-
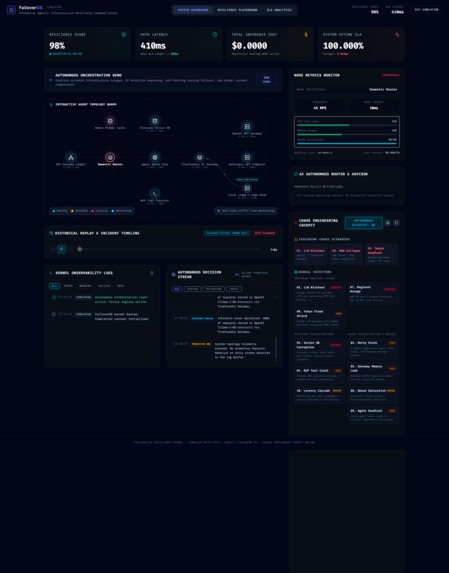
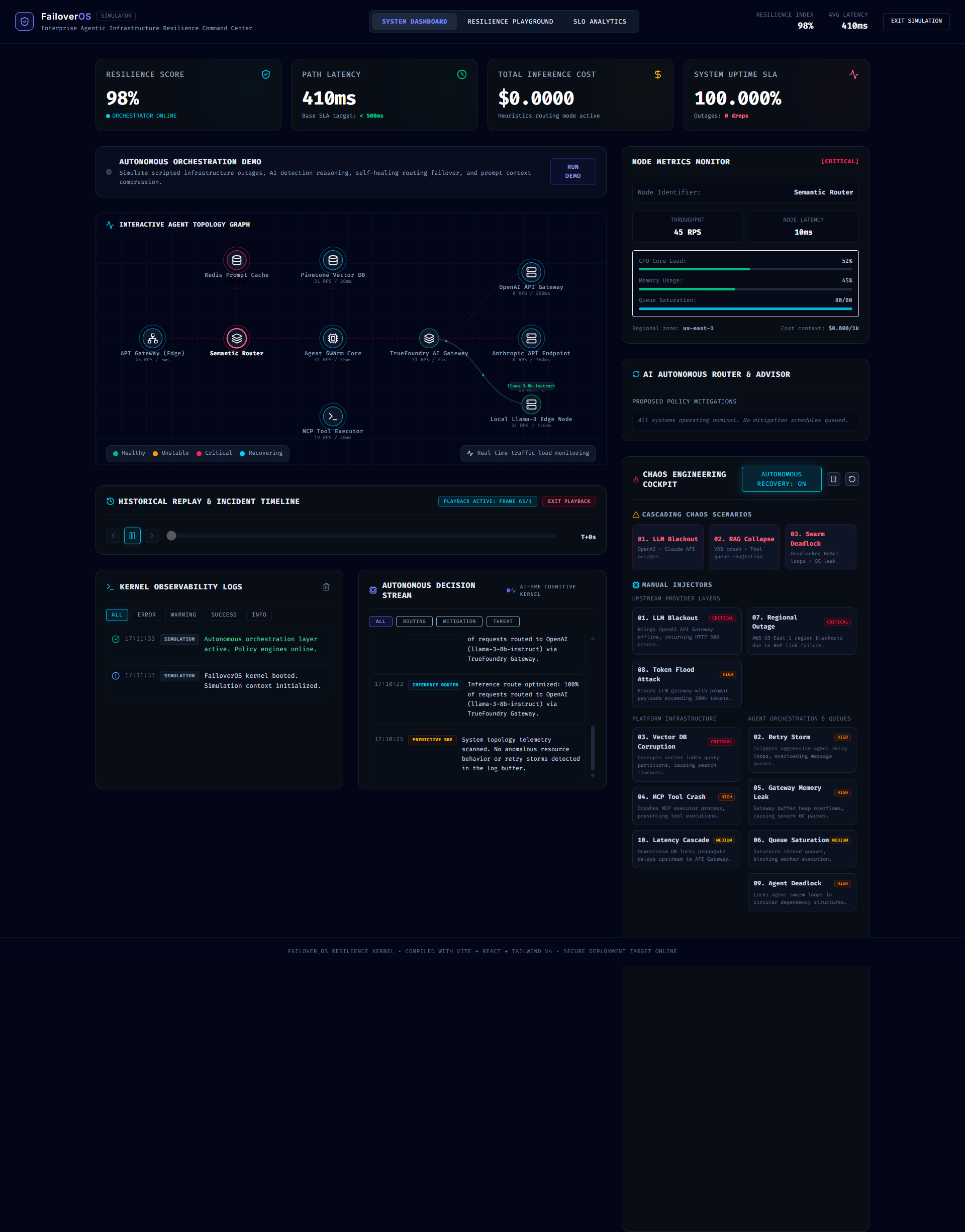
SYSTEM DASHBOARD
-
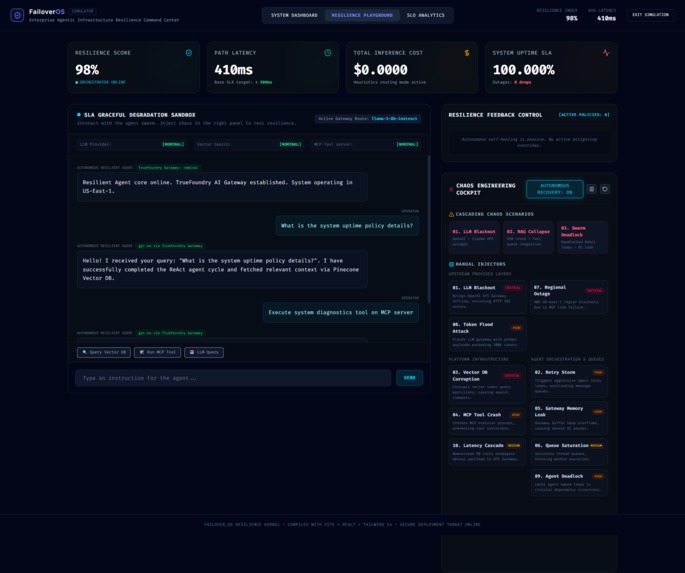
RESILIENCE PLAYGROUND
-
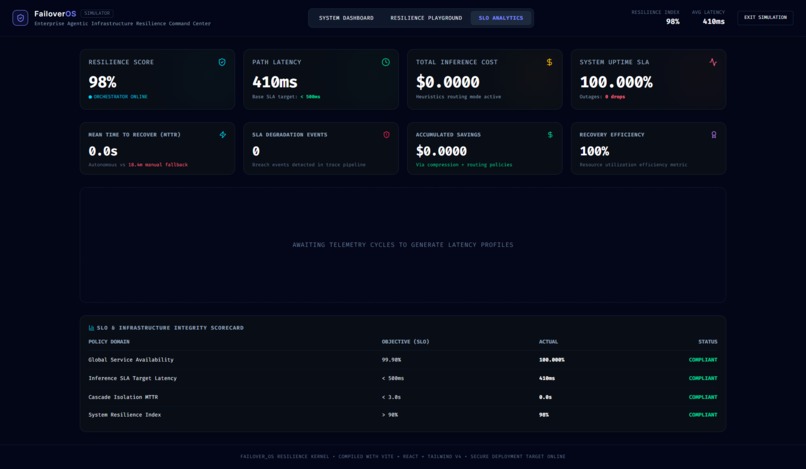
SLO Analytics
Inspiration
Modern AI systems are becoming increasingly autonomous — but their infrastructure is still fragile.
LLM outages, retry storms, MCP failures, vector database corruption, and cascading latency spikes can rapidly destabilize entire AI workflows. Most observability tools only react after failures happen, and very few systems are designed specifically for AI-native infrastructure resilience.
We wanted to explore a different idea:
What if AI infrastructure could detect instability, simulate failure propagation, and autonomously recover itself in realtime?
That became the foundation for FailoverOS — an autonomous resilience layer and chaos-engineering platform for AI systems.
