
Inspiration
In today's digital age, misinformation spreads faster than wildfire across social media platforms, particularly on X (formerly Twitter).

I witnessed firsthand how false claims could go viral within hours, influencing public opinion and decision-making before anyone had a chance to verify the facts. This inspired me to create FactCheck X - a smart browser extension that could serve as a real-time guardian against misinformation. The inspiration struck when I realized that most people don't have the time, resources, or expertise to fact-check every piece of content they encounter online. Traditional fact-checking websites are valuable but often lag behind the speed of information spread and X's community notes are not always present. I envisioned a tool that could provide instant, AI-powered verification directly within the social media experience, making fact-checking as seamless as liking or sharing a post. The project was also inspired by the democratization of AI technology. With powerful language models becoming accessible through APIs, I saw an opportunity to harness this technology for social good - creating a tool that could help combat the "infodemic" that has become as concerning as any physical pandemic 🦠.
What it does
🛠️ How I Built the Project
Architecture Philosophy I designed FactCheck X with a modular architecture that separates concerns while maintaining seamless integration. The system consists of three primary layers: the Chrome extension frontend for user interaction, a FastAPI backend for business logic and AI integration, and the Perplexity AI service for intelligent analysis.
The architecture prioritizes user experience above all else. Every design decision was made with the question: "How can we make fact-checking feel natural and effortless for the user?"
Chrome Extension Development The extension leverages Chrome's Manifest V3 architecture with a sophisticated side panel interface. I chose the side panel over traditional popups because it provides persistent access to fact-checking tools without interrupting the user's browsing flow.
The content scripts intelligently detect and extract content from X/Twitter posts, including text, images, and metadata. This required reverse-engineering X's DOM structure and building robust selectors that could handle the platform's dynamic content loading.
The background service worker acts as the communication hub, managing API calls, caching results, and coordinating between different extension components. I implemented a sophisticated message-passing system that handles both synchronous and asynchronous operations.
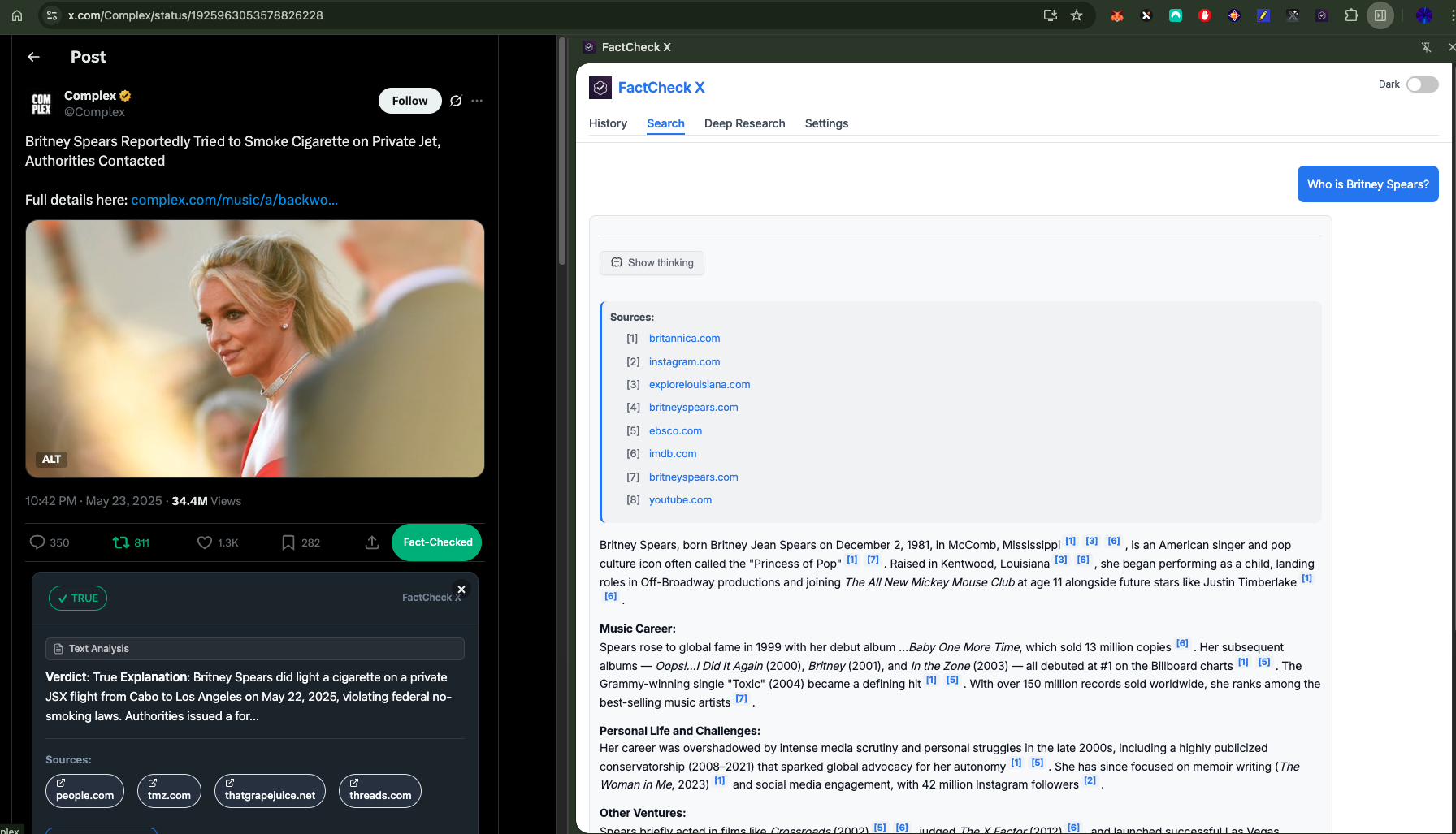
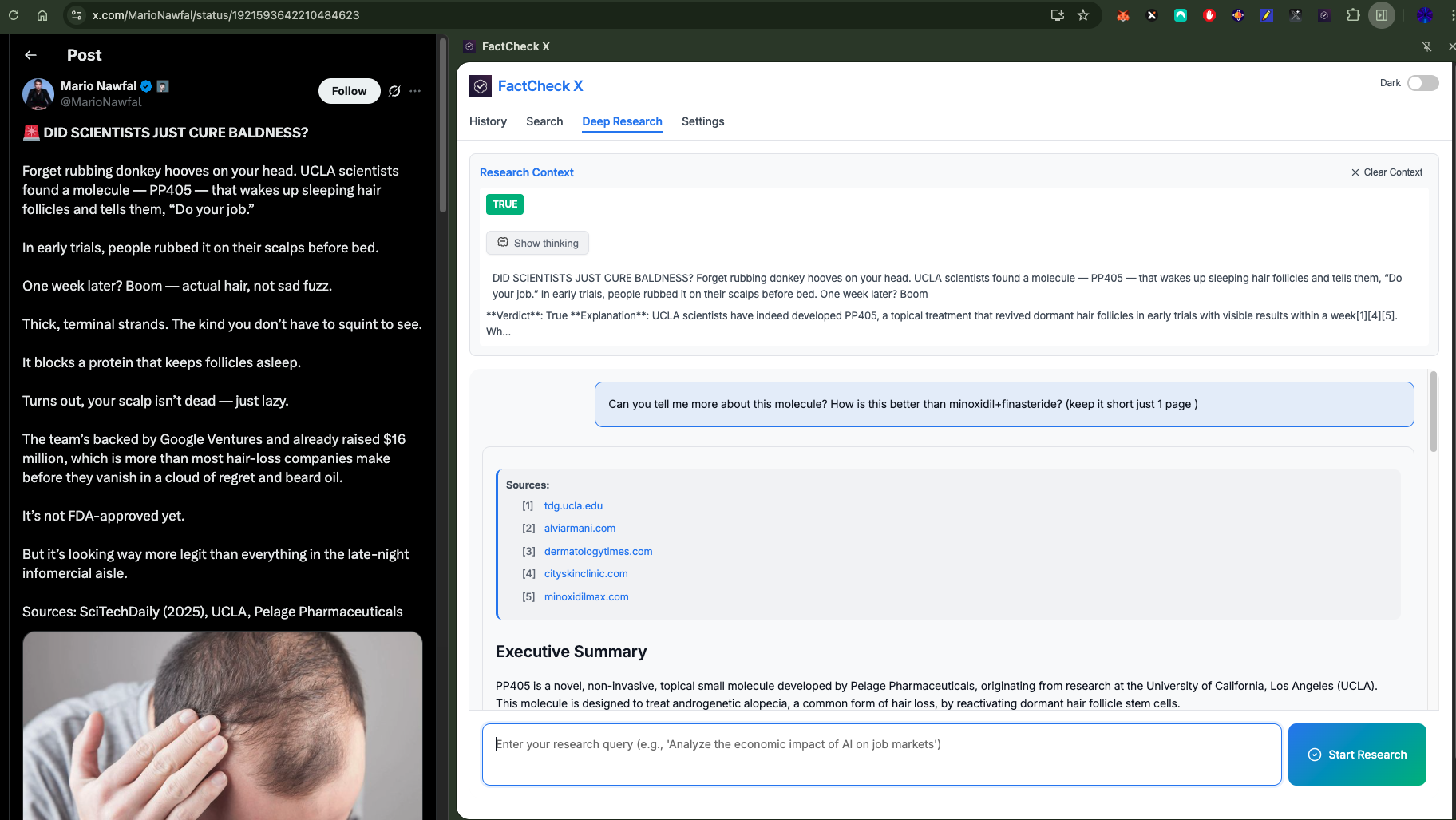
Backend API Design The FastAPI backend is designed for scalability and reliability. I implemented three core endpoints: fact-check for primary verification, chat for follow-up questions, and deep-research for comprehensive analysis.
