-
-

FailWise Agent is a focused failure-aware AgentOps dashboard for resilient AI agents.
-
FailWise Head Part Demo
-
FailWise Debug Graph Demo
-
FailWise Log Demo

Inspiration
Modern AI agents are becoming more powerful, but they also depend on many fragile infrastructure components: MCP servers, retrieval systems, LLM gateways, caches, and incident tools. When one of these components fails, a normal observability dashboard may show that something went wrong, but it does not always explain whether the agent understood the failure, recovered safely, downgraded its confidence, or refused to hallucinate.
FailWise Agent was inspired by this gap.
We wanted to build a focused AgentOps demo that answers a simple but important question:
When infrastructure chaos hits an AI agent, can the operator immediately understand where it failed, why it matters, how it recovered, and what to fix next?
Instead of hiding resilience behavior inside logs, FailWise Agent makes failure handling visible through an interactive execution graph.
What it does
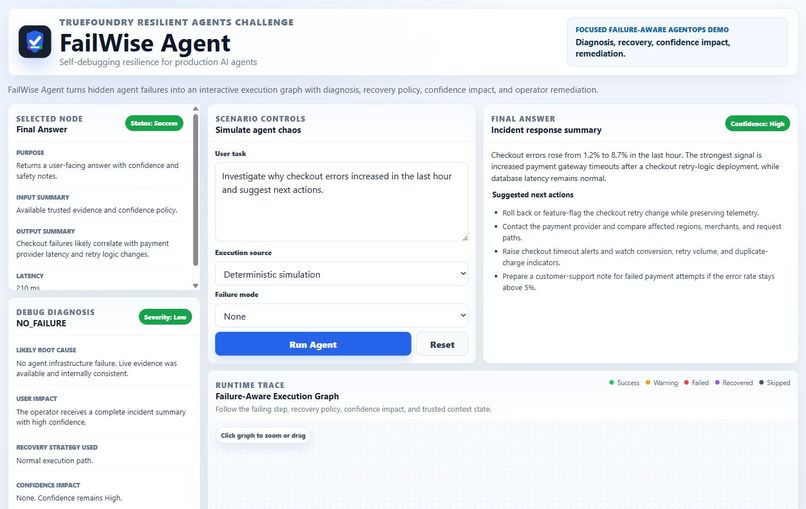
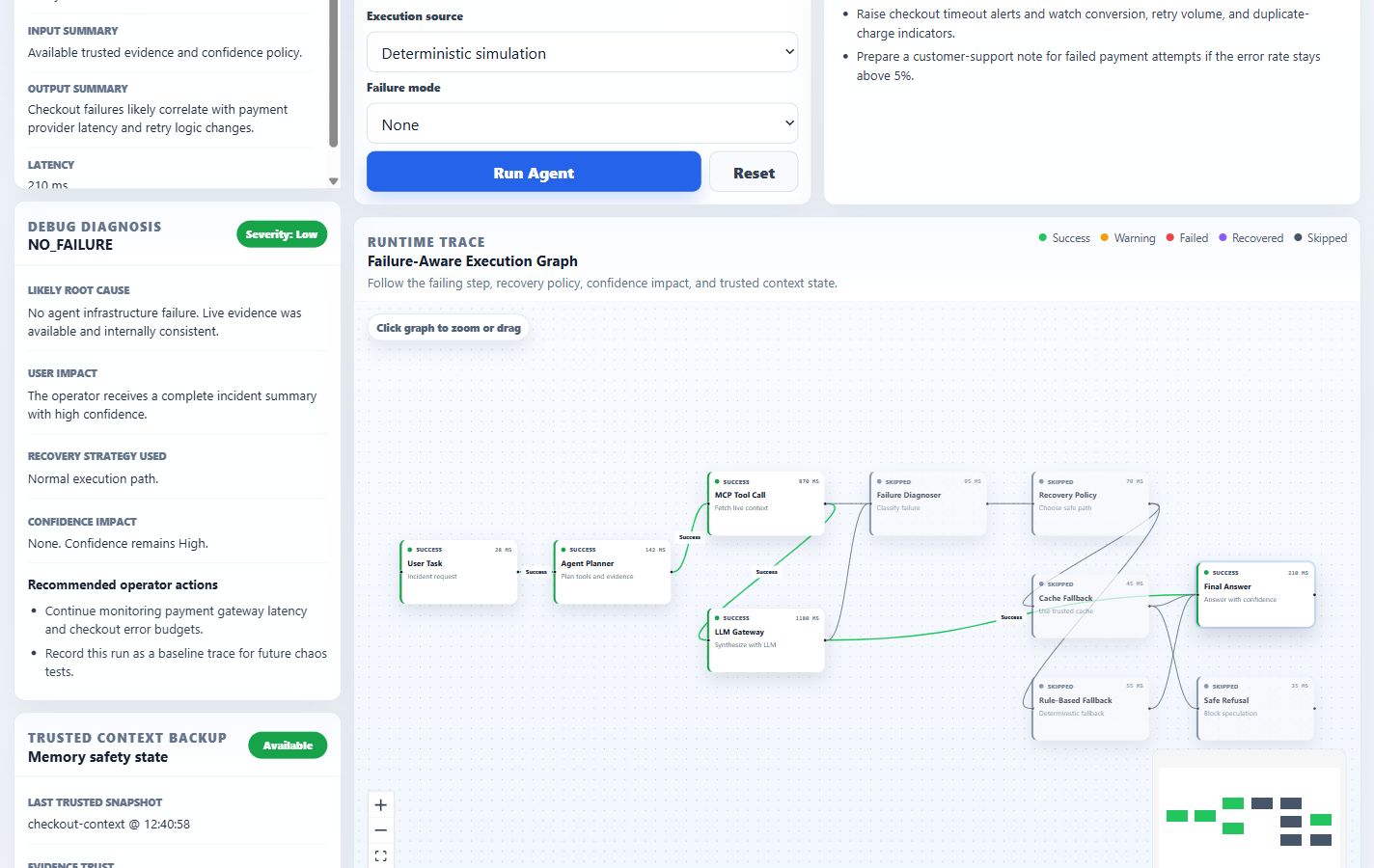
FailWise Agent is a self-debugging AgentOps dashboard for resilient AI agents.
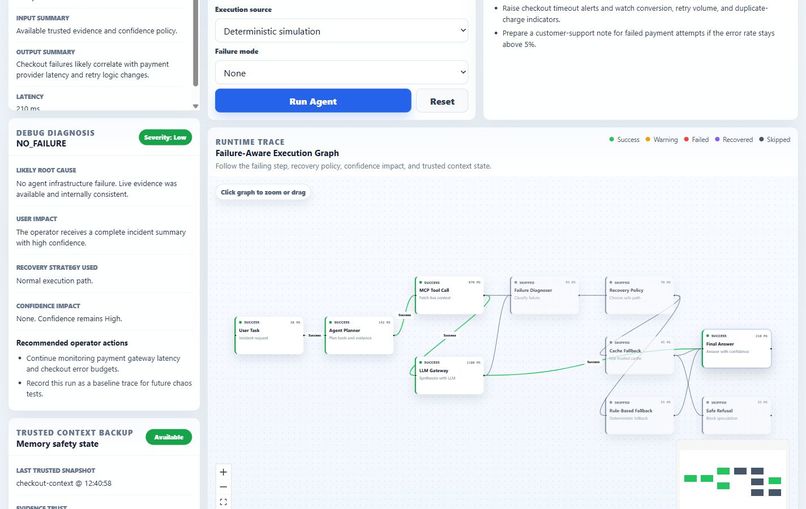
It turns an agent run into an interactive failure-aware execution graph. Each node represents a runtime step such as user task, agent planning, MCP tool call, LLM gateway, failure diagnosis, recovery policy, cache fallback, rule-based fallback, final answer, or safe refusal.
The dashboard helps operators see:
- Where the agent failed
- What failure case was detected
- Why the failure matters
- What recovery policy was applied
- How confidence was impacted
- What the operator should fix next
The demo includes multiple infrastructure failure scenarios, including MCP timeout, MCP server error, empty retrieval, corrupted tool response, LLM provider failure, cache miss, partial evidence, and unknown failure.