What it does
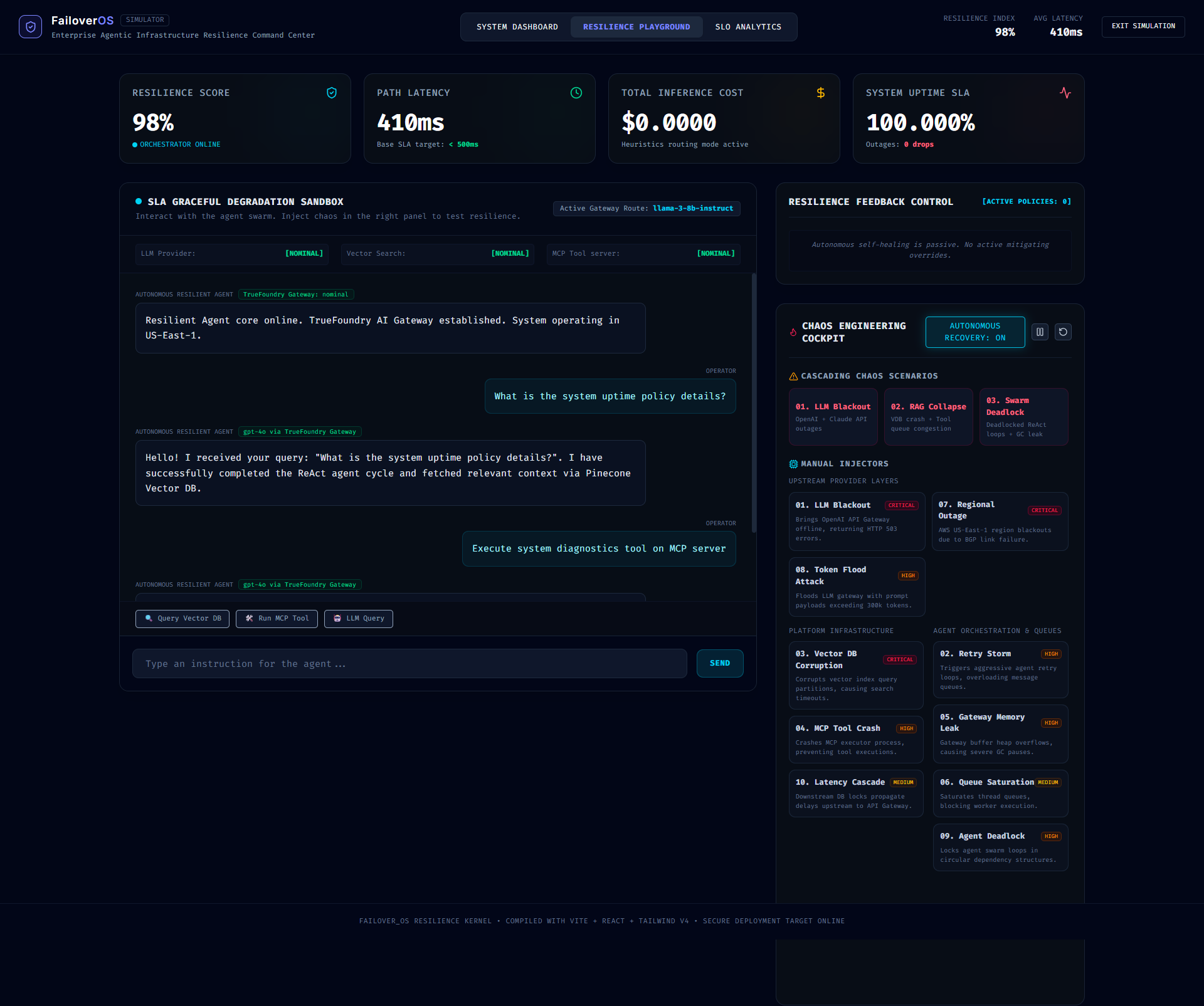
FailoverOS is a realtime AI infrastructure simulation and orchestration platform designed to model, visualize, and mitigate infrastructure failures across modern AI pipelines.
