Inspiration
I bombed my first real job interview. Not because I didn't know the answers — I did. I bombed it because I had never practiced being in that room. The pressure, the silence after a weak answer, the follow-up question when you thought you'd nailed it.
There is no safe place to fail at a job interview before you do one for real. You can read guides. You can rehearse in a mirror. Neither of those things push back on you.
FailForward exists because the only way to get good at high-stakes conversations is to have high-stakes conversations — and we built the only place where you can do that without real consequences.
What it does
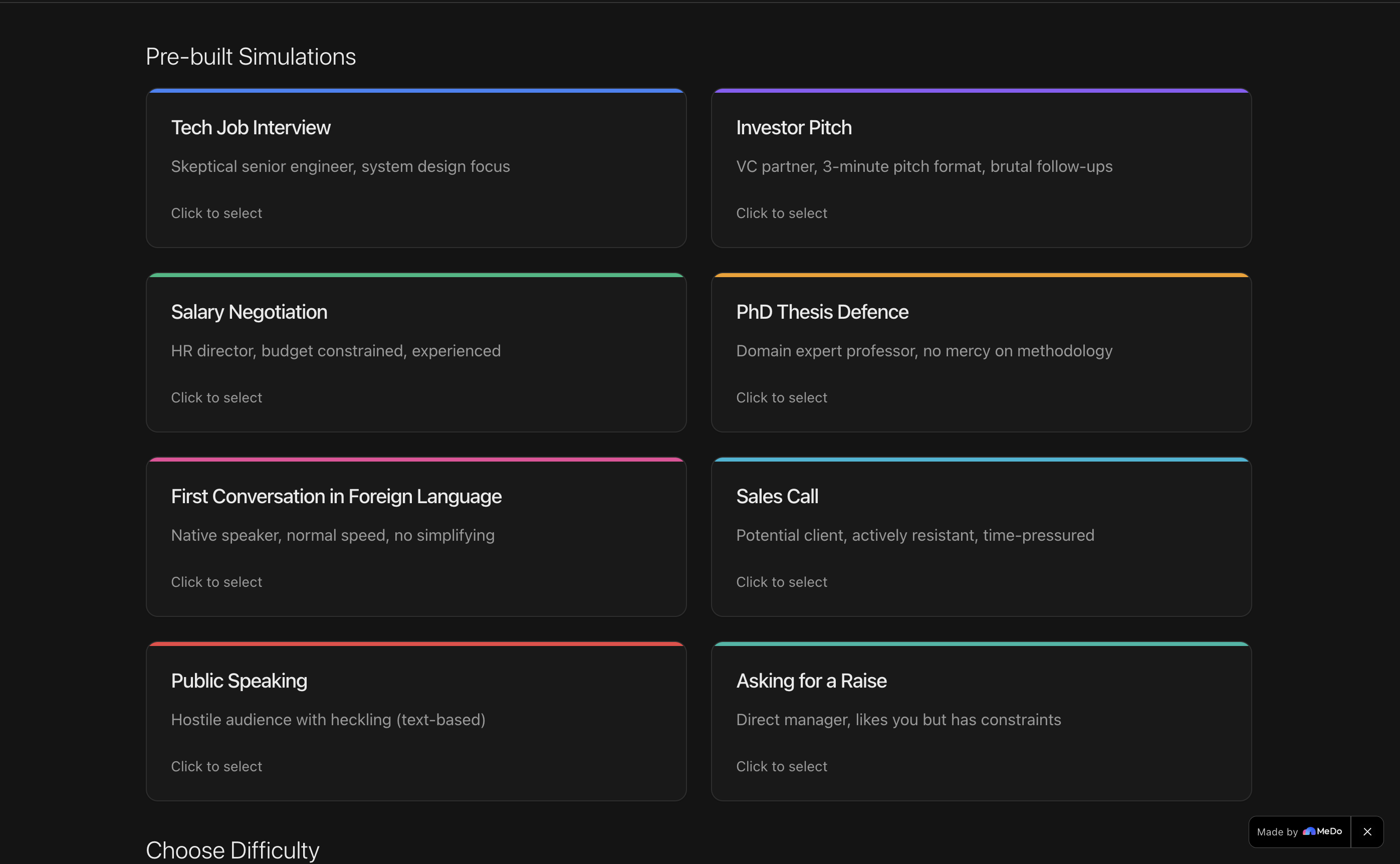
FailForward simulates 8 high-stakes real-world scenarios: job interviews, investor pitches, salary negotiations, PhD thesis defences, foreign language conversations, sales calls, public speaking, and difficult personal conversations.