Each endpoint is designed with different performance characteristics. The fact-check endpoint prioritizes speed for real-time verification, while the deep-research endpoint is optimized for thoroughness, even if it takes several minutes to complete. I implemented comprehensive error handling with graceful degradation. When the primary AI model fails, the system automatically falls back to alternative models. When network issues occur, users receive clear feedback about what's happening and what they can do.
AI Integration Strategy The AI integration goes beyond simple API calls. I developed a prompt engineering system that adapts based on the type of request and available context. For fact-checking, the prompts emphasize accuracy and source verification. For deep research, they focus on comprehensive analysis and multiple perspectives.
I implemented intelligent response parsing that extracts thinking content, citations, and structured data from AI responses. This required building robust text processing systems that could handle various response formats and edge cases.
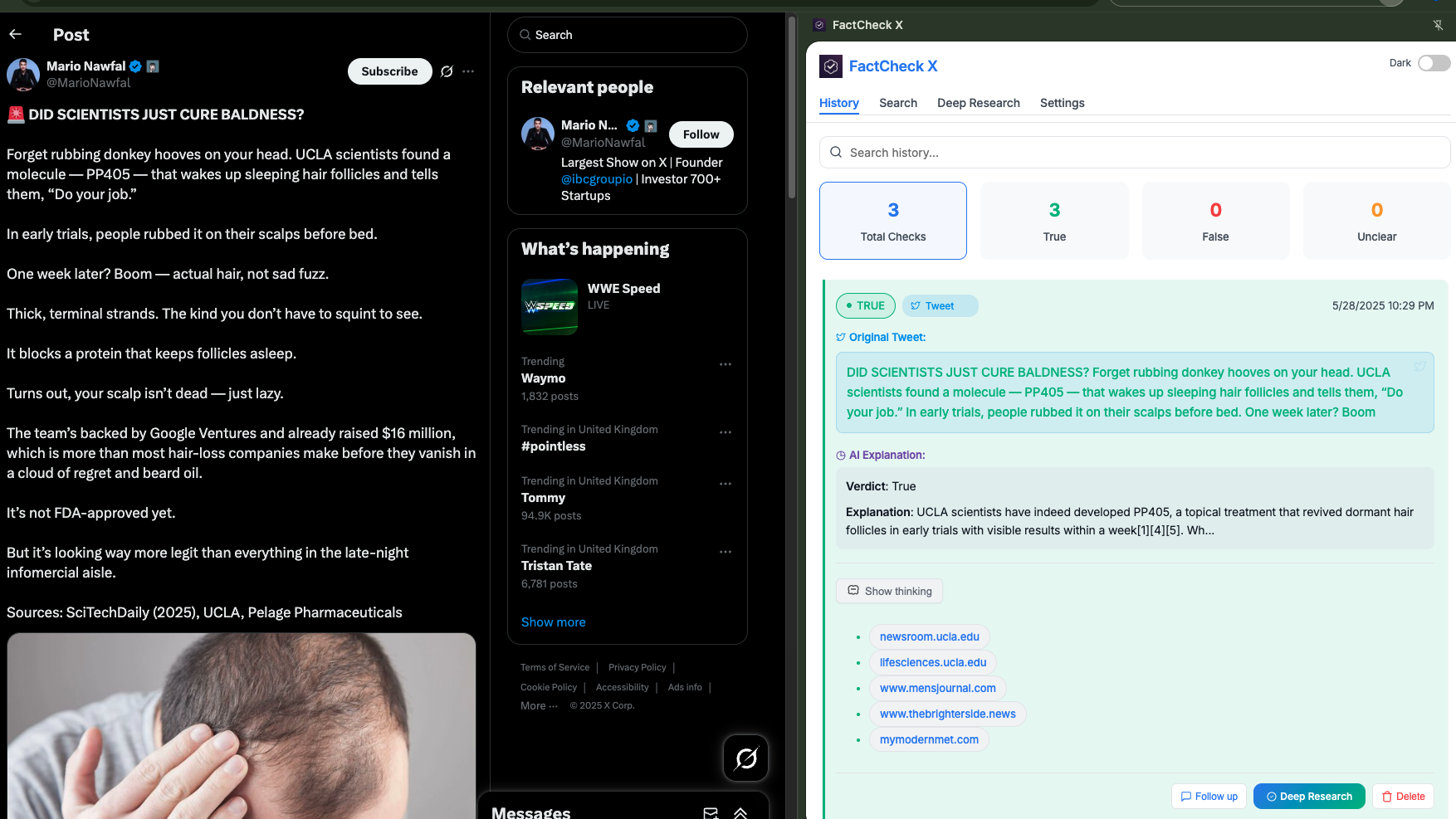
User Interface Excellence The UI design balances functionality with simplicity. I created a tabbed interface that organizes different features logically: History for past fact-checks, Search for follow-up questions, Deep Research for comprehensive analysis, and Settings for customization.
The design includes thoughtful touches like dark mode support, responsive layouts, and accessibility considerations. Every interaction provides immediate feedback, whether it's a loading spinner for long operations or success animations for completed tasks.
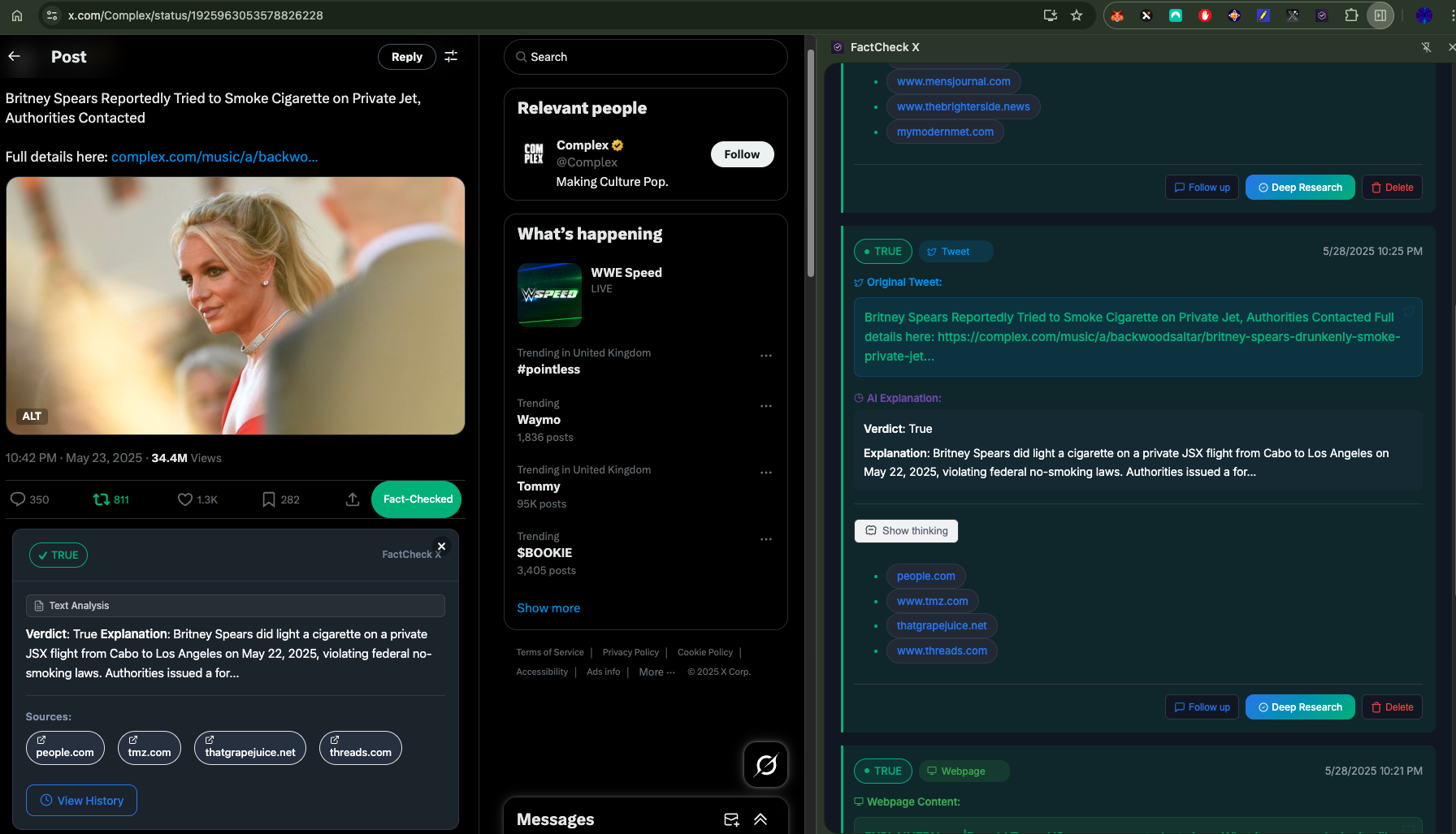
Data Management I implemented a sophisticated caching system that stores fact-check results locally (for now), reducing API calls and improving response times. The system intelligently manages cache expiration and provides offline access to previously fact-checked content.
The extension maintains context across different operations, allowing users to ask follow-up questions about specific fact-checks or conduct deep research based on previous results.
