Inspiration
Robots and self-driving systems do not usually fail in clean demos. They fail in rare edge cases: slippery floors, dropped objects, occluded humans, reflective surfaces, bad lighting, sensor noise, and unexpected physical interactions.
Collecting these failures in the real world is expensive, slow, dangerous, and hard to reproduce. That inspired us to build FailureCloud: unit tests for robots.
Software engineers have unit tests. We built FailureCloud to give robotics and physical AI teams unit tests for robots.
The problem
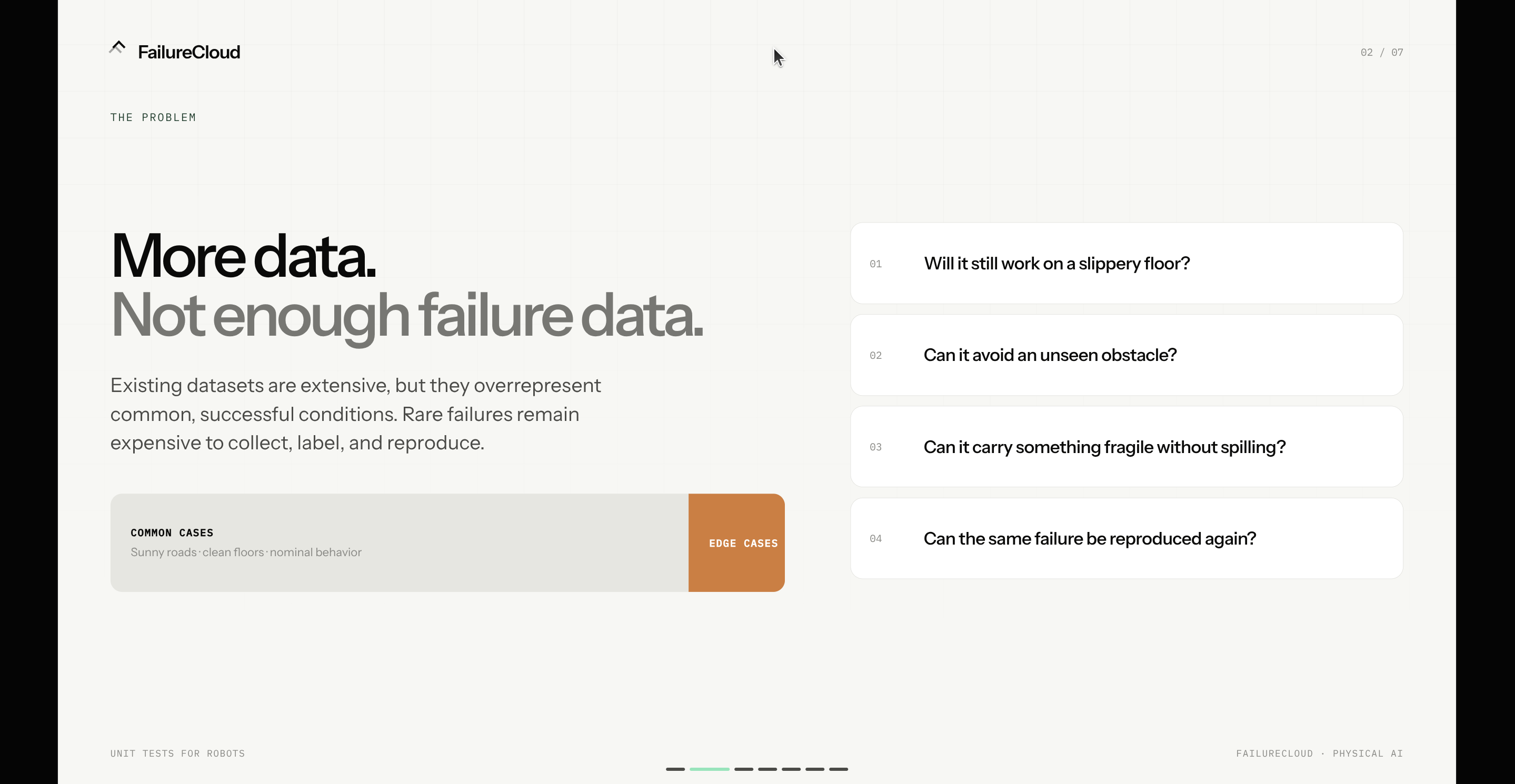
- The future of AI-like robots and self-driving cars requires lots and lots of data.
