

Inspiration
- Generic LLMs are bad at hardware design, and the failure mode is sneaky: they emit confident-looking RTL and confident-looking performance numbers, and you can't tell which parts are real.
- The literature pointed the way: ChipNeMo showed domain adaptation plus grounded evaluation is what moves the needle; NL2GDS showed NL-to-hardware should be a staged flow with tool feedback and repair, not one-shot.
- Our guiding constraint, and the source of the name: never let an estimate masquerade as a measurement.
What it does
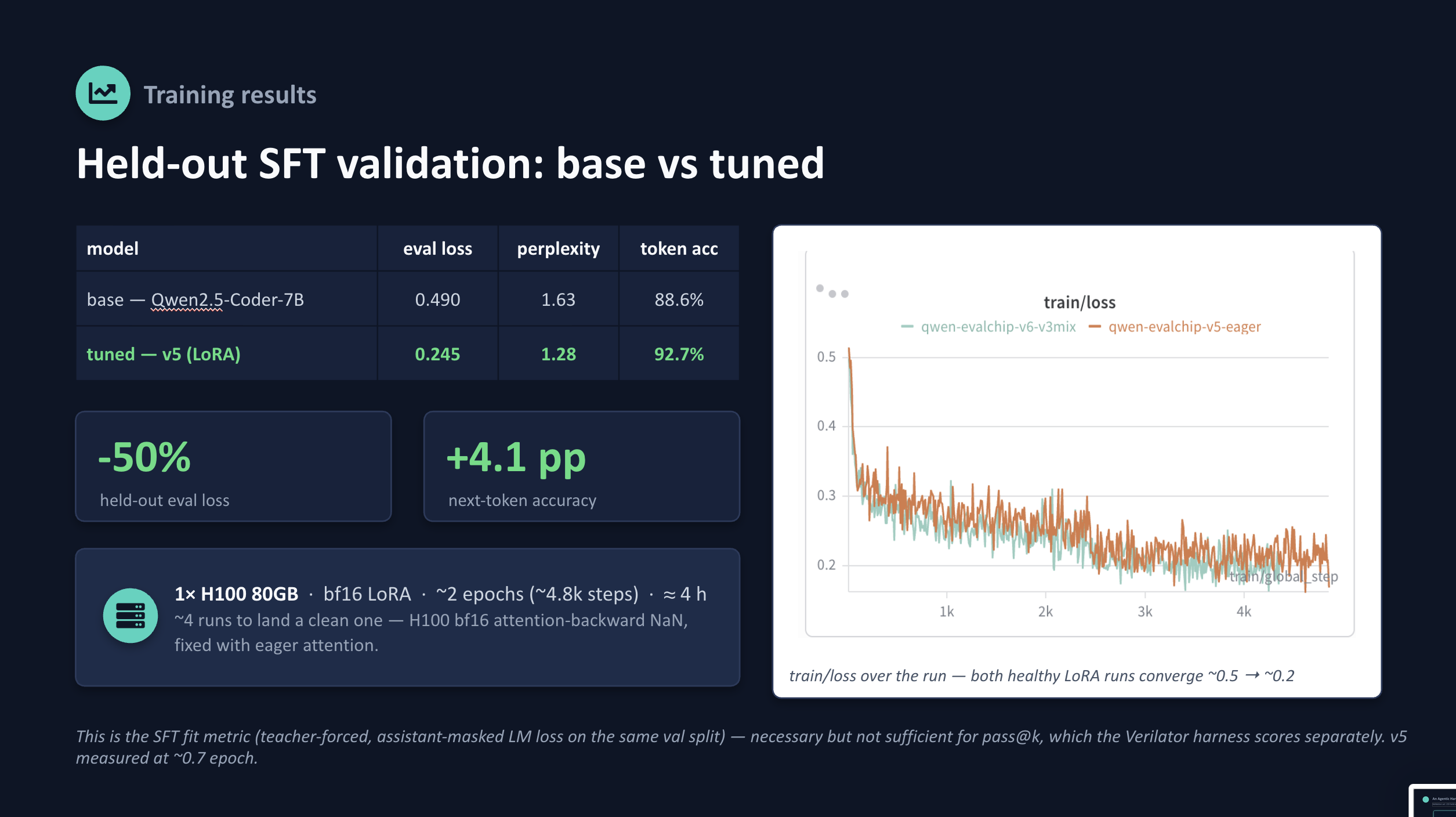
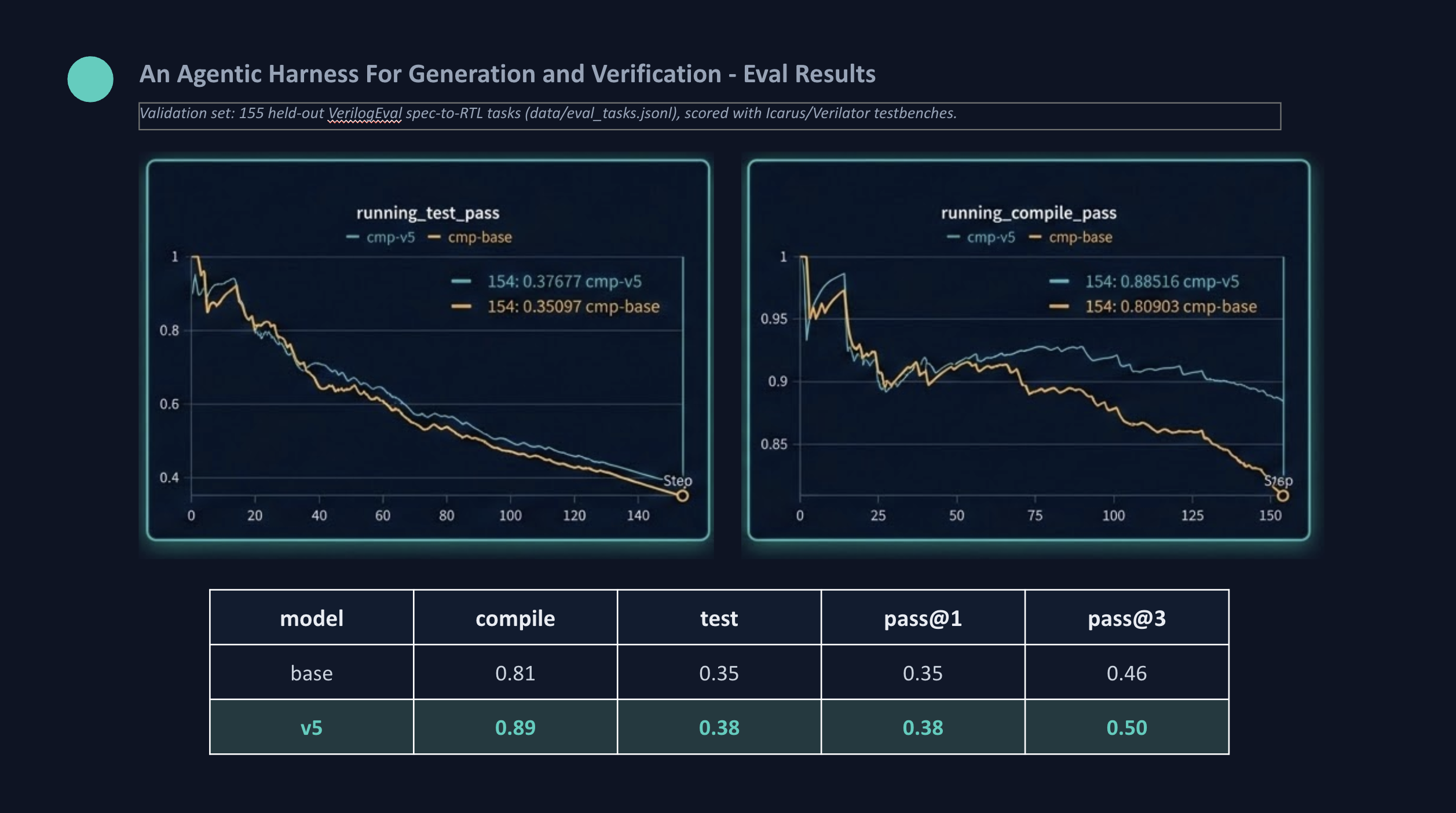
Tuned model (the scientific claim): Qwen2.5-Coder-7B-Instruct fine-tuned with QLoRA to generate Verilog and repair RTL from real tool errors, measured base vs. tuned vs. tuned+repair on a held-out, decontaminated benchmark (VerilogEval + RTLLM).
Evaluation-native IDE (the demo): type a hardware request, and a staged pipeline turns it into a validated spec, ranks hardware candidates under the power budget, generates real RTL, verifies it with Verilator, and produces a downloadable report.
The honesty contract: every estimated number is tagged
[ESTIMATE], the Verilator lint result is the single[MEASURED]signal, and the two are kept separate everywhere. Failures feed back into the tuned repair loop.
How we built it