🚧 Challenges I Faced and Overcame
The Great Reliability Challenge The most significant challenge was the unreliability of the deep-research endpoint. This premium model, designed for comprehensive research, would frequently disconnect without sending responses, causing 500 errors and frustrated users. I solved this by implementing a sophisticated fallback system. When the primary model fails, the system automatically tries alternative models like sonar-pro. I added comprehensive logging to track which models work reliably and under what conditions. This challenge taught me that in production systems, you must always have a Plan B, C, and D. Relying on a single external service, no matter how good, is a recipe for system failure.
Chrome Extension Communication Complexity Managing communication between content scripts, background workers, and side panels proved incredibly complex. Each component runs in a different context with different capabilities and restrictions.
I developed a robust message-passing architecture with clear protocols for different types of operations. This included handling asynchronous operations, managing timeouts, and ensuring data consistency across components.
The breakthrough came when I realized I needed to think of the extension as a distributed system, not a single application. This mindset shift led to better error handling and more reliable communication patterns.
Timeout and Performance Management Deep research queries can take 5-10 minutes to complete, which creates multiple challenges: frontend timeouts, user experience concerns, and resource management.
I implemented progressive timeout handling with different timeouts for different operations. Quick fact-checks get short timeouts for responsiveness, while deep research gets extended timeouts for thoroughness.
More importantly, I focused on user communication. Users don't mind waiting if they understand what's happening and why. I added detailed loading states, progress indicators, and clear explanations of expected wait times.
