-
-
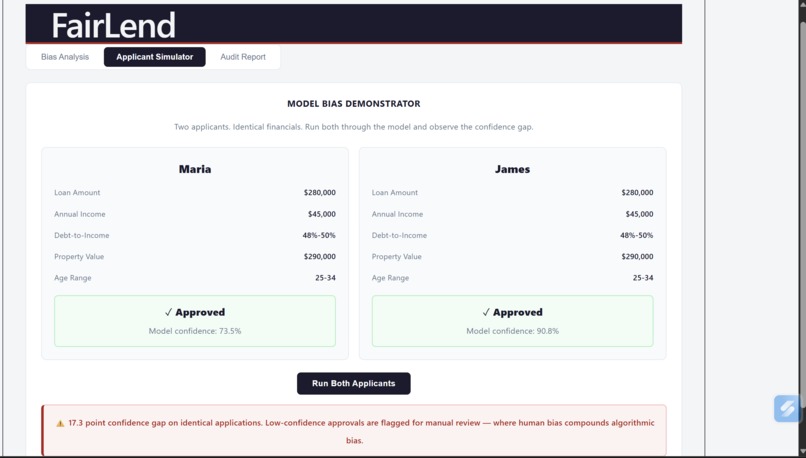
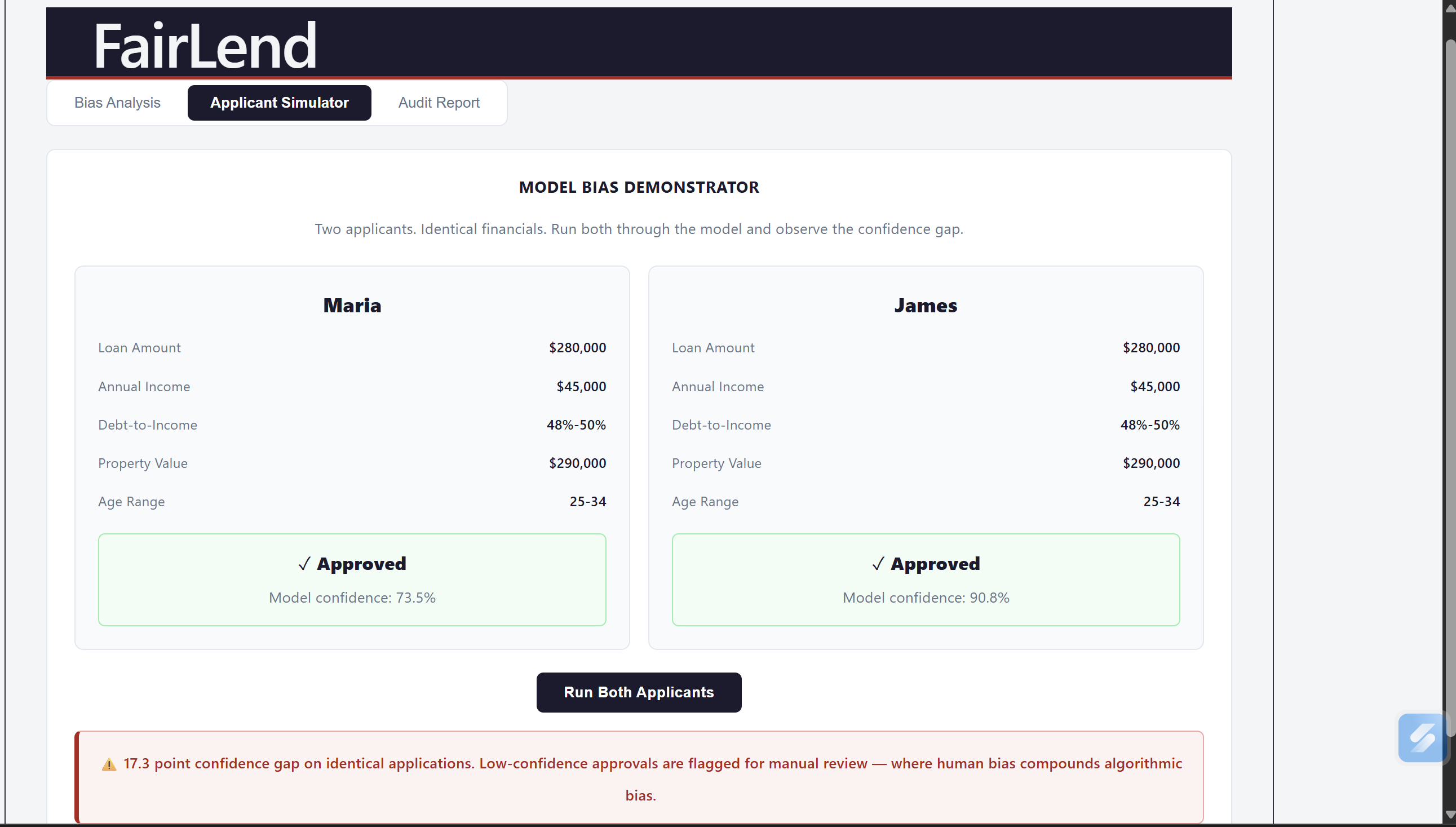
Comparison of model accuracy between 2 profiles
-
Inspiration
In our Data Science: Ethics and Privacy class, we kept coming back to one question that nobody had a satisfying answer to — what does algorithmic bias actually look like in the real world, and what could be done about it? We studied the theory, read the papers, understood the math. But