
🚀 Failure Archive
Failure Archive is a research-grade platform for documenting, sharing, and learning from failed projects, experiments, and ideas.
Instead of hiding failure, it turns it into structured, reusable knowledge so others can avoid repeating the same mistakes.
What didn’t work — and why.
🧠 Inspiration
Most platforms celebrate success and quietly erase failure.
In reality:
- Failed research rarely gets published
- Failed startups disappear without documentation
- Failed technical experiments vanish with repos
This creates massive duplicated effort.
The same incorrect assumptions are tested again and again.
Failure Archive exists to capture negative results, invalidated hypotheses, and broken assumptions — before they’re lost.
💡 What It Does
Failure Archive allows users to submit failed work using structured, hypothesis-driven forms.
Each submission captures:
- What was attempted
- The original hypothesis
- Where it failed
- What assumption proved false
- What knowledge can still be reused
This reframes failure as data, not storytelling.
🎯 Core Features
Structured Failure Documentation
Template-based submission forms that enforce clarity:
- Hypothesis
- Method
- Failure point
- Key misunderstanding
- Salvageable knowledge
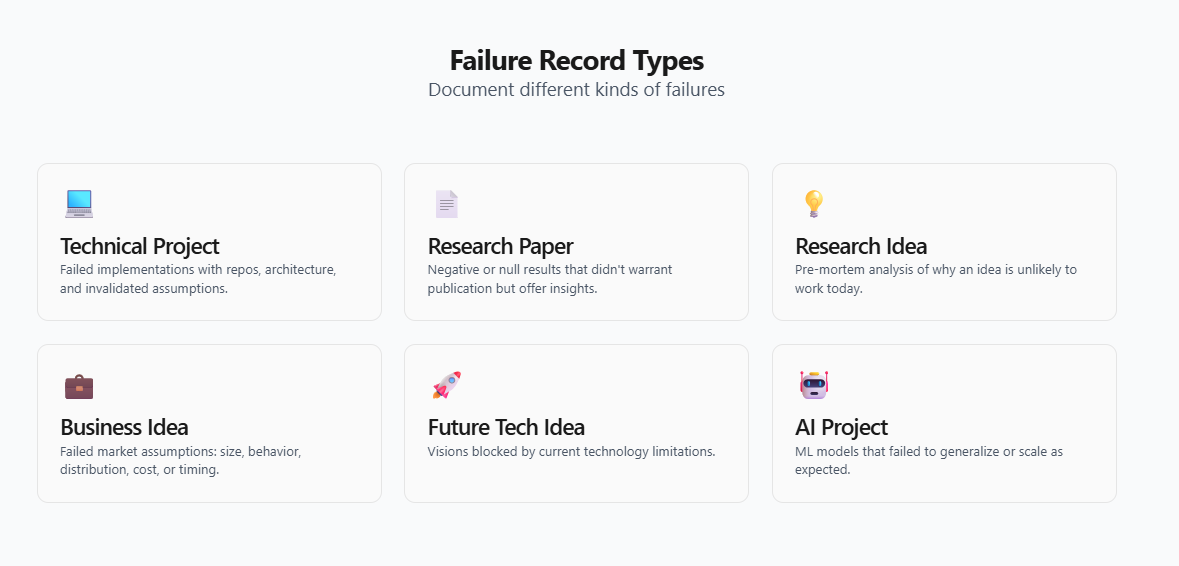
Multiple Submission Types
Users can submit:
- Technical projects (GitHub required)
- Research papers (negative / null results)
- Research ideas (pre-mortems)
- Business ideas
- AI projects
- Future tech concepts
Smart Identity Modes
Each submission supports:
- Anonymous
- Pseudonymous
- Attributed
- Time-delayed attribution (30 / 90 / 180 days)
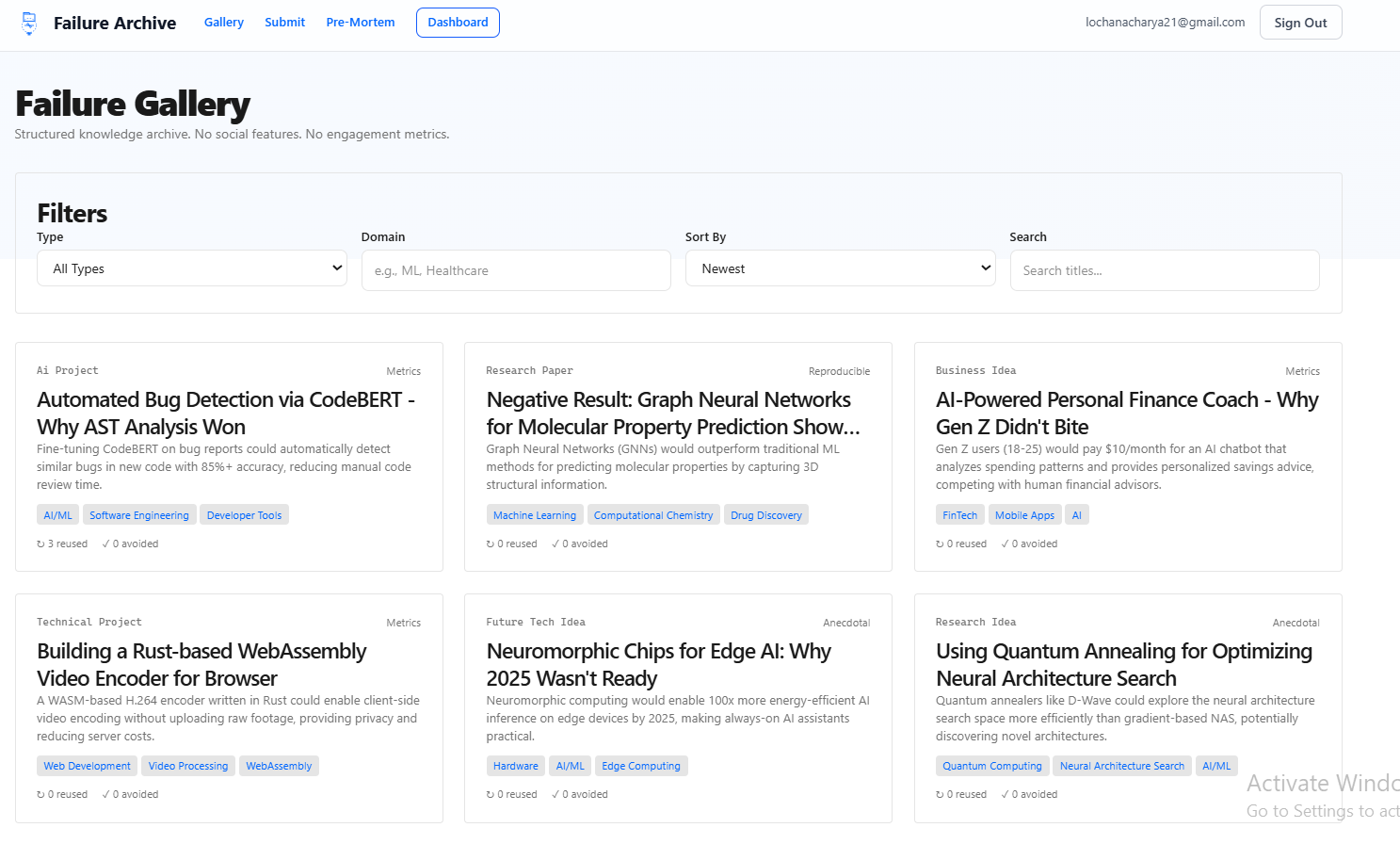
Public Failure Gallery
Browse documented failures using filters:
- Domain
- Failure mechanism
- Evidence level
- Project type
No likes. No comments. No social feed.
Reusability Tracking
Instead of engagement metrics:
