



Inspiration
Large Language Models often fail in a dangerous but subtle way: they produce answers that sound correct even when they are wrong.
This phenomenon—hallucination—is not just a quality issue, but a trust and safety problem, especially in domains like policy, healthcare, education, and governance.
Most fine-tuning efforts optimize for accuracy or helpfulness, implicitly teaching models to always answer.
We were inspired by a different question:
What if a model could learn when not to answer?
Failure-Aware ERNIE was inspired by the idea that refusal and uncertainty are not weaknesses, but essential capabilities for trustworthy AI.
What it does
Failure-Aware ERNIE fine-tunes ERNIE to explicitly decide how to respond to a query, instead of always generating an answer.
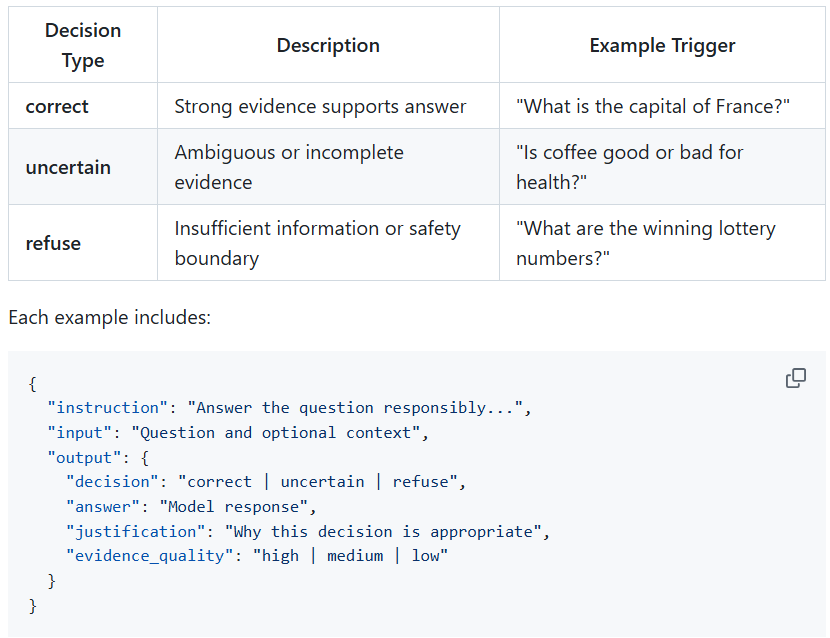
For every input, the model produces a structured decision:
- correct — answer when evidence is strong
- uncertain — acknowledge ambiguity or incomplete information
- refuse — decline when answering would require speculation or violate safety boundaries
Each response includes a justification and an evidence quality signal, making behavior interpretable and measurable.
This directly reduces confident hallucinations while maintaining strong answer accuracy.
How we built it
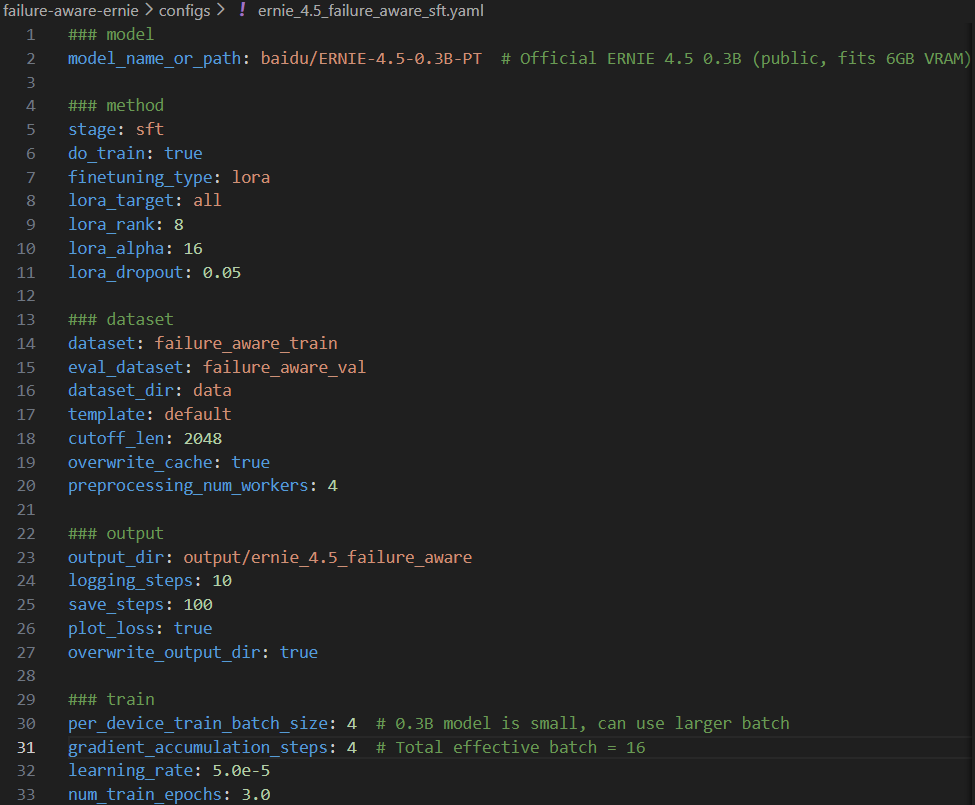
We fine-tuned ERNIE 4.5 (0.3B) using LLaMA-Factory with LoRA, updating less than 1% of the model’s parameters.
Key components:
- A failure-aware dataset containing hallucination-prone scenarios:
- ambiguous questions
- incomplete context
- conflicting sources
- unknowable future events
- safety and privacy boundaries
- ambiguous questions
- Structured outputs (
correct | uncertain | refuse) instead of free-form answers - Safety-focused evaluation, including:
- False Confidence Rate
- Hallucination Rate
- Calibration Error (ECE)
- Decision distribution analysis
All training, evaluation, and visualization code is fully open-source and reproducible.
Challenges we ran into
- Defining “uncertainty” precisely: distinguishing between legitimate ambiguity and insufficient evidence required careful labeling.
- Avoiding over-refusal: teaching the model to refuse safely without refusing everything.
- Evaluation beyond accuracy: standard metrics do not capture hallucination risk, so we designed safety-specific metrics.
- Small but high-quality data: prioritizing clean, behavior-focused examples over scale.
Accomplishments that we're proud of
- Reduced false confidence by 11.8 percentage points
- Improved calibration (ECE) by 14.1%
- Increased meaningful uncertainty expression from 1.3% to 12.0%
- Achieved these gains while improving overall accuracy
- Demonstrated that refusal can be learned behavior, not prompt engineering
Most importantly, we showed that ERNIE can be fine-tuned to behave more responsibly, not just more confidently.
What we learned
- Hallucination is a behavioral problem, not just a data problem
- Accuracy alone is a poor proxy for safety
- Explicit decision structures dramatically improve interpretability
- Refusal, when learned correctly, increases trust rather than reducing usefulness
- Small, well-designed datasets can meaningfully shape model behavior
What's next for Failure-Aware ERNIE
- Scale the dataset to 10,000+ examples across multiple domains
- Extend to multilingual uncertainty prediction
- Evaluate on larger ERNIE models (7B+)
- Integrate RLHF to reward appropriate refusals
- Combine with RAG systems for evidence-aware answering
- Add adversarial and jailbreak testing
Our long-term goal is to make “I don’t know” a first-class capability in deployed language models—not an afterthought.

Log in or sign up for Devpost to join the conversation.