-
-

factnetic homepage
-
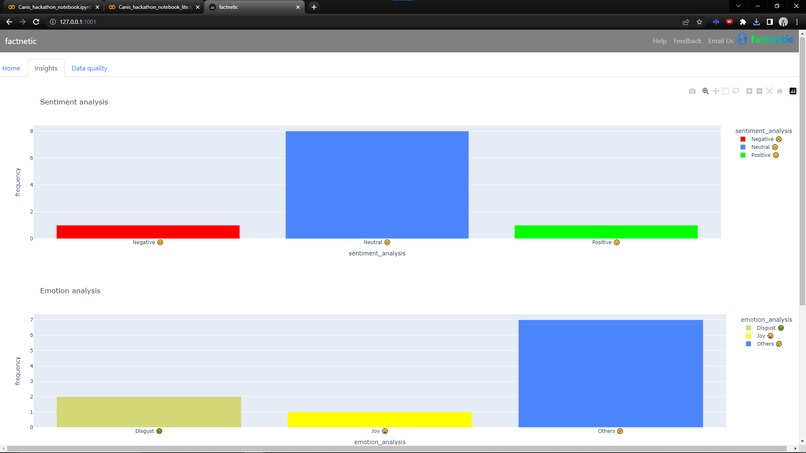
factnetic insights page with sentiment and emotion analysis using ML
-
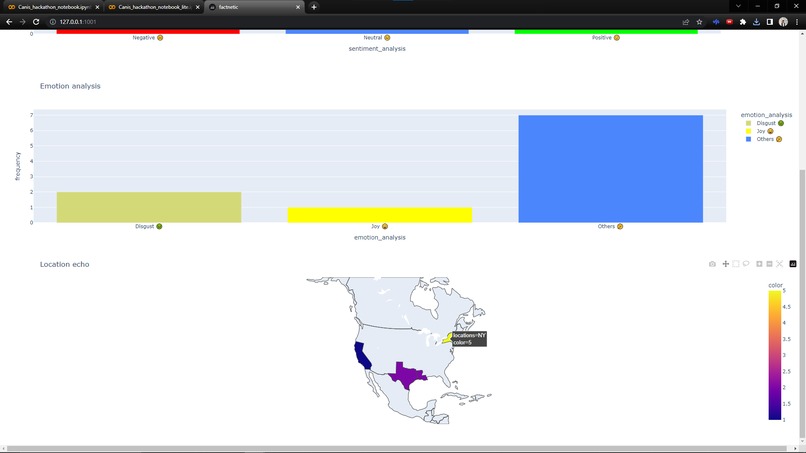
factnetic insights page with location based information
-
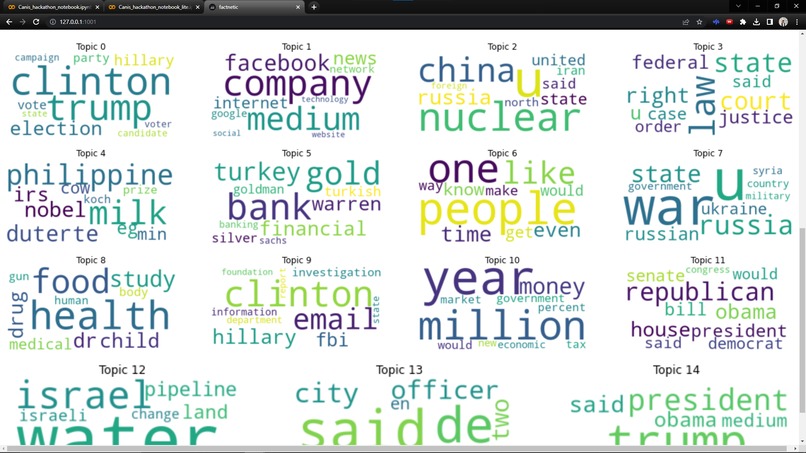
factnetic wordcloud for clustered data topics
-

