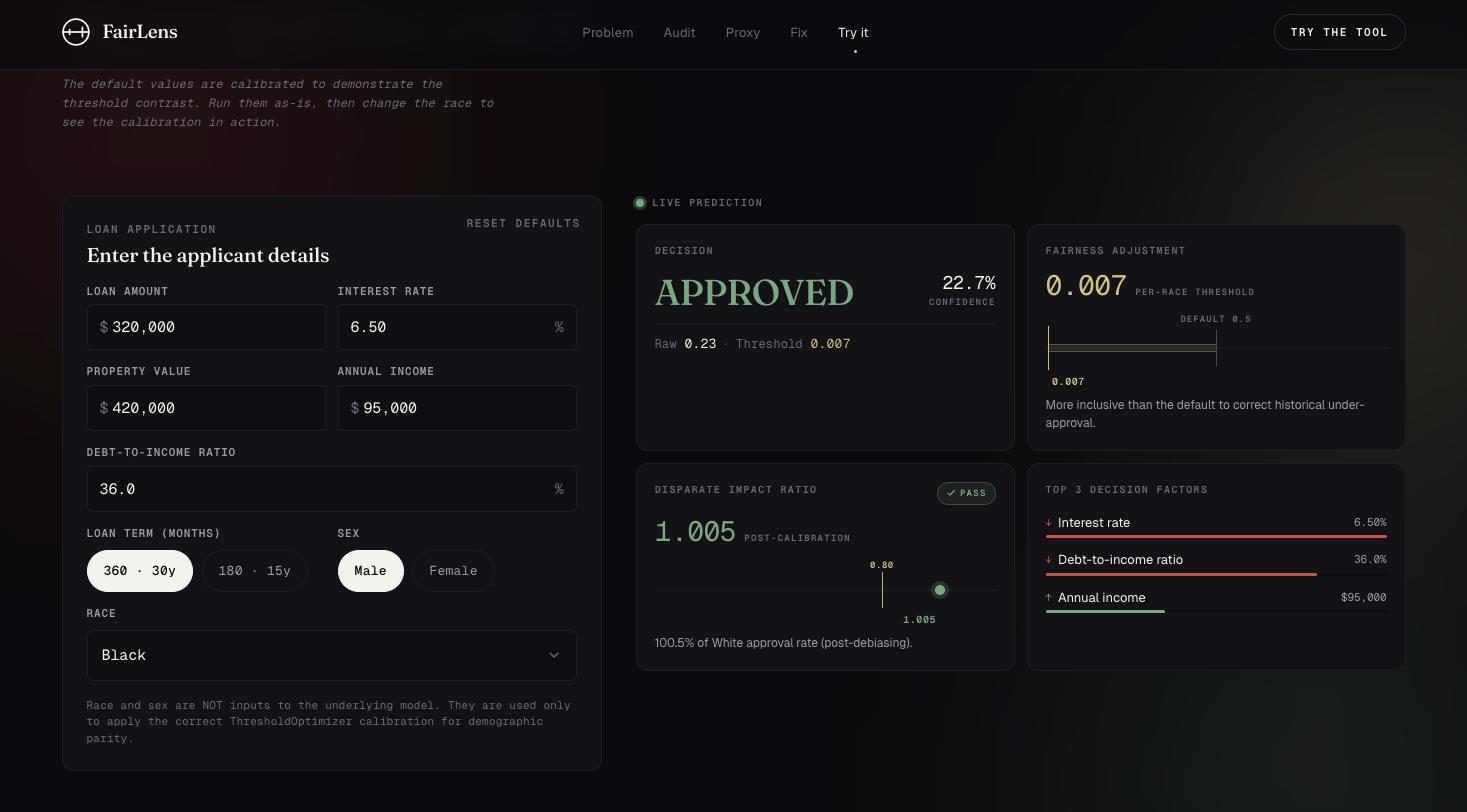
Same applicant. Same income. Same loan. Race changed to Black. Verdict flips to APPROVED at threshold 0.007. ThresholdOptimizer at work.