- Current datasets are extensive, but they cover common senarios, like driving in a sunny or cold day.
- They overrepresent positive cases and underrepresent edge cases and failure cases, where things could actually go wrong.
- Conviction is furthered by Waymo beginning similar research, seen here
Robotics teams need to know:
- Will the robot still work on a slippery floor?
- Can it avoid an unseen obstacle?
- Can it carry something fragile without spilling?
- Can its sensors handle noisy or incomplete data?
- Can the same failure be reproduced again and again?
- Today, many of these cases are manually built in simulation or discovered through risky real-world * testing. Even after data is collected, labels, rewards, and success conditions are still painful to define.
What it does
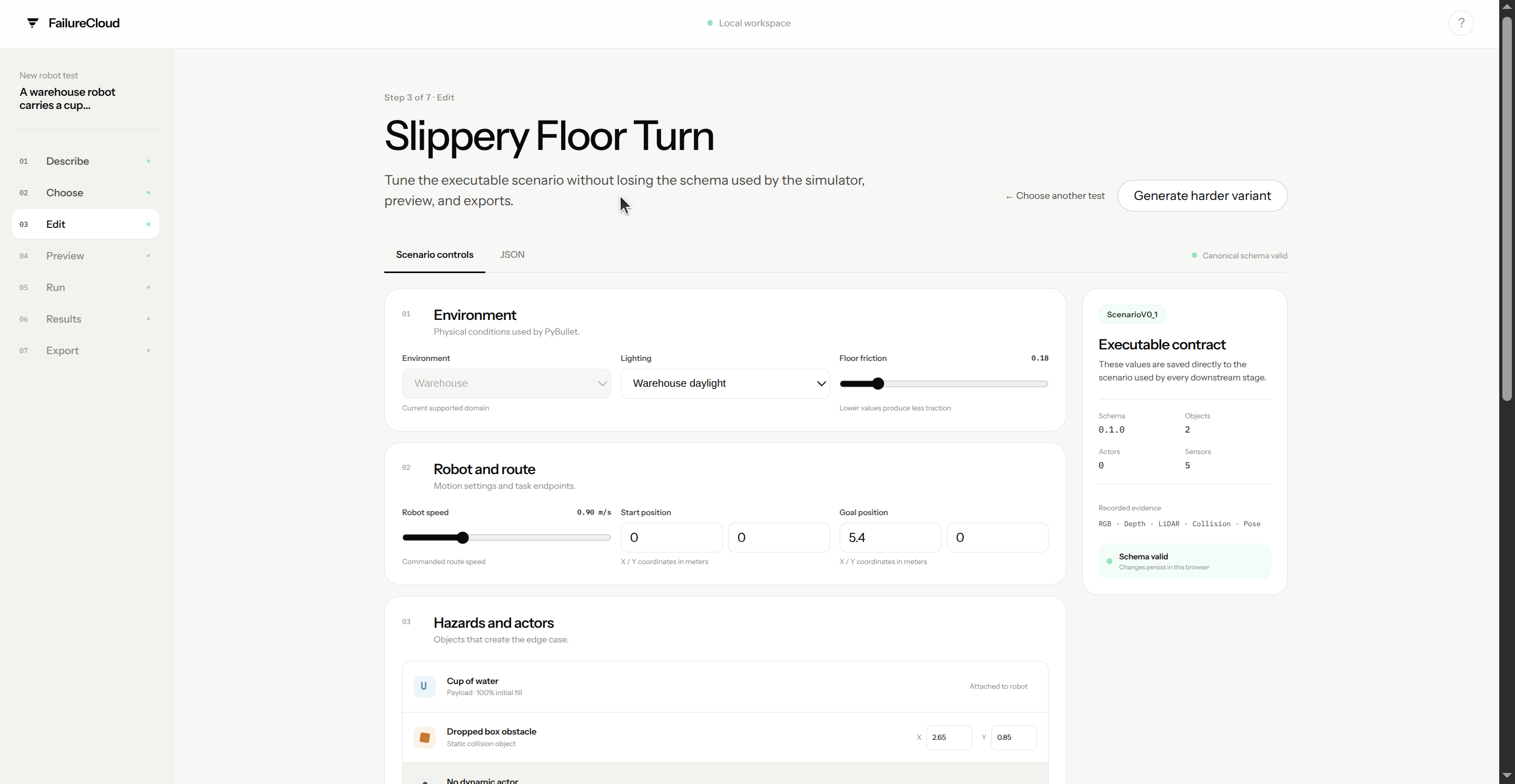
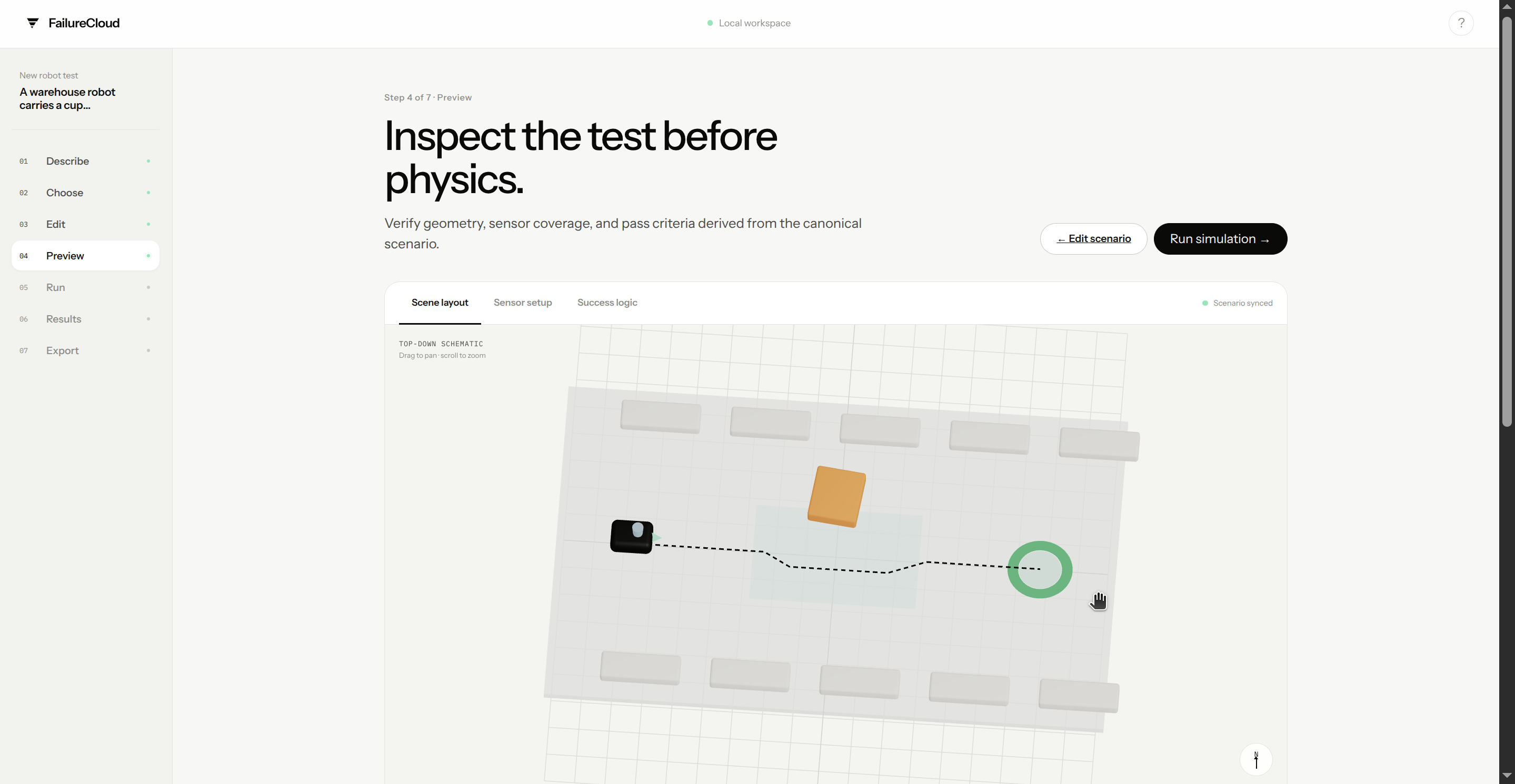
FailureCloud turns a natural-language robot task into an executable edge-case test.