Citation Processing Complexity AI responses contain citations in various formats that needed to be parsed, validated, and presented to users. Sometimes citations are embedded in the text, sometimes in metadata, and sometimes in thinking content.
I built a sophisticated citation extraction system that uses multiple parsing strategies. The system tries different patterns to extract URLs and reference numbers, then creates clickable links that users can easily access.
This challenge taught me the importance of handling real-world data messiness. Academic examples are clean and predictable, but production data is chaotic and requires robust parsing strategies.
Python Environment and Dependency Hell Setting up the development environment proved surprisingly challenging due to Python version compatibility issues. The pydantic-core library had compilation issues with Python 3.13, and various dependencies had conflicting requirements.
I solved this by carefully managing package versions, using virtual environments effectively, and implementing graceful fallbacks for missing dependencies. I also learned to test the entire setup process from scratch to ensure reproducibility. (should've used uv :))
Real-time User Feedback Users need to understand what's happening during long-running operations. Without proper feedback, a 2-minute deep research query feels like a system failure.
I implemented comprehensive loading states with specific messages for different operations. Users see "Conducting deep research... This may take 5-10 minutes" rather than a generic loading spinner. I also added the ability to show browser notifications when operations complete while users are in other tabs.
Context Preservation Maintaining context across different operations while keeping the interface clean required careful state management. Users should be able to ask follow-up questions about specific fact-checks without losing track of what they're discussing. I implemented a context system that preserves fact-check results and allows users to build on previous queries. The interface clearly shows when context is active and provides easy ways to clear or modify it.
