-
-
home
-
text-entry
-
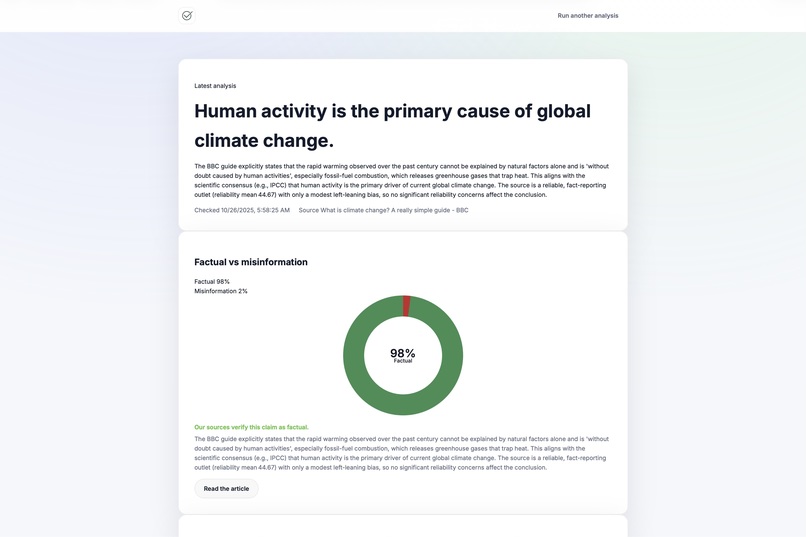
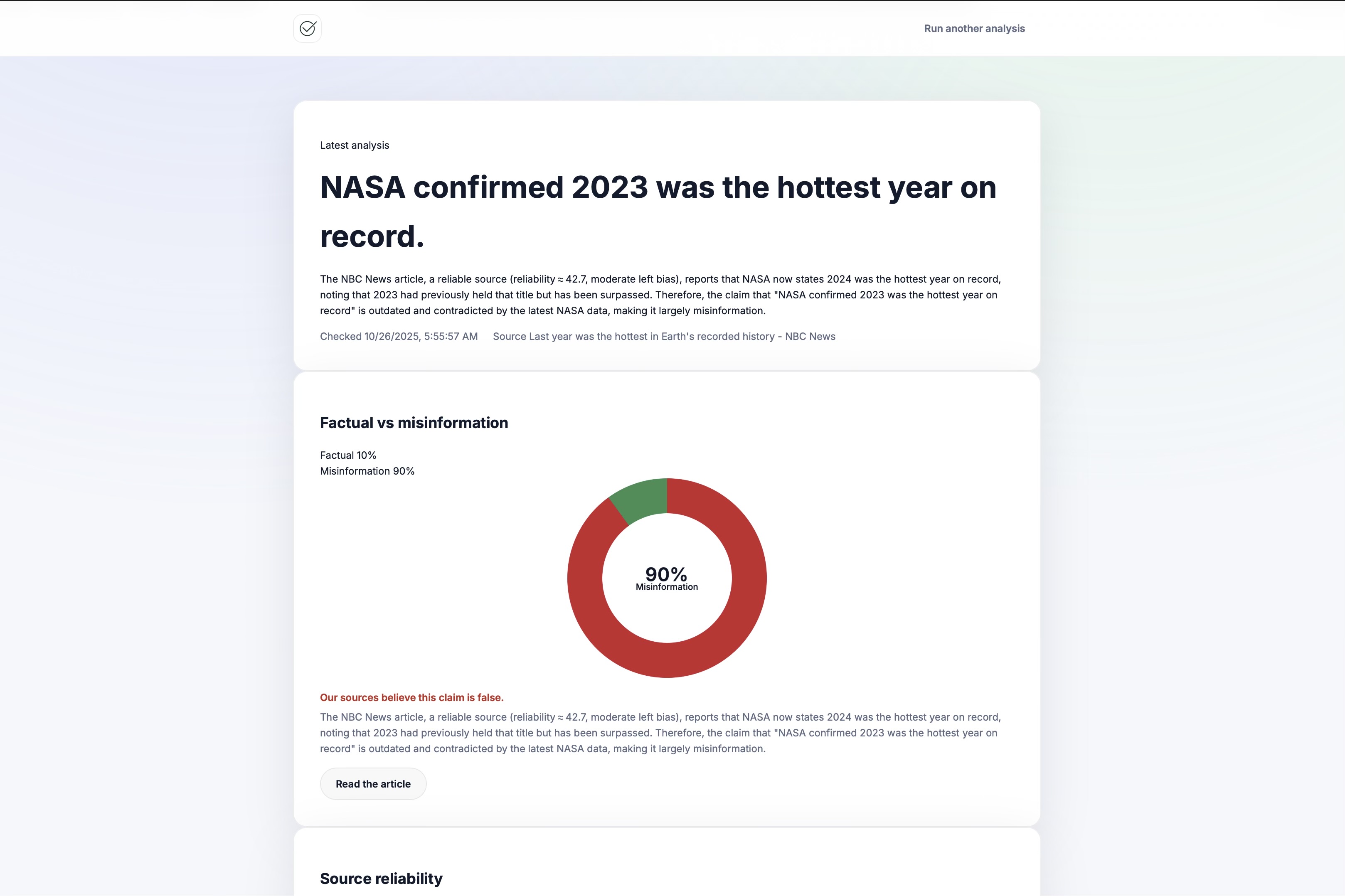
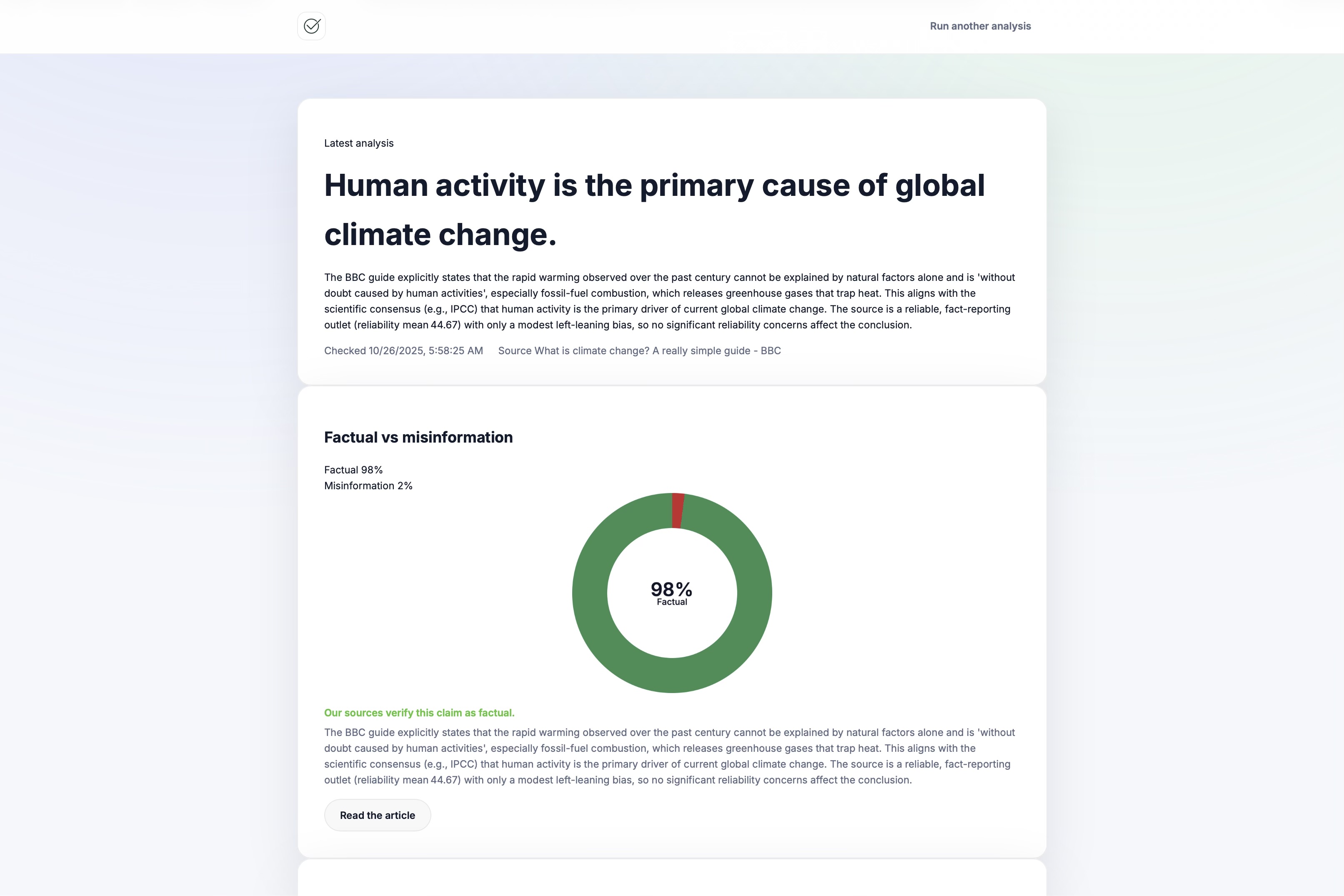
example-response
-
example-response
-
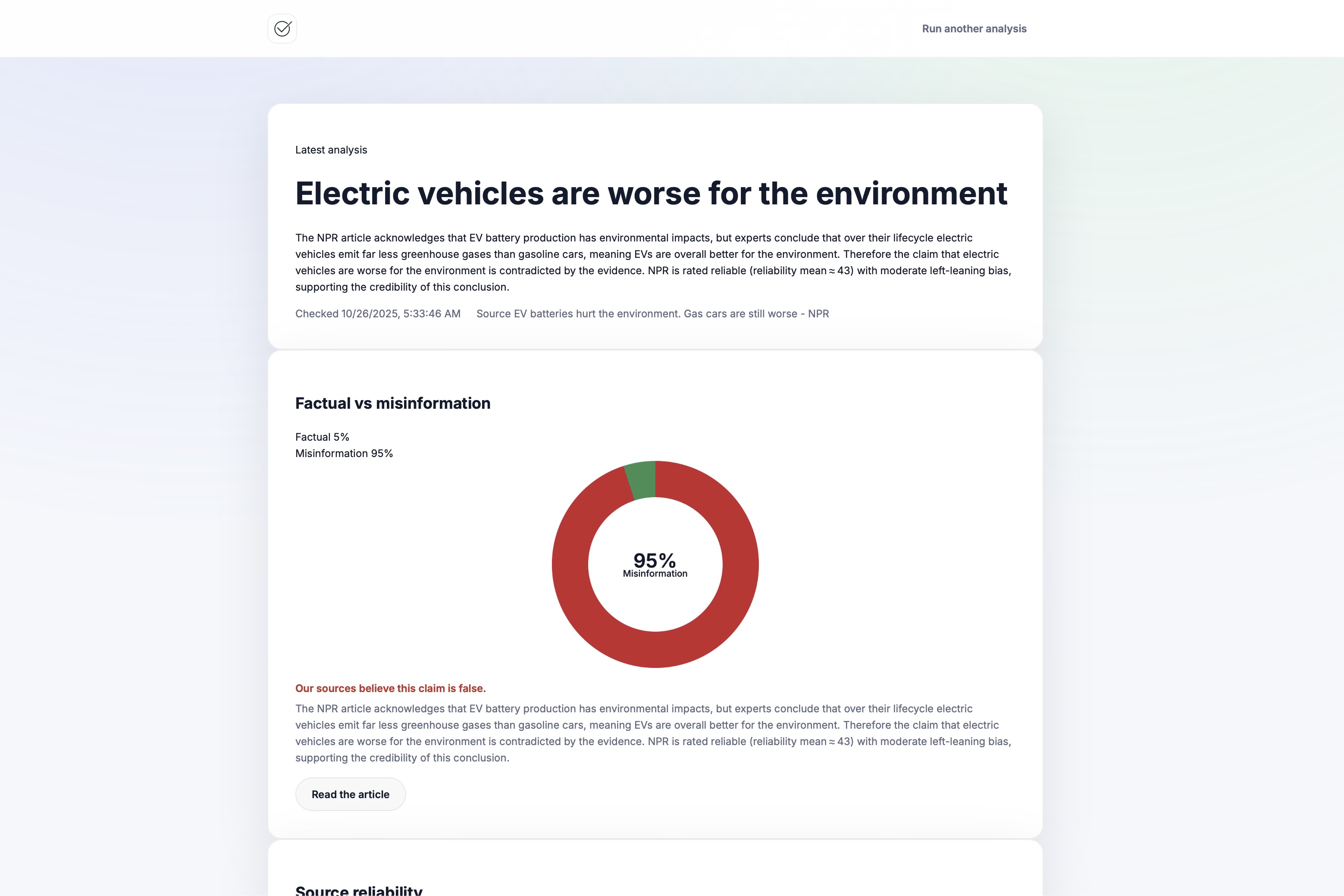
example-response
Inspiration
Nowadays, misinformation spreads faster than truth. While social media has made information more accessible, it’s also made it difficult to know what’s true. With many news channels delivering conflicting reports, we wanted a tool that could quickly verify any claim against trustworthy sources without requiring the user to dig through articles or