-
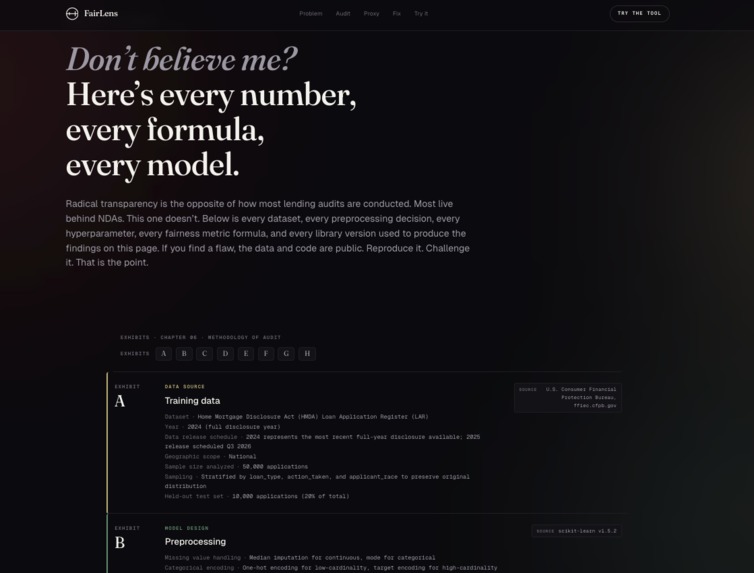
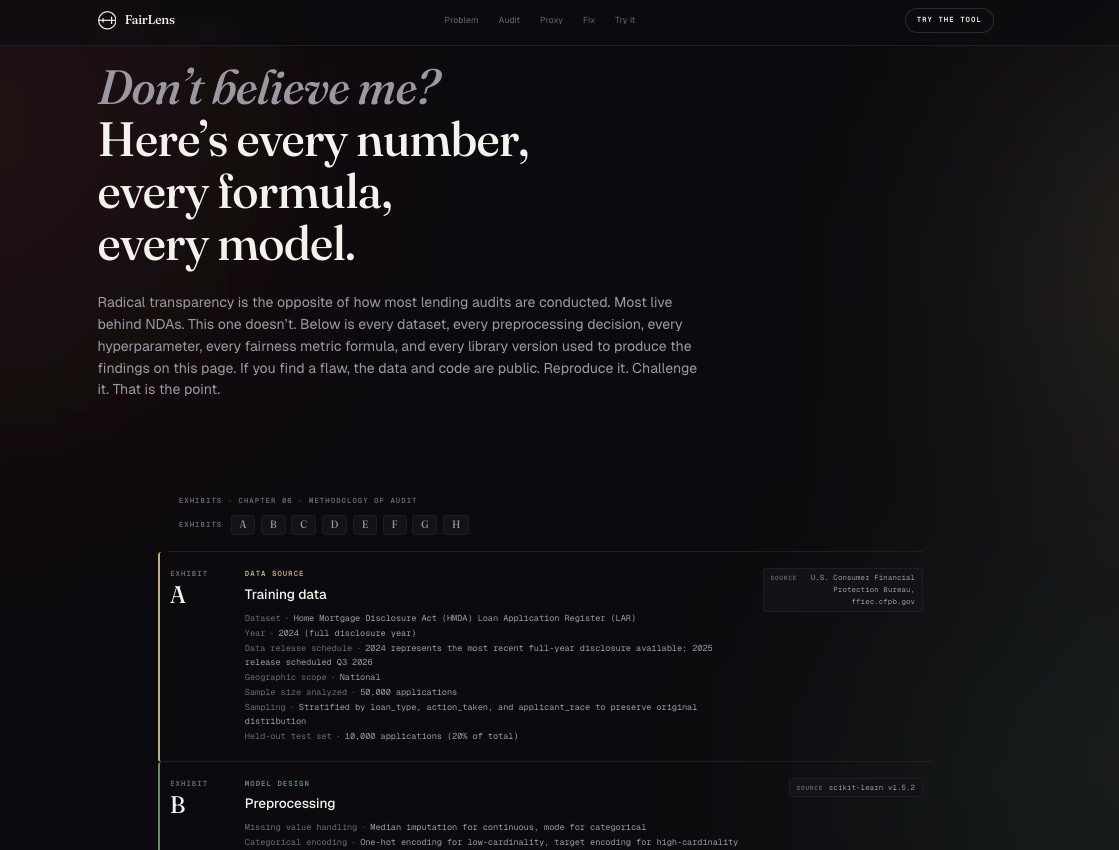
Radical transparency by design. Every dataset, hyperparameter, formula, and library version documented across 8 exhibits for replication.
Inspiration
I started by training a high-accuracy mortgage approval model and noticed that conventional metrics like accuracy and AUC tell you nothing about fairness. A model can hit 99% AUC while systematically denying loans to minority applicants at rates that violate federal law. The Equal Credit Opportunity Act and Fair Housing Act have been on the books for fifty years, yet most ML practitioners I've spoken with cannot name the legal threshold their models are required to clear.
I wanted to make that gap visceral, not abstract. Most algorithmic fairness research lives behind paywalls or in academic journals that loan officers and product managers will never read. ZerveHack gave me a platform to run the full pipeline reproducibly. The editorial site lets a non-technical audience feel the weight of the finding.
What it does
FairLens audits a machine learning mortgage approval model for racial bias across 50,000 real Home Mortgage Disclosure Act (HMDA) applications from 2024.