The AI plays the other person — fully in character, no hints, no encouragement, no mercy. A skeptical senior engineer. A VC who has heard 1,000 pitches. A professor who knows your methodology has a flaw.
After 6-10 exchanges the session ends and you get a structured debrief:
- Three scores: Clarity, Confidence, Recovery (each 0-10)
- Turn-by-turn annotation of every exchange
- The single biggest mistake and the single best moment
- An honest verdict
The scoring follows a weighted performance model:
$$S_{final} = \frac{w_c \cdot C + w_k \cdot K + w_r \cdot R}{w_c + w_k + w_r}$$
where $C$ = Clarity, $K$ = Confidence, $R$ = Recovery, and weights $w$ are scenario-specific.
You can then replay from any exact moment — forking the conversation with full prior context preserved.
The custom scenario builder lets you describe a specific real person and situation. "My actual boss, in my performance review next Thursday" — that's personal rehearsal, not generic practice.
How we built it
Built entirely using MeDo — conversationally, in four turns.
Turn 1: Described the core simulation engine — 8 scenario types, character rules (no breaking character, no hints), tension meter, session length. MeDo generated the full-stack app.
Turn 2: Added the debrief and replay system — turn-by-turn annotation, three-score model, branch-and-retry from any moment with context preserved.
Turn 3: Added difficulty levels (Easy to Nightmare), progress dashboard with score tracking over time, and the shareable failure card generator.
Turn 4: Added the custom scenario builder and community scenarios library.
Total build time: approximately 3 hours.
Challenges we ran into
Calibrating AI resistance. Too soft and the simulation is useless. Too hard and users disengage before learning. The fix was defining the character's motivation precisely: the interviewer wants to hire someone, they just aren't convinced yet. That framing produces the right pressure without feeling punishing.
Branch and replay context management. When a user forks from turn 4, the AI must remember the emotional arc of turns 1-3 while running a new branch. Getting MeDo to maintain this state correctly took two prompt iterations.
Tension meter calibration. The score needed to feel fair, not arbitrary. We landed on a weighted pattern-detection system — vague language, passive constructions, and defensive framing each carry specific penalty weights.
$$T_{score} = 50 + \sum_{i=1}^{n} \Delta_i$$
where $\Delta_i \in [-15, +15]$ per exchange based on response quality signals.
Accomplishments that we're proud of
The custom scenario builder is the feature we're most proud of. "My actual boss in my performance review next Thursday" stops being a generic practice tool — it becomes personal rehearsal for the exact conversation the user is dreading.
The branch-and-replay system is technically the deepest feature. Forking a live conversation at any moment, with full emotional context preserved, required careful multi-turn state management.
The AI never breaks character. Ever. That constraint — enforced from the first prompt — is what makes the simulation actually useful.
What we learned
Character constraint is product design. Deciding the AI will never break character sounds like a technical decision. It is actually a product philosophy: the value of the simulation depends entirely on its fidelity.
The debrief is as important as the simulation. Early versions ended the session and gave a score. Users didn't know what to do with a number. The annotated turn-by-turn debrief — "here, specifically, is the moment you lost the room" — is what actually changes behaviour.
Vibe coding is a real skill. The constraint of describing everything in plain English forces you to think like a product manager before you think like a developer.
What's next for FailForward
- Voice mode: speak your answers, AI responds verbally — for scenarios where tone matters as much as words
- Community scenario library growth: user-submitted templates rated by usage, building a library of real high-stakes situations
- Cohort practice: two users simulate together, one plays the interviewer, AI referees and debriefs both
- Certification: complete 5 sessions in a scenario type with improving scores, earn a shareable FailForward Certified badge

Log in or sign up for Devpost to join the conversation.