The platform allows users to:
- simulate infrastructure outages,
- inject cascading failures,
- observe realtime degradation,
- monitor SLA instability,
- and autonomously recover systems using intelligent orchestration policies.
The system models infrastructure as a distributed orchestration graph consisting of:
- LLM providers,
- vector databases,
- MCP servers,
- API gateways,
- orchestration layers,
- and local edge inference nodes.
When failures occur:
- retries amplify,
- queue congestion spreads,
- latency spikes,
- nodes destabilize,
- and resilience scores degrade dynamically.
FailoverOS then activates autonomous recovery strategies including:
- fallback routing,
- provider isolation,
- inference rerouting,
- queue balancing,
- graceful degradation,
- and local edge model activation.
How we built it
Frontend
We built the frontend using:
- Next.js
- TypeScript
- TailwindCSS
- Framer Motion
- React Flow
The UI was designed to resemble a futuristic infrastructure operations center with:
- realtime topology graphs,
- animated failure propagation,
- SLA monitoring,
- resilience scorecards,
- chaos engineering controls,
- and incident replay systems.
React Flow was used to build the distributed infrastructure graph, while Framer Motion handled:
- node transitions,
- instability pulses,
- routing animations,
- and recovery sequences.
Backend & Simulation Engine
The backend orchestration layer was designed using:
- FastAPI
- WebSockets
- Redis
- asynchronous event pipelines
We created a centralized event simulation engine responsible for:
- propagating infrastructure failures,
- coordinating cascading events,
- triggering recovery policies,
- updating node health states,
- and streaming realtime telemetry to the frontend.
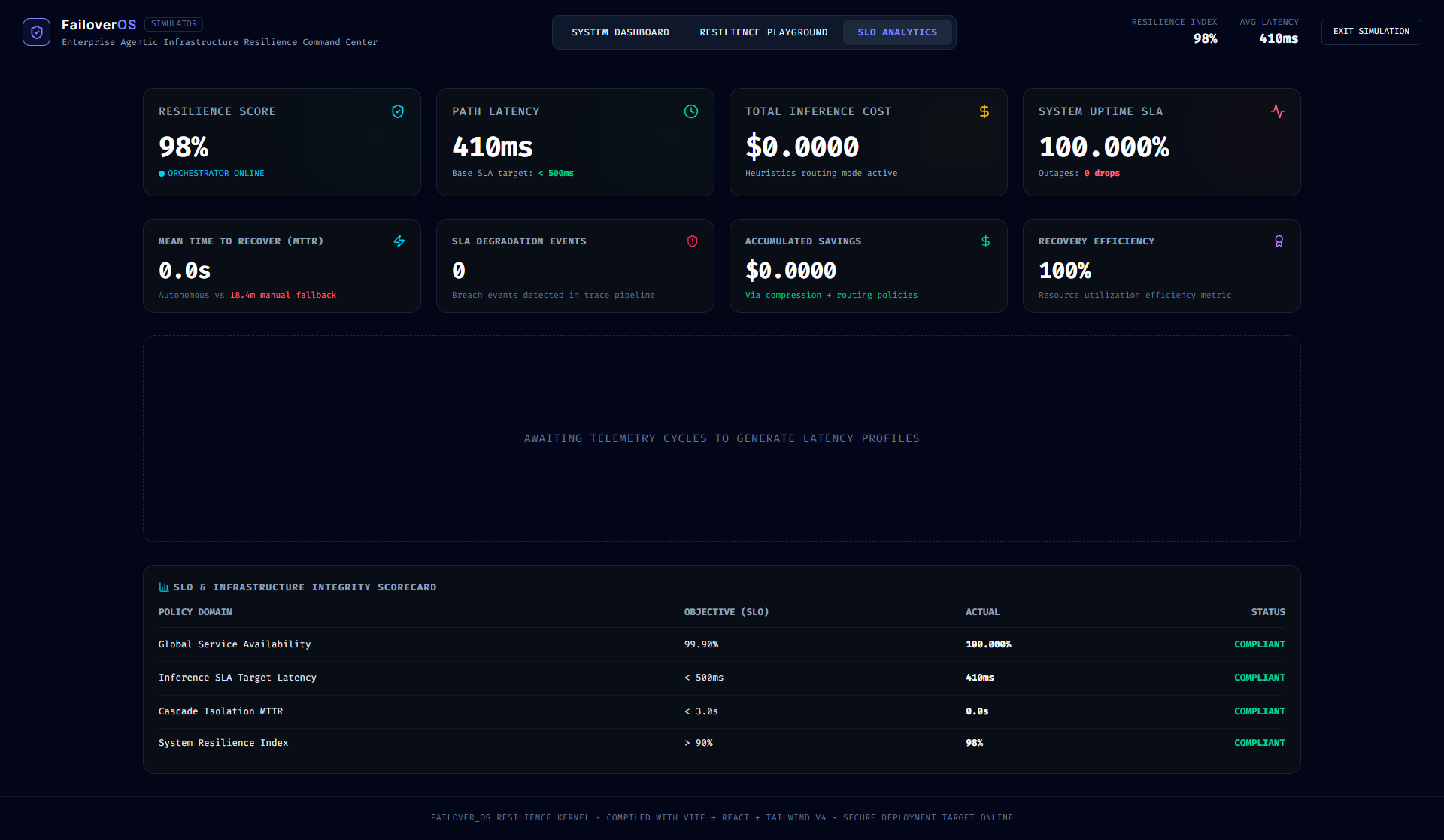
The system continuously calculates:
- resilience score,
- MTTR,
- outage probability,
- SLA degradation,
- queue saturation,
- and inference latency.
AI & Recovery Logic
Rather than building a generic chatbot, we focused on infrastructure intelligence.
We implemented:
- anomaly scoring,
- instability estimation,
- temporal failure propagation,
- adaptive routing policies,
- and autonomous mitigation logic.
The platform simulates realistic recovery strategies such as:
- switching to local edge inference,
- rerouting traffic,
- reducing context payload size,