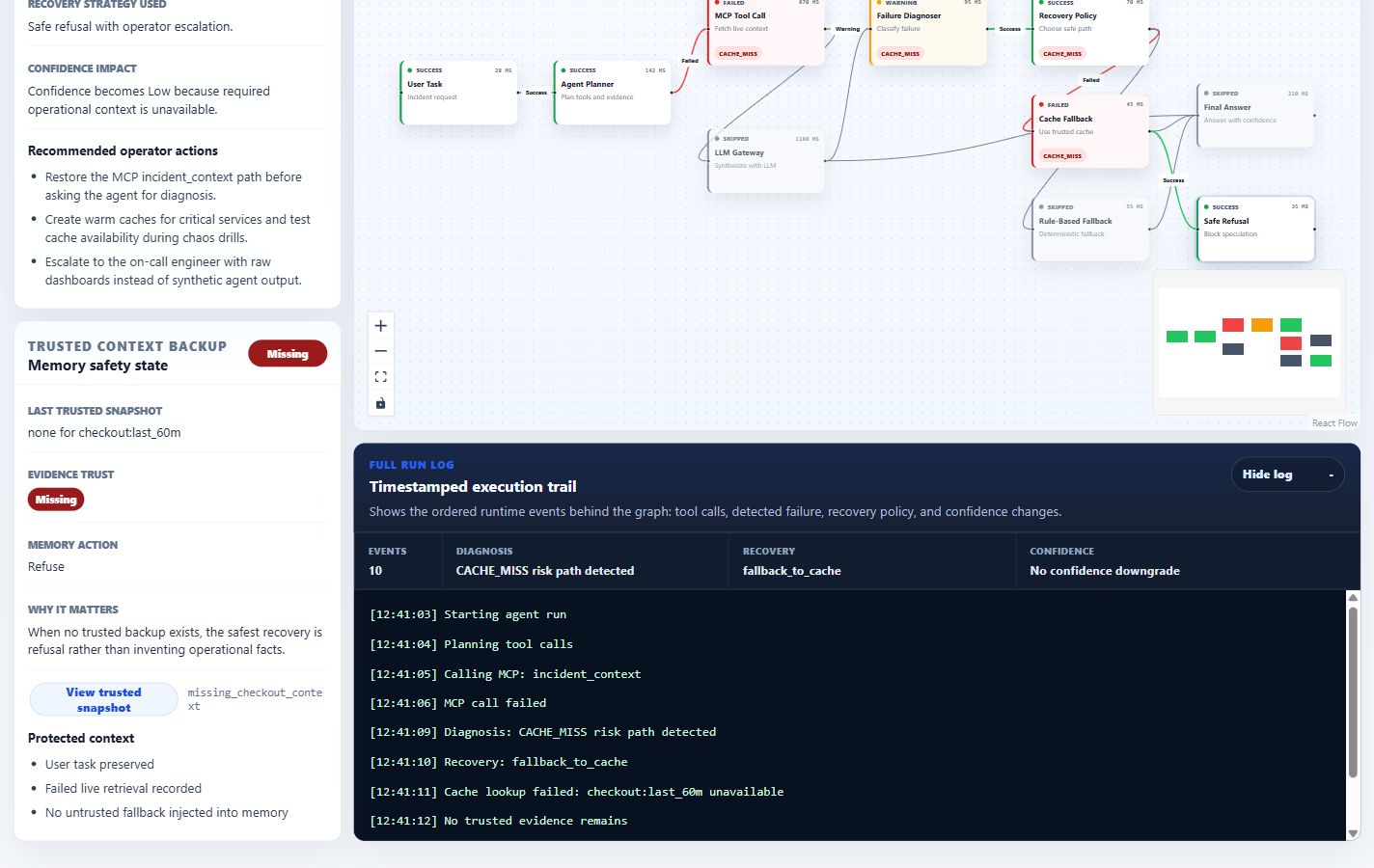
One of the most important behaviors is safe refusal. If the agent has no trusted operational context or usable cache, it refuses to invent incident findings. This shows that resilience is not only about fallback. It is also about knowing when not to answer.
How we built it
We built FailWise Agent as a local deterministic prototype so the demo can run reliably without requiring a backend.
