-
-

Architecture
-

Fact Checking
-

Twitter bad actors
-

Summary
-

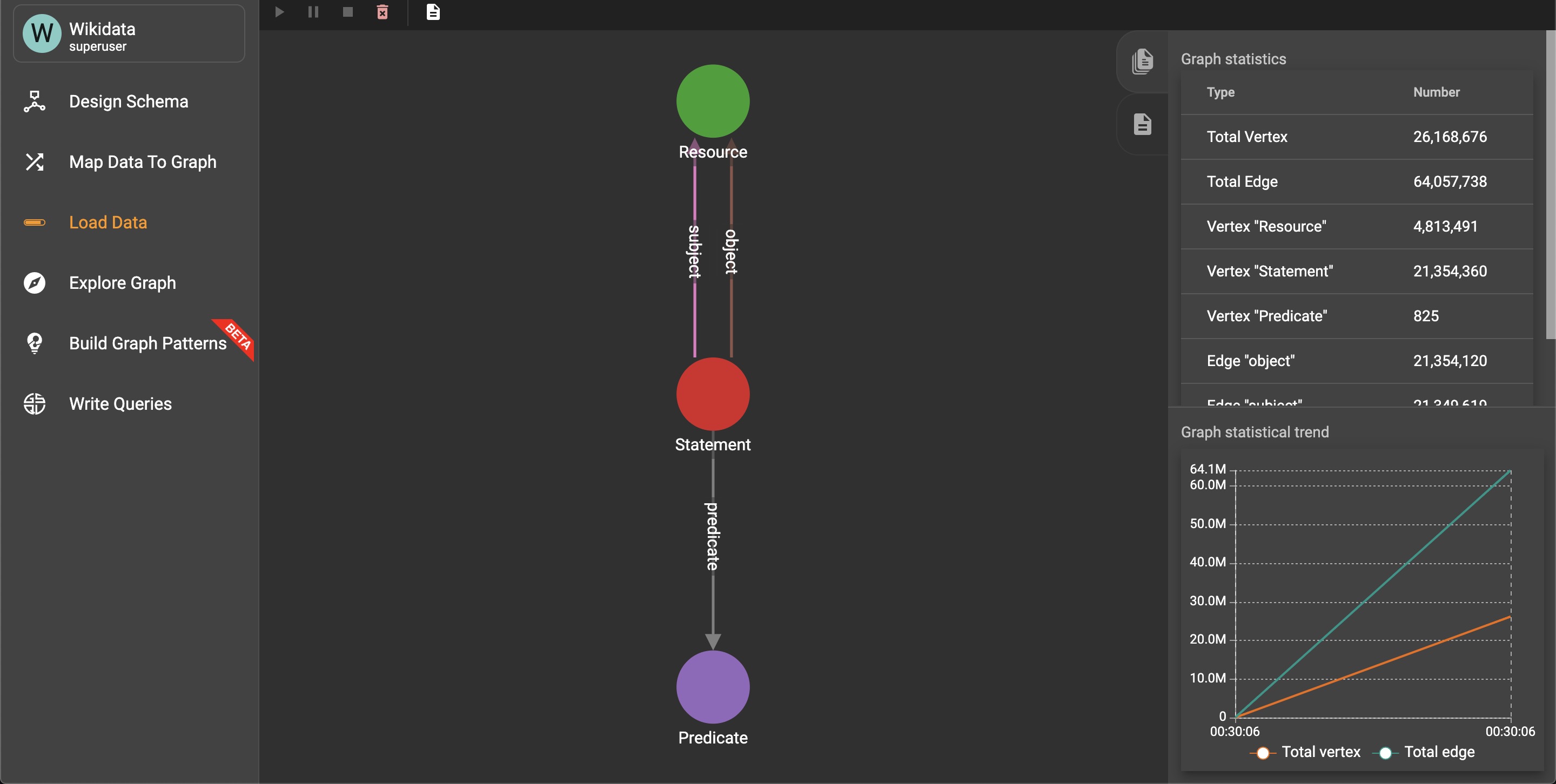
Wikidata Graph - More than 25 million facts
-