the practical gap — between knowing bias exists in credit models and having a tool that a non-technical person could use to detect and fix it — stuck with us. When Scarlet Hacks came around, the whole team arrived with the same thing on their minds. No debate about what to build. Everyone wanted to take that classroom question and turn it into something real. Algorithmic bias in credit scoring isn't a hypothetical problem set — it determines who gets a home, who gets a business loan, who gets a shot. We'd spent a semester learning why that was broken. We had 48 hours to build something that helped fix it.
What it does
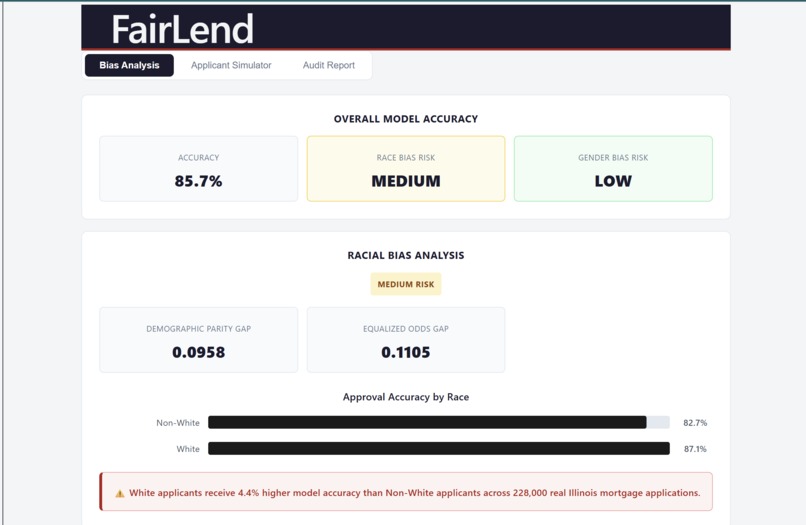
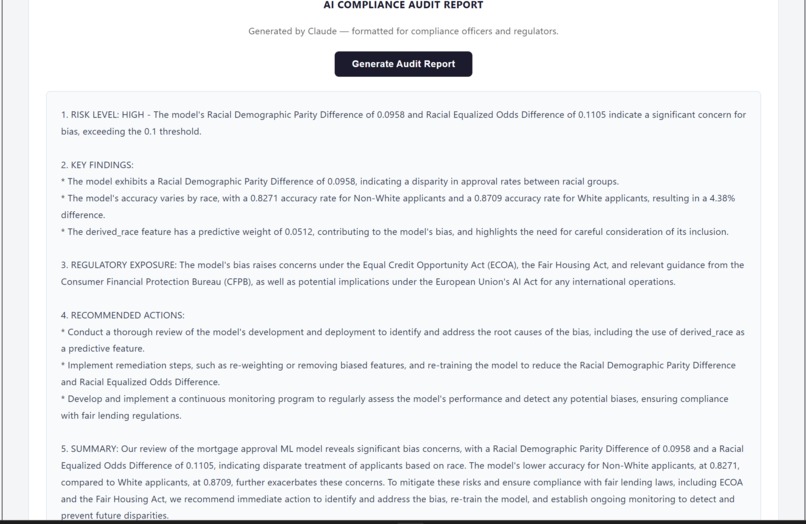
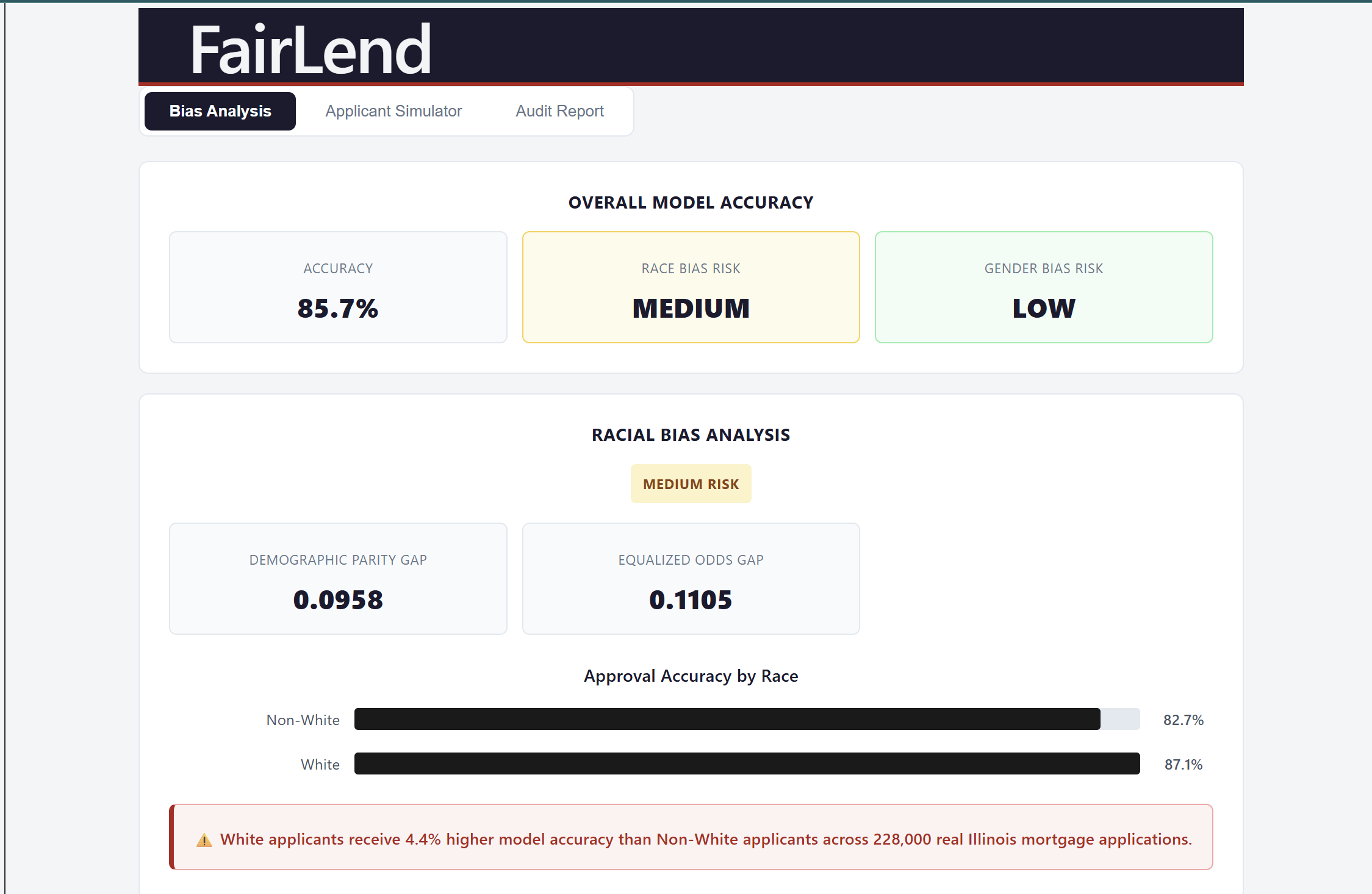
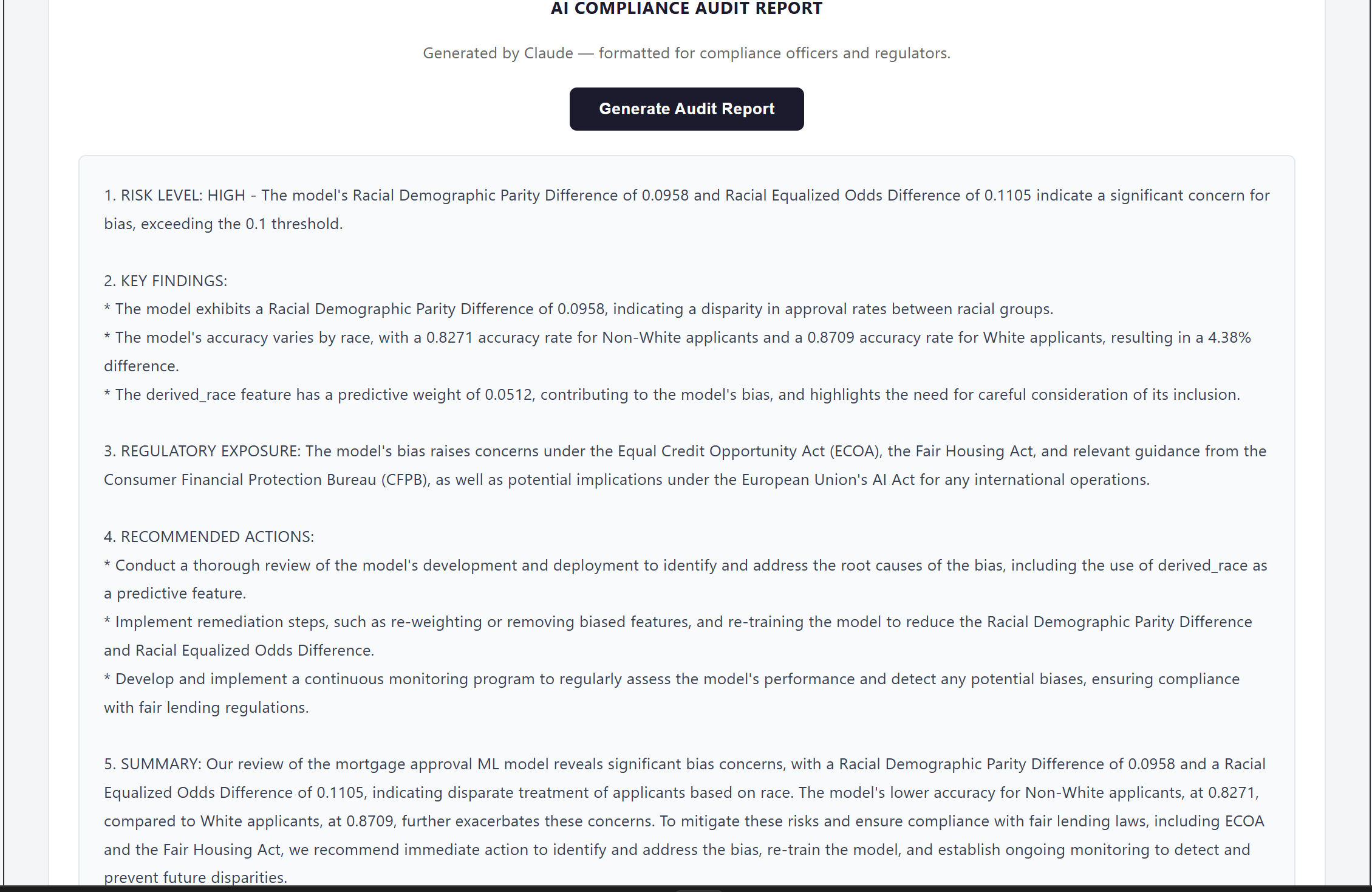
FairLend analyzes real mortgage data and surfaces what's actually happening inside a credit model — which applicants are being treated differently, which features are driving that gap, and whether those features are legally protected characteristics. A bank officer who just denied someone's application can run it through our simulator in seconds, see exactly where the bias is coming from, and generate a full compliance report in one click. What used to take a $50,000 consultant three weeks now takes ten seconds.