A user describes a task, selects one of five generated failure scenarios, edits its parameters, previews it, runs it in PyBullet, inspects synchronized sensor evidence, and exports the result.
Each test includes:
- Environment, robot, route, and hazards
- RGB, depth, segmentation, and LiDAR data
- Object labels and telemetry
- Reward and success criteria
- A measurable pass/fail explanation
- Simulator and dataset exports
Users can also upload custom URDF robot packages.
Architecture
FailureCloud is built around a versioned, simulator-independent scenario contract:
Natural-language task
↓
Edge-case generation
↓
ScenarioV0_1
↓
Preview and simulator adapter
↓
Sensor recording and evaluation
↓
Canonical run bundle
↓
Export adapters
Every layer consumes this contract. PyBullet is the current execution adapter, but FailureCloud is designed to export the same scenario to simulators such as Isaac Sim, Gazebo, and CARLA.
Data flow and exports
PyBullet records RGB, metric depth, segmentation, ray-cast LiDAR, object poses, collisions, cup stability, water retention, and reward telemetry.
These results are stored in a canonical bundle containing the scenario, frame manifest, sensor data, labels, calibration, evaluation, and robot assets.
Export adapters convert this bundle into:
- PyBullet replay packages
- OpenPCDet datasets
- ROS-style sensor folders
- Isaac Sim configuration previews
- Nebius job manifests
Because canonical data is separated from export formats, new integrations can be added without rerunning the simulation.
How we built it
The frontend uses Next.js, React, TypeScript, Three.js, React Three Fiber, SWR, and Playwright.
The backend uses FastAPI, Pydantic, PyBullet, NumPy, Pillow, and Claude. Claude generates edge-case ideas, while deterministic templates keep the workflow reliable when external services are unavailable.
Best Physical AI Hack by UFB
TL;DR: FailureCloud creates unit tests for robots.
It fits Physical AI because it directly generates, simulates, evaluates, and exports the data and worlds that train or test robotic systems. Given a natural-language task like “a warehouse robot carries a cup of water,” FailureCloud generates rare edge-case scenarios such as slippery floors, dropped obstacles, noisy sensors, and sudden turns.
For each scenario, we generate a runnable simulation, RGB/depth/LiDAR-style sensor data, object labels, reward metrics, and a pass/fail report. The goal is simple: help robotics teams test failures before they happen in the real world.
A real robotics team would use this to quickly create repeatable edge-case tests, debug robot failures, evaluate policies, and export reusable test bundles for tools like PyBullet, ROS, Isaac Sim, OpenPCDet, or future physical AI workbenches.
Best Use of Claude
TL;DR: Claude acts as the scenario compiler for robot unit tests.
We use Claude to turn vague human intent into structured physical AI test cases. A user can describe a normal robot task, and Claude expands it into realistic edge cases, simulation parameters, sensor configurations, reward logic, and definitions of success or failure.
For example, from “a robot carries a cup,” Claude can infer failure modes like slippery floors, sharp turns, spills, collisions, and sensor noise. It then converts those into an executable scenario with measurable success criteria, such as reaching the goal with at least 70% of the water remaining and no collisions.
Claude is essential because it bridges natural language and robotics simulation. It lets non-experts describe what they want to test, while FailureCloud turns that into a runnable physical AI evaluation.
Challenges and accomplishments
The main challenge was avoiding simulator lock-in. We solved this by separating scenario intent, simulation execution, recorded evidence, and export delivery.
We built:
- A complete seven-step testing workflow
- A versioned scenario contract
- Editable reward and success logic
- Synchronized multimodal sensor recording
- Automatic labels and failure explanations
- Validated custom URDF uploads
- Multiple simulator and dataset export formats


Log in or sign up for Devpost to join the conversation.