biased charts. That idea became FactTrace, a real-time, bias-aware AI that cross-references statements from verified sources before rendering a verdict.
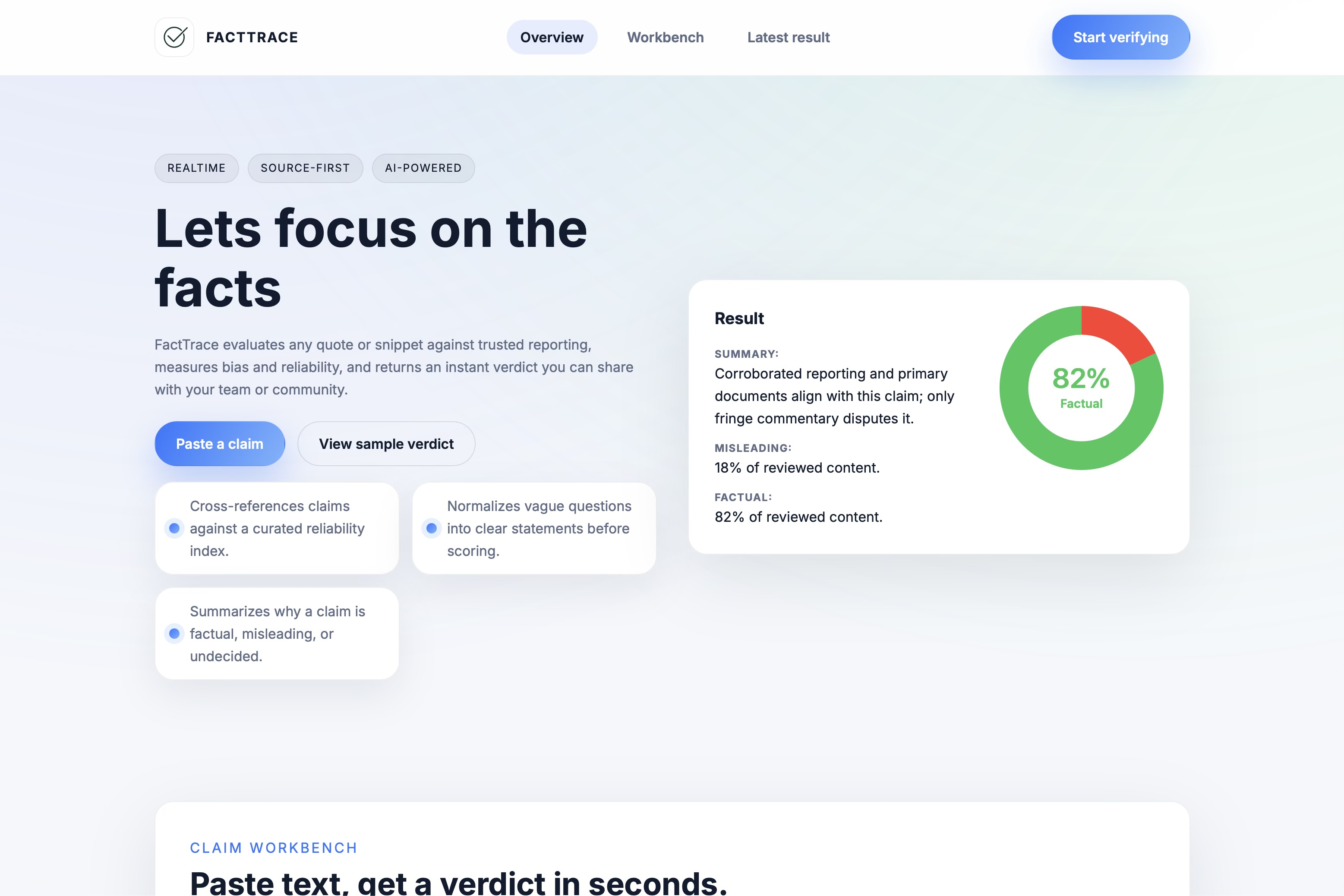
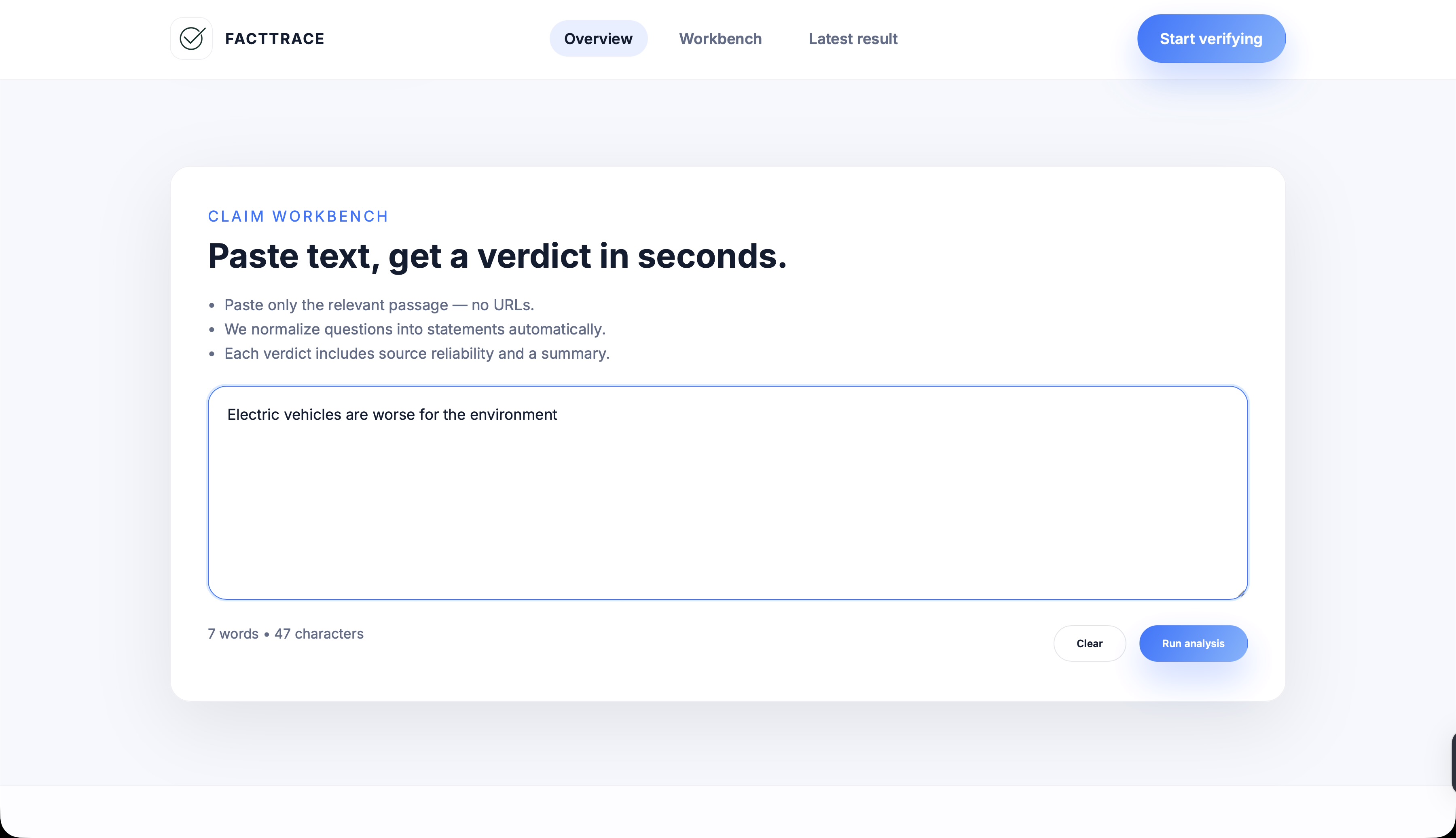
What it does
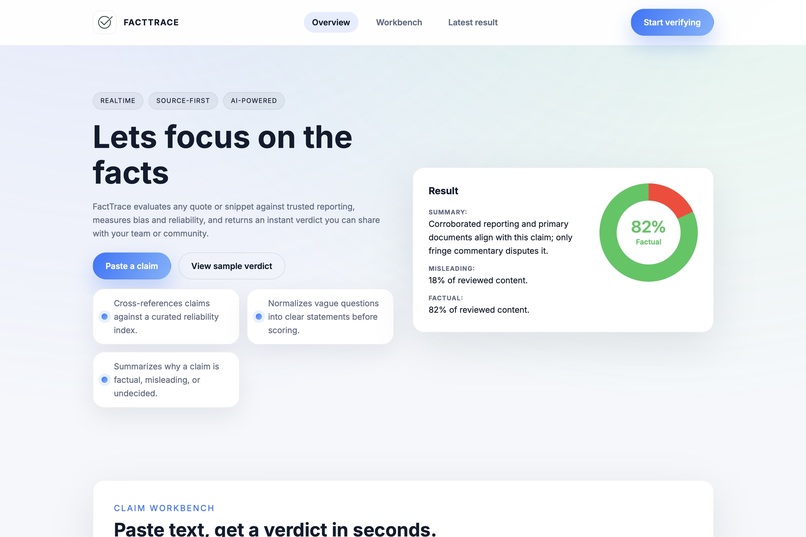
FactTrace takes any short claim or quote and returns:
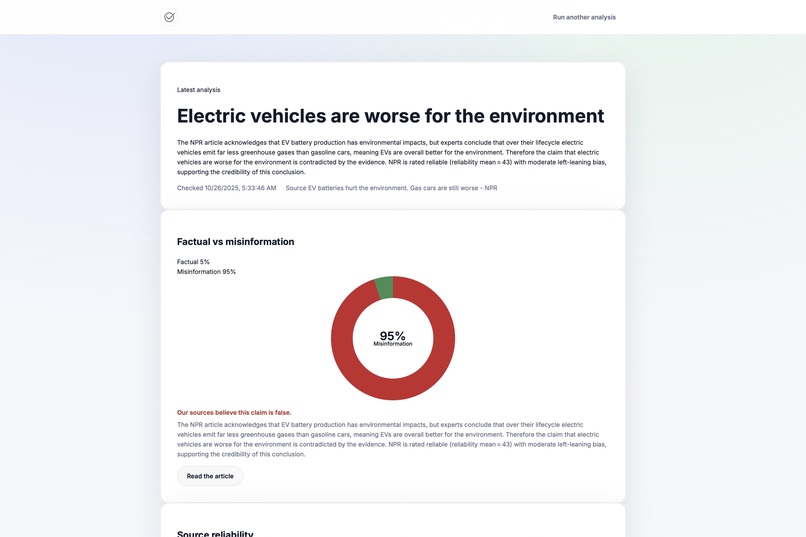
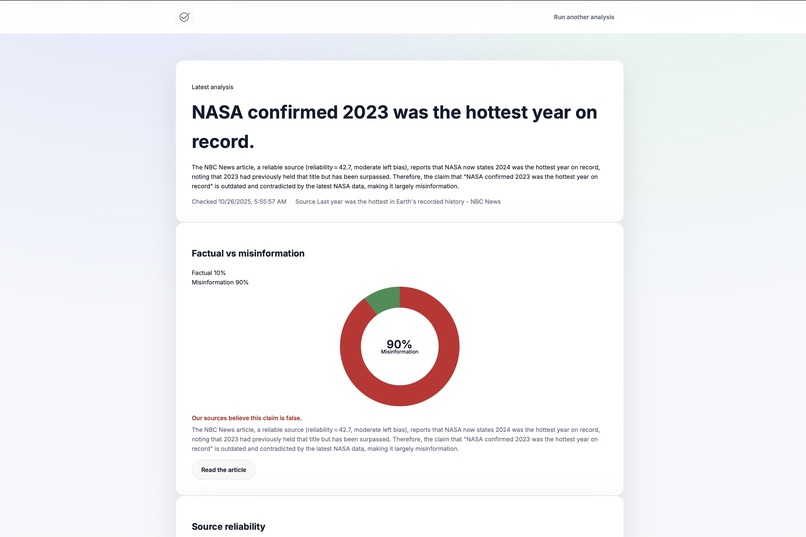
- A verdict split (Factual vs Misleading percentages) and a one‑paragraph rationale.
- A source‑first pipeline that searches current coverage, weights it by bias and reliability, and filters out fringe or low‑quality outlets.