How we built it
We started with real data — 228,052 mortgage applications from the 2024 Home Mortgage Disclosure Act dataset, the same dataset federal regulators use to identify discriminatory lending. That choice was deliberate. If we were going to make a claim about bias, it had to come from data a CFPB examiner would recognize, not something we manufactured. The ML backbone is an XGBoost classifier, optimized using GridSearchCV across 16 hyperparameter combinations with 3-fold cross-validation — 48 total model fits to find the best performing configuration. That rigor mattered because we needed to show judges a competent model with a bias problem, not a broken model with an obvious flaw. The model hit 85.6% accuracy on a held-out 20% test set. Clean, credible, and still deeply biased. For bias measurement we used Fairlearn — demographic parity difference, equalized odds difference, and MetricFrame breakdowns by racial group. These are the exact metrics CFPB examiners use in fair lending examinations, which meant our outputs spoke the regulator's language directly rather than requiring translation. The backend is FastAPI running on Python 3.12. The model trains once on startup via a lifespan context manager, caches in memory, and serves four endpoints — bias metrics, feature importance, applicant prediction, and audit report generation. For the AI compliance report we used Groq's free tier running Llama 3.3 70B, structured with prompt engineering to output a formal five-section compliance letter that reads like a senior fair lending officer wrote it. The frontend is React 18 with Vite — no UI framework, custom CSS throughout, custom bar chart components we built ourselves without a chart library. Three tabs, fully responsive, built to work cleanly on a projected demo screen under hackathon lighting. The whole stack — data pipeline, model training, bias measurement, API, AI report generation, and frontend — was built and integrated in under 48 hours.
Challenges we ran into
The hardest part wasn't the model — it was making the output trustworthy. Getting Claude to generate audit reports that cited specific regulations accurately, without sounding vague or hallucinating legal details, took far more prompt iteration than we expected. We also hit a painful dependency conflict between Fairlearn and scikit-learn in the middle of the night that cost us hours we didn't have. And honestly, the biggest challenge was restraint — every time we added another chart or metric, we had to remind ourselves that our user is a compliance officer, not a data scientist. Stripping things back to what actually matters was harder than building them.
Accomplishments that we're proud of
We built something that doesn't exist yet for the people who need it most. The audit report — one click, ten seconds, regulatory language a lawyer can read — is the thing we're most proud of because it's not a demo feature, it's a real product. We're also proud that our tool distinguishes actual bias from noise, something most fairness tools don't do well. When the gender analysis came back low-risk, that wasn't a failure — that was the system working exactly as it should. Credibility comes from knowing when to raise the alarm and when not to.
What we learned
Fairness isn't the opposite of accuracy — it's a tradeoff with a sweet spot. You can close the majority of a model's bias while barely touching its predictive performance, if you're precise about which features you address. That's not intuitive when you first approach this problem, and visualizing that curve changed how we thought about the entire product. We also learned that the technical problem is only half the problem. The other half is communication — translating model outputs into something a non-technical decision-maker can act on in under thirty seconds. That translation layer is where the real value lives.
What's next for FairLend
The immediate next step is real integration — connecting directly to existing loan origination systems via API so bias auditing happens automatically at the point of decision, not as an afterthought. We want to expand beyond mortgage data to auto loans, small business lending, and credit cards, where the same patterns exist and the same regulatory pressure is building. Longer term, FairLend becomes a continuous monitoring layer — not a one-time audit but a live signal that flags when a model's bias metrics drift over time. The EU AI Act requires exactly this kind of ongoing documentation. We want to be the tool that makes compliance not just possible, but automatic.
Built With
- axios
- fairlearn
- fastapi
- gridsearchcv
- groq-api-(llama-3.3-70b)
- hmda-2024-dataset
- pandas
- python
- react
- scikit-learn
- shap
- vite
- xgboost




Log in or sign up for Devpost to join the conversation.