- Mark failures as “learned from”
- Track real impact, not popularity
🔐 Authentication & Security
- GitHub OAuth
- Google OAuth
- Secure session management via NextAuth.js
- Role-based access:
- Public viewing
- Authenticated submission
- Author-only editing
🤖 AI-Assisted Features (Optional)
AI Moderation
Screens submissions for illegal or suspicious contentKnowledge Extraction
Normalizes hypotheses and auto-tags failure patterns
AI assists with safety and structure — it does not judge correctness.
🛠️ Tech Stack
- Framework: Next.js (App Router)
- Language: TypeScript
- Database: PostgreSQL (Neon)
- ORM: Prisma
- Authentication: NextAuth.js
- Styling: Tailwind CSS
- Deployment: Vercel-ready
📜 Licensing (Critical Design Choice)
All user submissions are openly licensed:
- Text content: CC0 1.0 (Public Domain)
- Code references: MIT License
Each submission requires explicit license acceptance, ensuring failures can be safely reused, cited, and built upon.
🚧 Challenges We Faced
- Encouraging honesty without social risk
- Avoiding performative “failure stories”
- Designing structure without oversimplifying complex failures
- Balancing anonymity with credibility
🔮 What’s Next
- Pre-mortem analysis for new ideas
- Failure pattern analytics across domains
- Academic citation support for negative results
- Adoption by labs, incubators, and universities
🌍 Why It Matters
Failure Archive captures the work that usually disappears.
Not for motivation.
Not for clout.
But for collective progress.
🧭 Philosophy
This is not a social network.
- No likes
- No comments
- No engagement metrics
Failure is treated as invalidated assumptions, not personal shortcomings.
Built With
- github-oauth
- google-oauth
- next.js
- nextauth.js
- node.js
- openai-apis-(optional)
- postgresql-(neon)
- prisma
- react
- tailwind-css
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.