Inspiration
Upon hearing of the challenge regarding media and misinformation, the vast amount of email forwards and Facebook shares from my relatives with completely made up stories instantly came to mind. Thus the idea of a browser extension that checks headlines to verify weather or not its article is infact a real article or not.
What it does
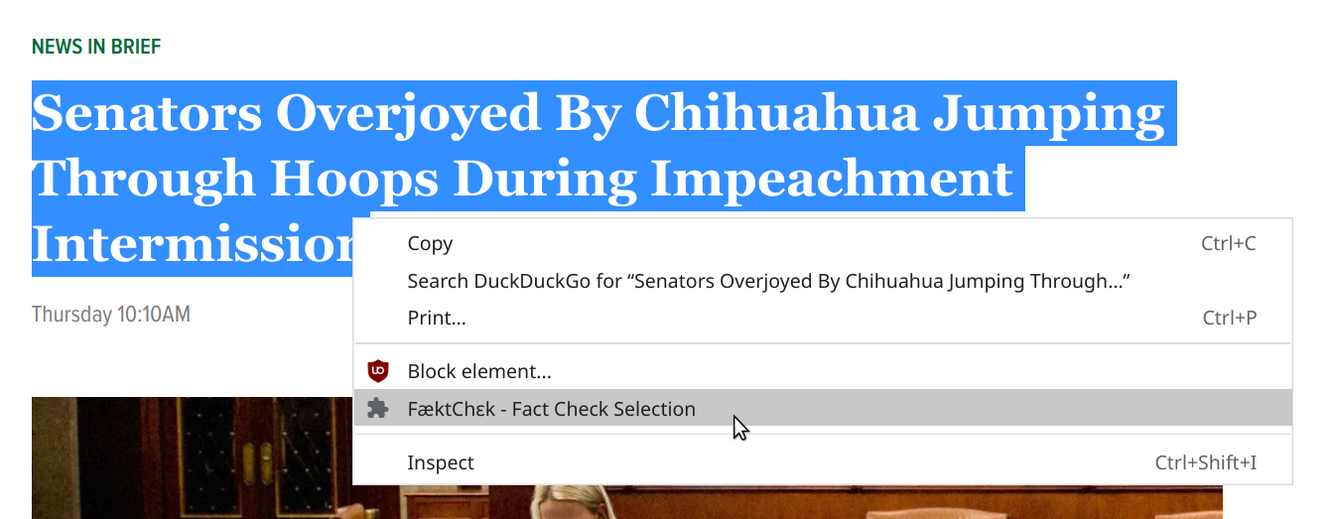
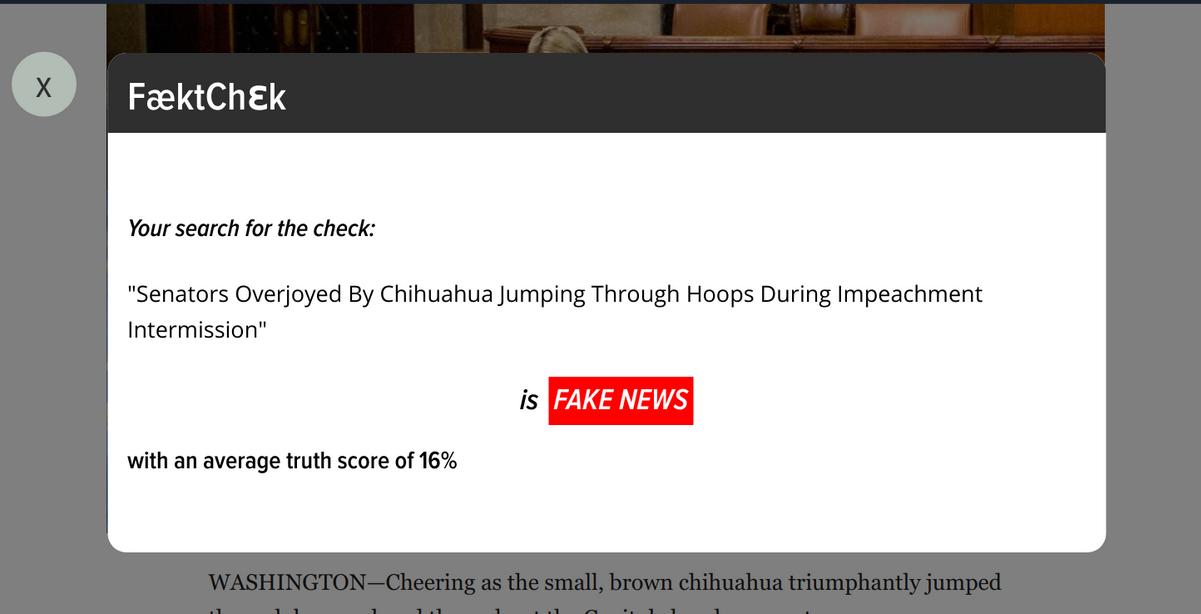
This amazing extension works by first waiting for the client to highlight a heading on the article, then right clicking to bring up the context menu. On this context menu, "fact check" will be one of the options. Once you click it, it will take the highlighted text and send it to our flask API, where our pretrained tensor-flow model will determine weather or not the headline belongs to a valid article or not. Once it gets that information, a closable pop up comes up letting you know the validity of the article.
How we built it
Data Processing and Machine Learning
First thing we did with the data was read the CSV and put that into an array format. After this we used a
tfidf method to vectorize our headings. This method essentially 'boosts' unique or important words while 'flooring' common ones. Once we vectorized our input all we had to do was make a test/train split and train and test our neural network. We tried many different configurations until we settled on a 5 layer network with relu activation on the first 3 and sigmoid on the last one. This configuration yielded 93% accuracy on our testing data. The next step was to save our vectorization and neural network configuration so that we can use it for when we actually take in the data from the browser. To save the vectorizer we used pickle and to save the model we used tflite.
Server and Front End