- A clean, shareable UI with a doughnut chart and summary. ## How we built it Frontend
public/index.html,styles.css,scripts.js(no framework, fast to ship).- Chart.js renders the Factual vs. Misleading split with an on‑canvas label for the dominant class.
- Responsive layout, IntersectionObserver scroll effects, and client‑side status handling.
Backend (Node.js, zero‑dependency HTTP server):
- A single
private/index.jsHTTP server that serves static files and exposes:GET /health: liveness probe.POST /api/analyze: main analysis endpoint.
- Search via Exa.ai using
category: "news",useAutoprompt: true, configurablenumResults. - Source reliability using a curated CSV merged into an in‑memory index:
- Enforces
MAX_BIAS_SCORE(10) andMIN_RELIABILITY_SCORE(35). - Matches both publisher names and domains.
- Enforces
- Evidence extraction fetches article bodies, sanitizes boilerplate, and truncates to a guardrail for consistent LLM context.
- Claim normalization converts questions into clear factual statements (e.g., “Is X true?” → “X is true/false, according to …”) before scoring.
- LLM scoring uses the Groq gpt-oss endpoint with a small JSON schema to return
Challenges we ran into
- Source filtering is hard. Many results are paywalled or partisan; matching by both domain and publisher name reduced false positives.
- Latency vs. quality. Live search + fetching + LLM can add up. Caching normalized evidence and keeping prompts lightweight helped.
- Input ambiguity. Natural questions aren’t always verifiable claims. The question into statement normalization step made verdicts more consistent.
- Annoying HTML. Article boilerplate and scripts pollute text, sanitizers, and a character limit kept the context clean and bounded.
Accomplishments that we're proud of
- Built a source‑first fact‑checking system where the LLM is the last pass, not the first.
- End‑to‑end app with no framework on the web side and a compact Node.js server, easy to run and deploy.
- A curated reliability index that’s enforced at query time, not just displayed after the fact.
- UX polish: instant feedback states, chart annotations, and shareable summaries.
What we learned
- Grounded LLMs behave better when upstream data is curated and constrained.
- Simple, explicit thresholds (like bias and reliability) yield predictable outcomes and easier tuning than opaque model heuristics.
- Even lightweight UI details meaningfully improve perceived quality.
- Deterministic decoding and defensive JSON parsing avoid flaky results in real‑time apps.
What's next for FactTrace
- Browser & social media plateform integrations for inline fact‑checks where conversations happen.
- Primary‑source mode to prioritize PDFs, press releases, and datasets when available.
- Verdict provenance export so teams can audit exactly which sources influenced a score.
- Batch mode for newsroom workflows or streaming mode for live events and debates.



Log in or sign up for Devpost to join the conversation.