-
-

Fair AI in an Unfair World
-
Data Analytics

Inspiration
Lending decisions should not depend on race, gender or any demographic information. It should depend on credit worthiness.
What it does
AI is starting to be everywhere. AI is only as good as the data it's built from. If the data is biased, any AI will be biased too. We found many references that indicate that there is a history of bias in lending decisions and there are definitely approaches to improve this. It is extremely important to gain insight into data to understand whether what was provided is biased or not.
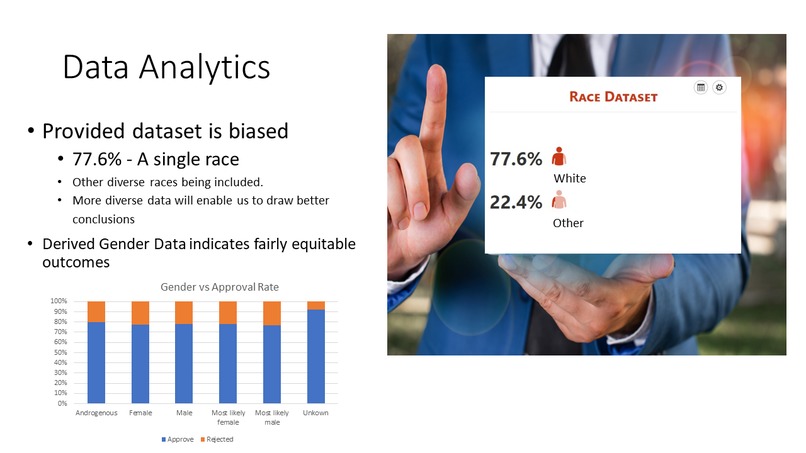
First, we use analytics where we combined the provided data with census data and some open source algorithms to identify gender and white/non-white applicants. We then investigated the impact of race and gender on loan approvals.
Next, we used open source tooling that assesses fairness in ML algorithms and helps understand how to mitigate any unfairness. We wanted to highlight that there are available algorithms that are freely available and easy to use to help identify and mitigate bias in lending.
How we built it
There are two main areas of focus:
Data Analytics and Enhancement AI Algorithms and Scoring
First, we combined Customer Demographics with Customer Loan Data. Then, a tool called Nameparser was used to split the customer’s full name into First Name, Last Name, Middle etc. Last Name was then converted into Surname. Then, to determine Race, we used a package call Surgeo that uses First Name & Surname coupled with location (Bayesian Improved First Name Surname Geocoding (BIFSG)) & Census data to determine race.
After we enhanced the data set with race, we decided to derive gender. We used Gender-guesser, a package that uses the First Name to derive gender. This was a straightforward as we already had the customer’s name split. With all of our demographic data enhanced, we were able to begin to evaluate the data set. We created several financial metrics from the provided data such as scaled income, the debt to asset ratio, the ratio of the home against the median, and the number of credit incidents. In order to prepare for AI, certain text-based categories like job were transformed using one hot encoding to transform the categorical variables into a form which improves a Machine Learning Models prediction.
Next, we split the dataset into training & test data, the training data trains the AI, while the test data is used to score it against previously unseen data to see its score. The purpose of splitting the data is to not build up a reliance on data patterns in the test data, but to also provide insights regarding how these tools will behave in the real world with new data.
Four type of models were chosen, Logistic Regression, Decision Tree Classifier, XgBoost & K Nearest Neighbors. After many rounds of testing, slowly expanding the parameters and observing the test vs train result, the Decision Tree Classifier was able to achieve greater than 95% accuracy on predicting the loan status from 14 features. Using that model, we ran it through the open source github Fairlearn package which determined the impact a feature had on the resulting loan status.
Challenges we ran into
There are some oddities in the provided data. For example:
- some applicants are particularly old
The provided dataset did not include race or gender. We enhanced the provided dataset with census data and open source tools so that race and gender could be identified for further investigation.
Accomplishments that we're proud of
We have a broad variety of expertise on the team. We made a special effort for each of us to "level-up" everyone else and it was a true team effort.
What we learned
Some of the references we found, identified issues with bias in loans and financial areas. It's clear that this area requires more attention. Lending decisions should not depend on race, gender or any demographic info. It should depend on credit worthiness.
What's next for Fair AI in the Unfair World
It would be interesting to expand this with better datasets and to promote tools like FairLearn to determine fairness and mitigate any bias so that lending decisions are based on credit worthiness.
Built With
- azure
- azure-ai
- azure-ml
- fairlean
- interpretml
- jupyter-notebook
- scikit-learn


 Luo")


 Luo")
Log in or sign up for Devpost to join the conversation.