-
-

Slide 4
-

Slide 5
-

Slide 2
-

Slide 1
-

Slide 3
-

Slide 6
-

Title






Introduction
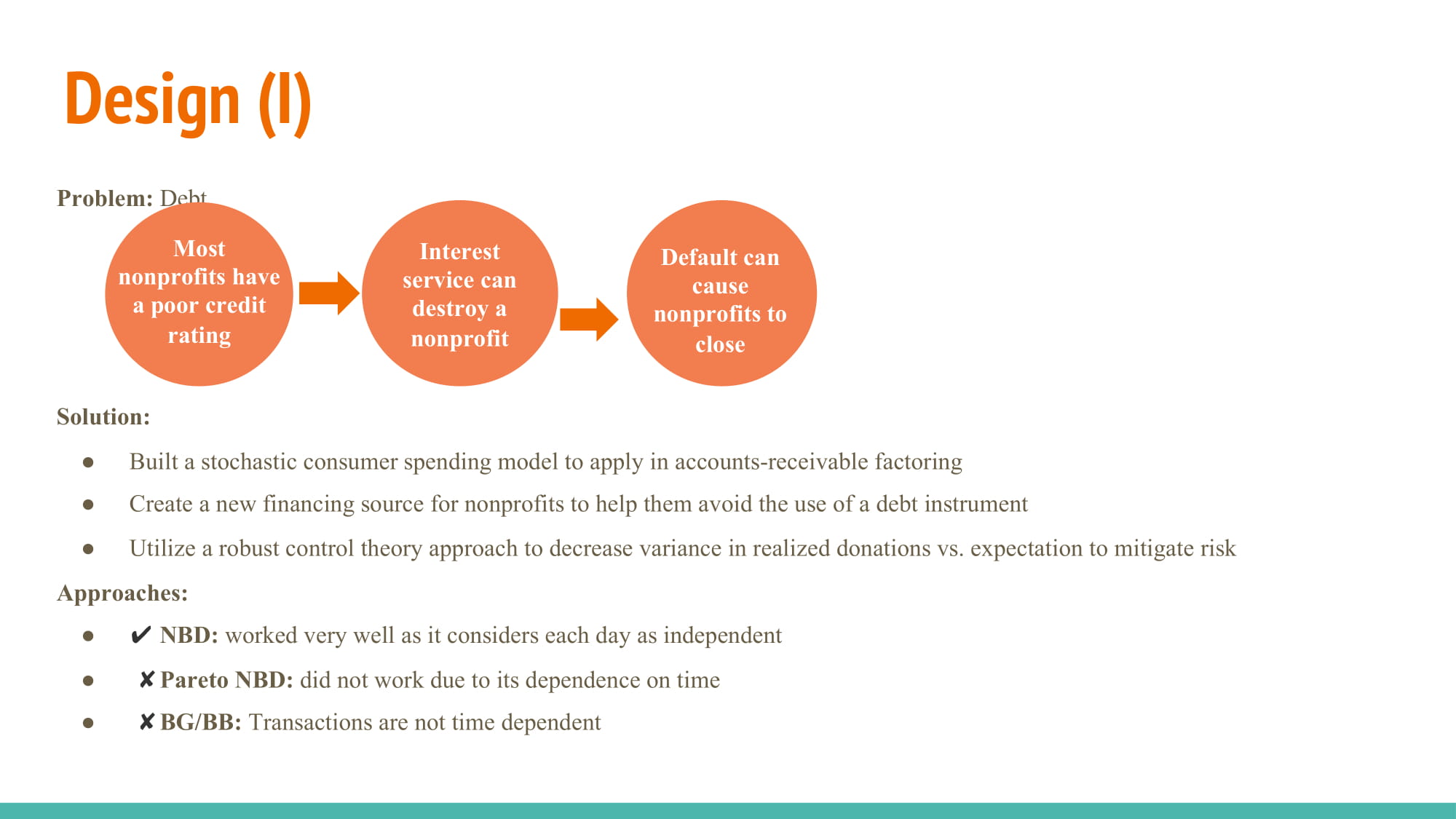
Nonprofits in the US are very skeptical of bank loans. Primarily, this is attributed to their inability to predict donation revenue to repay the loan that they have taken. In addition, banks are highly skeptical when giving loans to small nonprofits for this very reason. As a result, the most common fundraising method of nonprofits is to request large sums from a large donor. While this works relatively well, the large funds often contain spending limitation or clauses that make it difficult to deploy the money where it is needed most. In the last 6 months, Flourish Technologies, has collected a donation dataset that may contain the solution to this problem. Flourish is a micro-donation platform processing thousands of recurring donations per day with an average size of just under $0.57. These small, frequent transactions would, in theory, make predicting donor revenue much easier. We intend to build a stochastic consumer spending model for application in accounts-receivable factoring. This will create a new financing source for nonprofits and avoid the use of a debt instrument. Finally, we will utilize a robust control theory approach to decrease variance in realized donations vs. expectation to mitigate risk.
Problem Statement
Currently, Flourish is generating about 8,000 valuable data points a day; however, we have not yet found a good way to leverage this information for the benefit of our clients. We hope to engineer a probability model, combining material learned in ESE 301, 303 and MKTG 776 to gain insight into our customers mindset. The initial challenge is to understand the donation data and be able to predict future revenue with an extremely high degree of accuracy. Ultimately, this model should stand up to the financial scrutiny of a financial institution.
Collected Data (May, 2018 - Present)
Variables:
- Transaction Difference (Delta)
- Date, Time, Location
- Name of Vendor
- Account
- Identifiable Information (phone, email, age, occupation, name)
- Chosen organization
- Donation preference (round-up, daily donation, both)
- Time on application
- (Stickiness) Time spent reading blog/news through channels
Expected Results
We would like to develop several models: the first, being a very basic autoregressive model to attempt to determine if donations form a self-determined pattern (stationarity? seasonal?). We would consider this a baseline as it will be the most simple form of a predictive model. We then plan to use a more decision based model, looking at daily spending patterns where there is a binomial model determining the likelihood of donating on a given day. Finally, we will include a beta distribution to allow for an individual to give multiple times in one day. Combined, we believe these models will give us really good insight into consumer donation behavior and allow us to predict donation revenue successfully. After creating a baseline prediction model, we will attempt to introduce error by bootstrapping the dataset or algorithmically removing pertinent data points. Doing so will allow us to understand the underlying nature of the behavior patterns instead of depending on the output of a nominal model. Finally, using this new system, we hope to leverage robust control techniques to manipulate the system to achieve desired outcomes with the introduced errors. Then using these models, we would love to deploy capital in test cases to determine the success of these techniques.
Log in or sign up for Devpost to join the conversation.