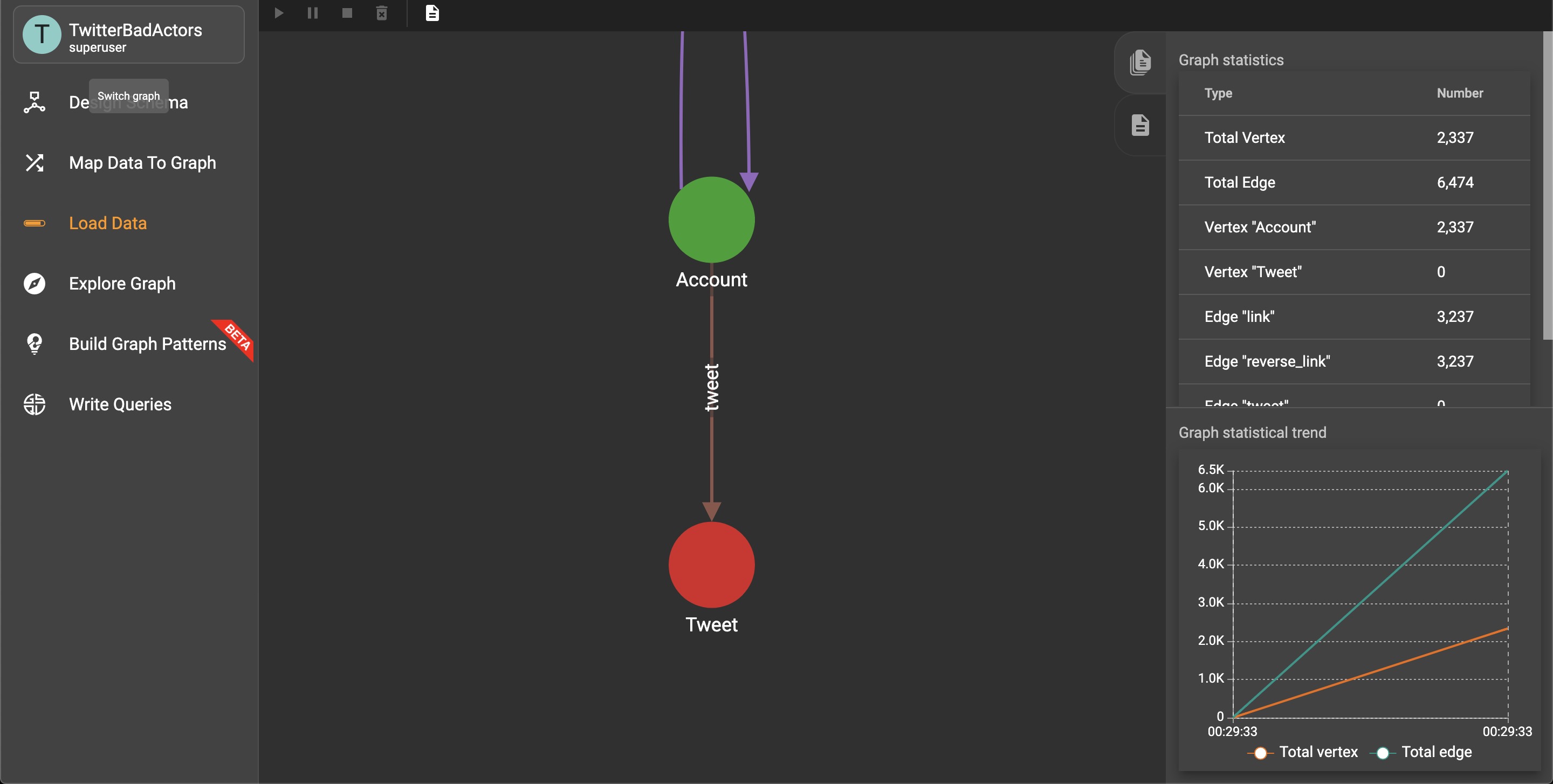
Twitter Bad Actors Graph
-

News Facts graph
-

Fact Checking graph






Problem Statement
Misinformation is everywhere, in social media, websites, and even face-to-face. It’s hard to know what to believe, and even harder to figure out what’s true.
Misinformation has severe consequences. It can lead to health scares, like the anti-vaccination movement. It can cause political instability, like the 2016 U.S. Presidential Election. It can even lead to murder, like the case of the Pizzagate conspiracy theory.
Existing solutions have failed due a number of reasons:
- Lack of accurate, up-to-date data: Most fact-checking organizations rely on manually collected data, which is often out-of-date or incomplete.
- Lack of centralized knowledge base: There is no central repository of fact-checked content, which makes it difficult to track the spread of misinformation and to identify new instances of misinformation.
- Lack of platform coverage: Most fact-checking organizations only operate on one platform (e.g. Facebook), making it difficult to reach users on other platforms (e.g. WhatsApp).
- Lack of scale: Fact-checking organizations are often small, with limited resources. They can only fact-check a limited number of claims.
- Lack of language coverage: Most fact-checking organizations only operate in one language, making it difficult to reach a global audience.
Our solution for all these problems is a multi-platform, multi-lingual, real-time fact-checking system powered by machine learning and graph technology.
What it does?
Fact checker fight misinformation at scale powered by machine learning and graph technology.
- Large knowledge graphs of facts automatically harvested from the web
- Crawlers to automatically extract facts from the web
- iOS App to fact check information from Facebook, Twitter, Websites, and via voice
- Chrome extension to fact check websites
- Twitter bot to automatically monitor bad actors and fake tweets
- Fact spotter to extract relevant facts
- Semantic and reasoning-based fact checking

Architecture



Graph size

Installation
- Setting up keys
- Creating graphs
- Importing data
- Facts crawler
- Facts importer
- Facts spotter
- Twitter Bot Monitor
- Twitter Bot Importer
- Fact checking server
- Chrome Extension
- iOS App
Setting up keys
Put your TigerGraph config (hostname, user, pass) in the following files:
fact-server/tigergraph.jsonfact-twitter-bot/tigergraph.json
Put your Twitter API credentials in fact-twitter-bot/keys.json
You will also need an OpenAI key later when running fact-server.
Creating graphs and importing data
cd fact-server
python -m venv env
source ./env/bin/activate
pip install -r requirements.txt
To create the FactChecking and NewsFacts graphs, run the following command:
python setup.py
To create the TwitterBadActors graph,run the following command:
python setup_bad_actors.py
Finally, use the following Jupyter Notebook to create the WikiData graph and download the dataset and upload the data.
Facts crawler
We need to start the crawler in order to monitor the fact checking websites and media outlets.
Make sure you have MongoDB installed and running. MongoDB is used to store the webpage contents before they are processed and imported into TigerGraph database.
Then run the following:
cd fact-crawler
npm install
Then start the crawler by running
node app.js
The crawler will now fetch from multiple sources (including Snopes, MediaBias, BBC, NewYork Times, among others).
Facts importer
The crawler fetches the facts into a temporary MongoDB database.
Now we need to run the importer to import the claims into the TigerGraph database.
cd fact-server
python -m venv env
source ./env/bin/activate
pip install -r requirements.txt
Then start Facts Importer
python start facts_importer.py
Facts spotter
Fact Spotter is used to automatically extract claims from news articles.
Machine learning model
To train the model use the following Jupyter Notebook.
You can also the pre-trained model I have made available on HuggingFace.
Start spotter
First, install the packages:
cd fact-server
python -m venv env
source ./env/bin/activate
pip install -r requirements.txt
Then start Facts Spotter
python start spotter.py
Twitter Bot Monitor
First, install the twitter bot packages:
cd fact-twitter-bot
npm install
Then start Twitter bot monitoring
node monitor.js
Twitter Bot Importer
Twitter Bot importer imports the fetched accounts into TigerGraph.
First, install the twitter importer packages:
cd fact-twitter-bot
python -m venv env
source ./env/bin/activate
pip install -r requirements.txt
Then start Twitter Accounts importer
python importer.py
Fact checking server
Fact server is responsible for doing fact checking using semantinc and reasoning-based approaches.
cd fact-server
python -m venv env
source ./env/bin/activate
pip install -r requirements.txt
Then start Facts Server
OPENAI_KEY=<YOUR_KEY> TWITTER_TOKEN=<TOKEN> python start app.py
Chrome Extension
Install the live version from here
If you want to develop locally:
- Goto Chrome Settings using three dots on the top right corner.
- Now, Enable developer mode.
- Click on Load Unpacked and select your Unzip folder. Note: You need to select the folder in which the manifest file exists.
- The extension will be installed now.
iOS App
Install the live version from here
To edit locally, open the project using XCode.
What's next for FactChecker - Fighting misinformation at scale
- Add more sources
- Add support for more languages








Log in or sign up for Devpost to join the conversation.