factnetic data quality check





Inspiration
Factnetic was born from a deep desire to combat the insidious spread of fake news in our society. Our team saw the devastating impact that misinformation could have on individuals and entire communities. We were inspired to create a solution that could separate fact from fiction in a lightning-fast and accurate way, empowering people to make informed decisions and take action based on reliable information. We poured our hearts and minds into this project, determined to build a tool that could make a real difference in the fight against fake news. Factnetic is more than just a data model – it's a passion project that we hope will positively impact the world.
What it does
Factnetic is a cutting-edge data model that delivers lightning-fast insights, separating fact from fiction with unparalleled accuracy; the key outputs we have obtained from the size data is roughly 78617 before pre-processing are as follows:
- Top words within the most optimized number of topics in the dataset(Here, the most optimized we calculated with the topic with the best coherence score)
- Sentiments Analysis
- Hate Speech Analysis
- Geo-location based on occurrence in the text (city and country mention frequency)
How we built it
The building of the model was actually as diverse and exciting as the data set we had; we have taken initially two provided datasets within koggle; the initial two csv considered in the model are the fake news and true news file that were concatinated providing binary label(T_F_Score), where 0 we assigned to fake and 1 to trustworthy information.
Part 1: Data Cleaning Initially, the data was just having a lot of irregularities, so we manually performed the data cleaning consisting of the following steps: (Why didn't we use the pre-built library?: it was taking more computation, and we wanted the model to be less resource intensive)
- Text conversion to lowercase
- Removal of nonwords and extra spaces in the text
- Removal of stopwords
- Dopping duplicates (surprisingly, there were few overlapping rows found that were dropped)
- Removal of links in the text and exchanging of emojis with connected sentiment
- lemmatization(Not stemming as we wanted words not to lose meaning in the context)
Part 2: Topic Modeling To find the relevant topics and construct an associated wordcloud, we have chosen the traditional approach of topic modeling that includes:
- Vectorising text to make a bog
- Defining the corpus
- Applying LDA
- Finding the optimal number of topics through finding coherence over the topic points from 5 to 50. (The task took nearly 2 hours to execute)
- finding perplexity over the topic (for our data set optimal number of topic turned to be 40, while coherence is 0.51039. and perplixity is -12.895 for the topic) Interestingly, the wordcloud at the topic 40 reflects that the sense is entirely political and revolves around US elections.
Part 3: Sentiment Analysis We have divided three general sentiments in the text that are positive, negative, and neutral. The library used is defined over multi-level classification. Initially, we wanted to do a 16-class classification, but the computation resources and time were minimal for us. To further extend the existing library consumed, an additional column is added that provides insight into the specific emotion.
Part 4: Hate Speech, Geo-locations Finally, to add more context and accurate insight, we have additionally provided information regarding the presence of hate speech and geo-location based on the occurrence frequency of specific cities/countries in the topic text.
Challenges we ran into
- The three people in the team entirely belong to three different time zones, which was the initial most challenging task as communicating effectively and efficiently was needed to complete the work.
- The biggest challenge was with limited GPU capacities of our systems.
- Notebooks were clashing n number of times, and executions were taking hours to process
- Combining everything and delivering just before the deadline was another challenge.
Accomplishments that we're proud of
- We developed the final model after almost no sleep for two days.
- Collaboratively worked to complete the task and deliver on time.
What we learned
- Learned the implementation of various libraries for text processing.
- Learned de-bugging skills on top of model evaluation.
- Improved effective collaboration.
What's next for Factnetic
Well, we actually have far high hopes to further extend our work by using the BERT model for the processing and training; we haven't done it now as the time was very limited and the BERT is highly resource intensive. We also aim to further compare multiple implementation and possibly combine our findings to form meaningful research.
Built With
- information-retrival
- machine-learning
- python
- topic-modeling
- visualisation



Log in or sign up for Devpost to join the conversation.