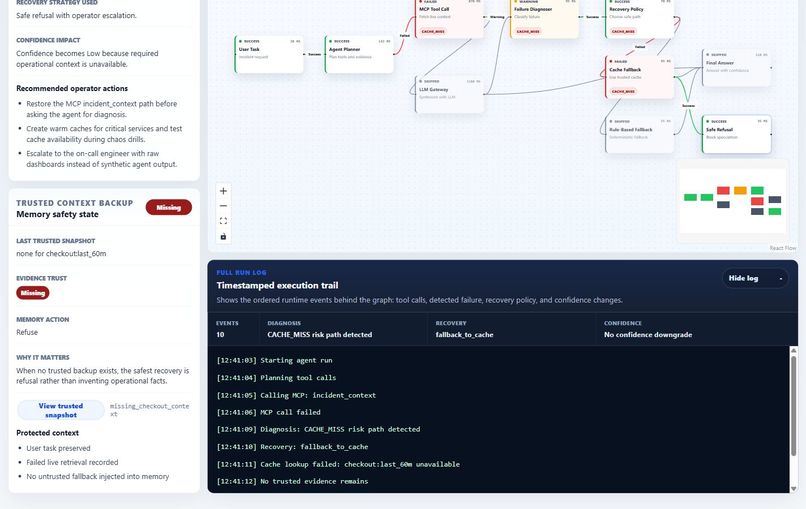
The frontend is built with a modern React and Vite stack. The main product surface is an interactive execution graph using draggable runtime nodes. Each node shows its status, latency, short description, and failure badge. Clicking a node opens detailed information such as purpose, input, output, error, detected failure case, recovery action, confidence impact, and operator recommendation.
The scenario engine simulates a generic enterprise checkout incident. The incident includes increased checkout error rate, payment gateway timeout, a recent deployment touching checkout retry logic, normal database latency, elevated third-party payment provider latency, and a slight cache hit-rate drop.
We designed the system around a few core panels:
- Execution graph for visual runtime tracking
- Debug Diagnosis panel for root cause, severity, recovery strategy, confidence impact, and operator actions
- Final Answer panel for summary, confidence, safety note, and next actions
- Full Run Log for step-by-step runtime and diagnosis events
The project is intentionally focused. It does not try to replace full observability platforms. Instead, it demonstrates a failure-aware UX layer for resilient agents.
Challenges we ran into
The main challenge was choosing the right scope.
Agent observability can become very broad very quickly: traces, metrics, logs, analytics, incident history, production infrastructure, provider routing, OpenTelemetry, and real MCP integrations. For a hackathon prototype, we needed to narrow the product to the most important resilience question: what should an operator understand when an agent fails?
Another challenge was designing failure states clearly. A normal error message is not enough. We needed to show the difference between failed, degraded, recovered, skipped, and safely refused states. We also needed the UI to explain confidence impact, not just technical failure.
The third challenge was making the demo deterministic. A live AI system can be unpredictable, and hackathon judging requires a repeatable flow. We therefore built local scenarios that clearly demonstrate each failure mode and recovery path while still representing realistic production agent behavior.
Accomplishments that we're proud of
We are proud that FailWise Agent makes agent resilience understandable at a glance.
The interactive graph gives operators a clear visual path from user task to final answer or safe refusal. It shows not only that a failure happened, but also how the agent reacted to it.
We are also proud of the safe refusal path. In many AI demos, the agent tries to answer even when context is weak. FailWise Agent shows the opposite behavior: when trusted evidence is unavailable, the agent should refuse instead of hallucinating.
Another accomplishment is the product framing. FailWise Agent is not just another observability dashboard. It focuses specifically on failure-aware agent behavior: diagnosis, recovery, confidence impact, and operator remediation.
What we learned
We learned that resilient AI agents need more than fallback logic.
A fallback is useful only if the system can explain why it was triggered, what confidence was lost, and what the operator should do next. In production, trust is not created by a successful-looking answer. Trust is created by transparent reasoning about failure, evidence, recovery, and uncertainty.
We also learned that agent UX matters. If resilience behavior is only visible in raw logs, most operators will not understand it quickly enough during an incident. A clear graph, failure badges, confidence downgrade, and recommended operator actions can make the system much easier to debug.
Most importantly, we learned that safe refusal is a core resilience behavior. A reliable agent should not only recover from failure. It should also know when the available evidence is not strong enough to answer safely.
What's next for FailWise Agent
Next, we want to connect FailWise Agent to real production agent infrastructure.
Planned future work includes:
- TrueFoundry AI Gateway integration
- Real MCP server integrations
- Provider fallback routing
- OpenTelemetry trace support
- Persistent run history
- Real incident tool integrations such as Datadog, Jira, Slack, GitHub, and PagerDuty
- More advanced failure classification and recovery policy templates
The long-term vision is for FailWise Agent to become a failure-aware UX layer for production AI agents. Instead of only asking whether an agent produced an answer, teams should be able to ask:
Did the agent understand the failure, recover safely, communicate confidence correctly, and guide the operator to the next fix?
Built With
- react
- reactflow
- typescript
- vite

Log in or sign up for Devpost to join the conversation.