Four parallel swimlanes with pydantic schemas as the up-front contract, so everyone built against stubs from minute one: Product/Integration, Model Tuning, Benchmark/Evaluator, and RTL/Tools/Frontend.
Model lane: LoRA SFT on an H100 80GB (~38k examples), served via an A100 vLLM as an OpenAI-compatible endpoint.
An Agentic Harness that includes varies tools for formal verification and benchmarking
An integrated IDE
Challenges we ran into
- Decontamination — keeping VerilogEval and RTLLM strictly held-out so the benchmark result is honest.
Holding the line on the measured/estimated split across schemas, UI, and report.
Making the GPU run safe and cheap with trap-on-exit teardown and a hard wall-clock timeout.
Constructing the SFT data mixture
Getting the harness to work e2e
Accomplishments that we're proud of
A real, reproducible base-vs-tuned-vs-tuned+repair lift from a genuinely fine-tuned 7B model — not a prompt-wrapped base.
A complete NL-to-verified-RTL pipeline that's rigorously honest about what it knows.
What we learned
- Most of us do not have any silicon engineering experience and heard most of the terminology for the first time. It was a great learning experience!
What's next for Fairchild
- Close the repair loop fully inside the live IDE, not just the benchmark.
- Move beyond RTL generation
- Goal: Devin for chip design!
Built With
- agents
- claude
- devin
- harness
- prime-intellect
- sft
- tool-use
- trl

Log in or sign up for Devpost to join the conversation.