- isolating unstable nodes,
- and redistributing orchestration load.
Challenges we ran into
One of the biggest challenges was making the infrastructure feel alive instead of static.
A normal dashboard was not enough.
We spent significant time building:
- cascading node failures,
- realtime propagation effects,
- dynamic telemetry,
- replay systems,
- and orchestration visualizations that communicated infrastructure stress intuitively.
Another challenge was balancing:
- visual sophistication,
- realtime responsiveness,
- and frontend performance.
Because the topology graph updates continuously, we had to carefully optimize animations and event propagation to avoid UI instability.
Designing believable infrastructure behavior was also difficult. We wanted the system to feel technically realistic without exaggerating impossible AI capabilities.
Accomplishments that we're proud of
We are especially proud of:
- the realtime topology orchestration graph,
- autonomous recovery visualization,
- cascading failure simulation engine,
- SLA degradation sandbox,
- and the cinematic infrastructure experience.
The system feels closer to a live AI operations platform than a traditional hackathon dashboard.
What we learned
During development we learned a lot about:
- distributed systems behavior,
- infrastructure resilience,
- event-driven architectures,
- orchestration pipelines,
- realtime visualization systems,
- and chaos engineering concepts.
We also learned how important presentation and system behavior are when communicating technical complexity visually.
What's next for FailoverOS
We believe AI-native infrastructure resilience will become increasingly important as autonomous agents scale.
Future directions for FailoverOS include:
- real provider integrations,
- Kubernetes orchestration support,
- predictive infrastructure analytics,
- distributed multi-region recovery,
- and autonomous infrastructure policy learning.
Our long-term vision is to explore how future AI systems can become operationally resilient even during large-scale infrastructure instability.
Built With
- ai
- chaos
- docker
- engine
- engineering
- event
- fastapi
- flow
- infrastructure
- next.js
- python
- react
- redis
- simulation
- tailwindcss
- typescript
- vercel
- websockets

Log in or sign up for Devpost to join the conversation.