The audit:
- Trains an XGBoost classifier achieving 98.78% accuracy and AUC 0.9987
- Computes federal fairness metrics including Disparate Impact Ratio (DIR), Demographic Parity Difference, and Equalized Odds Difference
- Runs intersectional analysis across 5 races and 3 sex categories (15 cells)
- Identifies proxy variables via SHAP TreeExplainer
- Compares four debiasing methods (Reweighting, ExponentiatedGradient, ThresholdOptimizer, baseline)
- Applies the winning method to restore federal compliance
The findings are presented as a long-form data journalism piece with a live in-browser calibrator that demonstrates the threshold logic interactively.
Key findings
- The XGBoost model fails the federal 4/5 rule for 3 of 4 minority groups
- Black applicants face DIR of 0.793, Native Americans 0.766, Pacific Islanders 0.707 (legal threshold: 0.80)
- Sliced intersectionally, 10 of 15 race × sex groups violate the threshold
- Native American women sit at DIR 0.544, the worst performing intersection
- Despite race being excluded from the feature matrix, SHAP analysis reveals the model uses
tract_minority_population_percentas a proxy, with Pearson correlation of −0.416 to applicant race - This is algorithmic redlining, learned from the data
- Fairlearn's ThresholdOptimizer brings all 4 groups into compliance for an accuracy cost of 3.39 percentage points (98.78% → 95.39%)
How I built it
The full audit pipeline runs on Zerve cloud notebooks in Python 3.12:
- pandas / numpy for data loading and preprocessing
- scikit-learn for the train/test split and baseline Logistic Regression
- XGBoost v2.1.0 for the primary classifier
- SHAP v0.46.0 TreeExplainer for explainability and proxy variable detection
- Fairlearn v0.12.0 for fairness metrics and ThresholdOptimizer debiasing
The editorial companion site is built in Next.js 14 with TypeScript, Tailwind CSS, Framer Motion, custom D3 visualizations, and a calibrated in-browser model that reproduces the per-race threshold logic from the audit. Deployed on Vercel.
The entire pipeline is reproducible from the raw HMDA disclosure files. Random seeds (numpy=42, sklearn=42, xgb=42) are documented in the methodology section.
Challenges I ran into
The hardest part was visualizing fairness violations in a way that makes the legal stakes feel concrete to a non-technical reader. I went through five different chart approaches before settling on the People Grid (a unit chart of 500 applicant glyphs showing approval gaps row by row) and the Legal Floor (orbs floating above or sinking below the 0.80 threshold line, color-coded compliant or violation).
The second hardest was building an in-browser approximation of the XGBoost + ThresholdOptimizer pipeline that preserves the threshold contrast without shipping a 5MB tree ensemble in the bundle. I solved it by extracting per-race thresholds from the trained ThresholdOptimizer and applying them to a calibrated logistic approximation of the XGBoost decision function.
The third was packaging the audit as a research artifact rather than a dashboard. Most fairness submissions look like Streamlit apps. I wanted something that read like an investigative report from Bloomberg or The Pudding.
Accomplishments I'm proud of
- Catching algorithmic redlining via SHAP-driven proxy variable detection (correlation of −0.416 between tract minority population and race)
- Demonstrating that ThresholdOptimizer achieves full legal compliance for a 3.39% accuracy tradeoff
- Building all of this as a single-author research artifact in two weeks, presented at a level of editorial polish I haven't seen in any prior fairness audit
- Three deployment surfaces: Zerve Gallery, Zerve Streamlit app, and Vercel editorial site
- Radical transparency: every preprocessing decision, hyperparameter, fairness formula, and library version is documented in the methodology section so any third party can reproduce or challenge the findings
What I learned
Accuracy is a dangerous metric in high-stakes ML. A model can score 98.78% accuracy while violating federal lending law for three demographic groups. Fairness audits must be standard practice before deployment, not optional.
Explainability tools like SHAP can detect proxy variables that bypass fairness-through-unawareness approaches. Excluding race from your features does not mean your model is race-blind; it means your model has to reconstruct race from whatever else is correlated with it, like ZIP code.
The technical fix for algorithmic discrimination is often trivial. The hard part is the institutional will to apply it.
What's next for FairLens
- Extending the framework to healthcare resource allocation and hiring algorithms
- Building a self-service API where any organization can upload a dataset and receive an automated fairness compliance report against their relevant regulatory thresholds
- Submitting the methodology as a workshop paper to FAccT 2026
- Open-sourcing the audit template as a reusable Zerve notebook
Built With
- d3.js
- fairlearn
- framer-motion
- hmda
- nextjs
- numpy
- pandas
- python
- react-three-fiber
- scikit-learn
- shap
- streamlit
- tailwind
- typescript
- vercel
- xgboost
- zerve

Log in or sign up for Devpost to join the conversation.