-
-
1
-
2
Inspiration
In this era of technology, the intake of information through digital media has grown exponentially and it has provided people with personal motives to spread falsified information among the masses to create biased opinions and a sense of unrest. The falsified information is provided to the people especially during elections to create political unrest among the masses or simply to spread a rumour. Since most of the information consumed by people is in the form of text, through newsletters, it has become a great target spot for people with malicious intent.
FactFindr focuses on detecting falsehoods and provides analytic insights based on the organization, country, events or person in a visually compelling manner.
What it does and How we build it
FactFindr includes:
- Data Preprocessing - Assigns the label to true and fake news. Cleaning, and formatting the data. Concatenating both datasets together.
- NLP - To extract relevant information, this uses the techniques like stopwords, tokenization, converting to lowercase, and stemming.
- Extracting Information - For better understanding with respect to organization, person, and country that appears more frequently in the news.
- Sentiment Analysis - This lies between -1 to +1 and helps users gauge the emotional tone of the news.
- Visualization - To visualise the relationships among news with sentiments and analytic insights based on the organization, country, events or person.
- Modelling - To identify the long-term dependency, the dataset is trained on LSTM (long short-term memory networks).
Outcomes
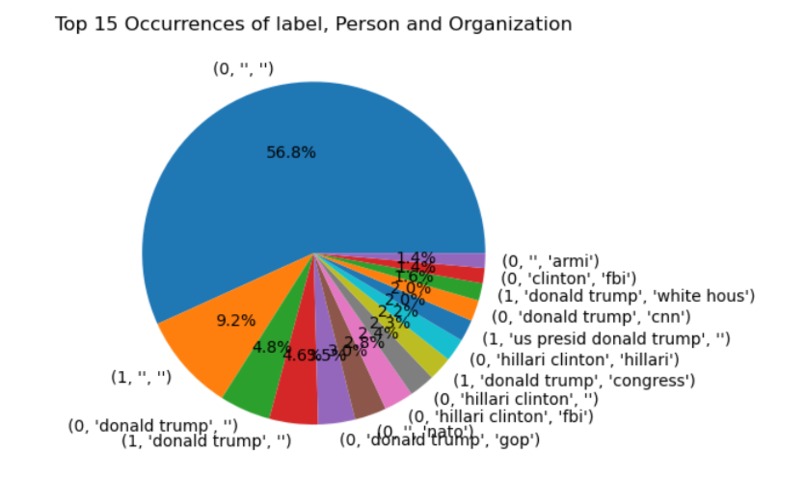
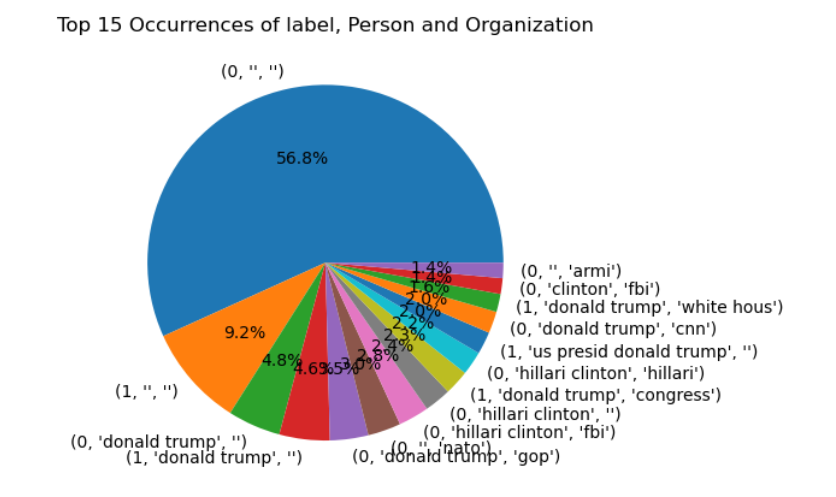
- From extracting the information we could able to see the correlation between the label, organization and Person. For example: After calculating the correlation between different features in the dataset, it appears that the combination with the highest count is (0, "Clinton", "FBI"). This suggests that news articles related to Clinton and the FBI may be more likely to be fake news.
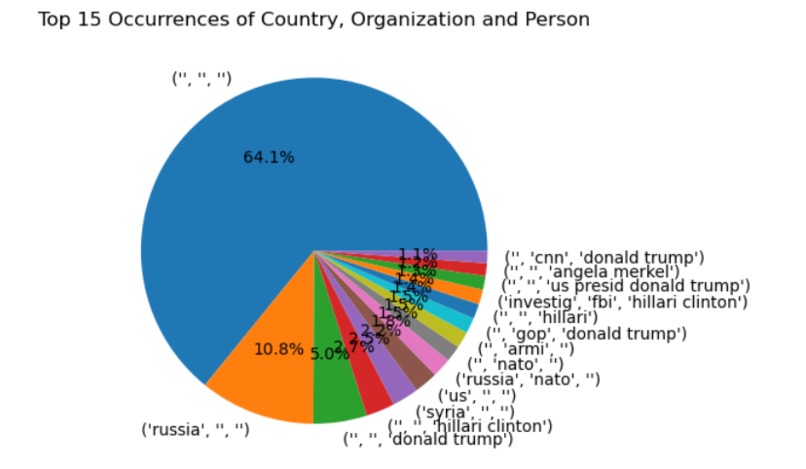
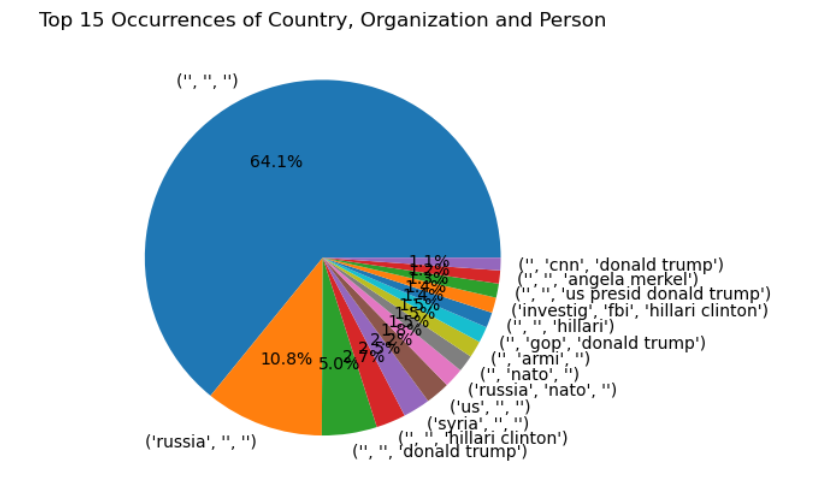
- From extracting the information we could able to see the correlation between the organization, country and Person. For example: ("russia", "nato") are showing one of the top 15 correlations, similarly ("nvestig","fbi","hillari clinton") as per the dataset.
Challenges we ran into
- Analyzing data which is mostly related to the US.
- Got to know recently about this hackathon so less time.
Accomplishments that we're proud of
- Able to complete within the time frame.
- Great experience and got in touch back to machine learning and deep learning after so long.
- Resulting model leads to 91.47% accuracy.
What we learned
- Analyzing the information and performing EDA.
- Extraction of the relevant information.
What's next for FactFindr
- Short term: To make a webapp open to the user to detect information.
- Long term: Expanding the webapp, connecting it with a database or directly getting real-time information from the official relevant websites. Exploring more advanced visualization tools.
Built With
- lstm
- machine-learning
- matplotlib
- natural-language-processing
- tensorflow
Log in or sign up for Devpost to join the conversation.