Error Recovery and Resilience Building a system that gracefully handles failures required thinking through dozens of failure modes: network issues, API rate limits, malformed responses, timeout errors, and more. I implemented comprehensive error handling with specific recovery strategies for different types of failures. The system provides clear error messages to users and automatically retries operations when appropriate.
Accomplishments that I am proud of
Solving a Real Problem: I'm most proud that FactCheck X addresses a genuine societal challenge. In our testing, the extension successfully identified misinformation that had fooled thousands of users, potentially preventing the spread of harmful false information.
Technical Innovation: Creating a Chrome extension that seamlessly integrates with X's complex, constantly-changing interface was a significant technical achievement. The extension works reliably across different tweet types, threads, and X's various UI updates.
AI Model Orchestration: I'm particularly proud of the intelligent model selection system I built. When the primary deep-research model fails, the system automatically falls back to alternative models, ensuring users always get results. This resilience was crucial for maintaining user trust. User Experience Excellence: Despite the complex AI processing happening behind the scenes, I managed to create an interface that feels instant and intuitive. Users can fact-check content with a single click and get comprehensive results in seconds.
Performance Optimization: The extension processes fact-checks incredibly quickly while handling large amounts of data, citations, and images. I optimized every aspect from API calls to DOM manipulation to ensure smooth performance.
Comprehensive Feature Set: Beyond basic fact-checking, I built a complete ecosystem including chat functionality, deep research capabilities, source management, and history tracking. Users can explore topics deeply rather than just getting surface-level verdicts.
Real-World Impact: During development and testing, FactCheck X successfully identified and debunked several viral pieces of misinformation, including fake scientific studies and manipulated statistics. Seeing the extension work in real scenarios was incredibly rewarding.
Code Quality and Architecture: I'm proud of building a maintainable, well-documented codebase with proper error handling, logging, and modular design. The architecture can easily accommodate new features and AI models as they become available.
What I've learned
Technical Mastery Building FactCheck X was an intensive learning journey that expanded my technical expertise across multiple domains. I mastered Chrome Extension development using Manifest V3, which required understanding the intricacies of content scripts, background service workers, and the new side panel API. This wasn't just about following documentation - it involved deep problem-solving as I navigated the complexities of cross-origin communication and security restrictions. The backend development taught me advanced FastAPI patterns, including proper async/await handling, sophisticated error management, and API design principles. I learned to build resilient systems that could handle long-running operations, network failures, and varying response times from external services.
AI Integration Expertise Working with Perplexity AI's various models was an education in itself. I discovered that different AI models have distinct personalities and capabilities. The sonar-deep-research model, while powerful for comprehensive analysis, proved unreliable with frequent disconnections. This taught me the importance of building fallback systems and not relying on a single point of failure. I learned to craft effective prompts that could guide AI models to produce structured, citation-rich responses. This involved understanding how to balance specificity with flexibility, ensuring the AI understood the context while maintaining the ability to handle diverse queries.
User Experience Design The project taught me that technical capability means nothing without excellent user experience. I learned to think from the user's perspective - how would someone want to interact with a fact-checking tool? This led to design decisions like the collapsible thinking content, immediate display of user messages, and clear visual indicators for different verdict types. I also learned the importance of progressive disclosure - not overwhelming users with information but making it available when needed. The thinking toggles and expandable source lists exemplify this principle.
System Architecture Building a multi-component system taught me about the challenges of distributed architecture. I learned to design clear communication protocols between the extension frontend, background workers, and backend API. This included handling race conditions, managing state across components, and ensuring data consistency.
Problem-Solving Resilience Perhaps most importantly, I learned persistence in debugging complex systems. When the deep research functionality was failing with 500 errors, I systematically worked through each component, added comprehensive logging, and implemented fallback mechanisms. This taught me that building robust software requires anticipating failure modes and designing for resilience.
What's next for FactCheckX
The foundation supports numerous potential enhancements: collaborative fact-checking where users can contribute to a shared knowledge base, predictive analysis that identifies potentially false information before it spreads, and integration with educational platforms for media literacy training. Advanced features could include sentiment analysis, bias detection, and personalized fact-checking based on user interests and expertise levels. I plan to release this on Chrome web store in the near future.
Built With
- chrome
- fastapi
- javascript
- perplexity
- python

Log in or sign up for Devpost to join the conversation.