Our Server is built using Flask, the main goal of the back-end server is to communicate between the frontend extension, with the ML model. Frontend was build with plain HTML, CSS, and JavaScript. Chrome Extensions are very scaleable when it comes to what tech is used. We figured making a whole React or Angular App for this project was just plain overkill. We found setting up the extension to be surprisingly easy since a single manifest.json is really all you need. The Chrome team had well explained documentation to follow. Not to forget close to a decade of StackOverflow posts at our disposal.
Challenges we ran into
There were a lot of challenges in creating this project. The main challenge was with the machine learning side. It was our first time using tensorflow and keras as well as text based machine learning models. We overcame this challenge by doing TONS of research and finding and trying out all kinds of solutions from stack overflow, documentation and people who have tried similar projects. The other challenge was with saving the model and vectorizer to be used again later (so that weights don't have to be computed everytime). We tried it ourselves but nothing worked so we found a lot of documentation with pickle and tflite which helped a lot with executing that aspect of the project. Another data related challenge was getting CUDA to work on my friends nvidia gpu. After a ton of restarts and reinstalls and forums we got it to work, which allowed us to have a much smaller strain on our computation of our model. On the extension side, our biggest hurdle was hosting with the Flask server and Heroku. Because we had large data sets and models, we needed to use Git LFS to upload to GitHub, we soon expired our monthly quota for the repo and had to switch to a fresh one. When attempting to host on heroku, we barely went over the hard limit of 500mb just as a result of all the Python/PIP packages/dependencies and were forced to run the server on localhost.
Accomplishments that we're proud of
We have learned quite a bit from this experience. For example, we learned a lot about how NLP works and how the many algorithms (TFIDF, BOW etc.) and neural networks (CNN, RNN, NN etc.) used for NLP. We also learned how to save and reuse vectorizers and neural network models to drastically save computational time.

Log in or sign up for Devpost to join the conversation.