-
-
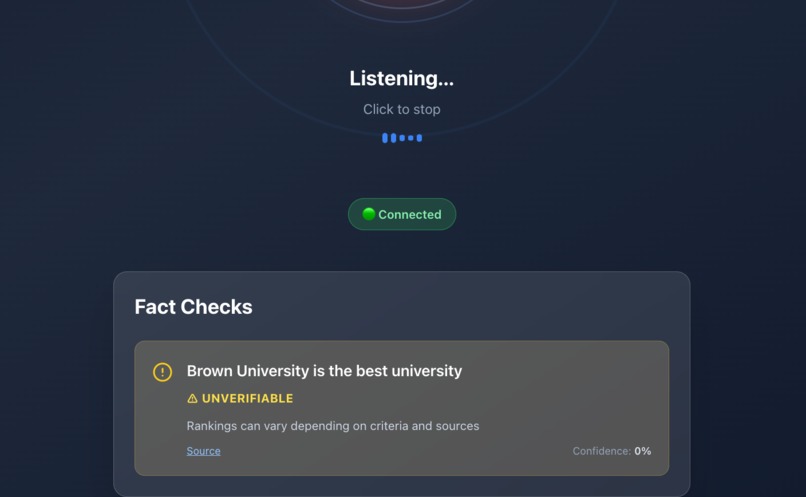
subjective (should be true)
-
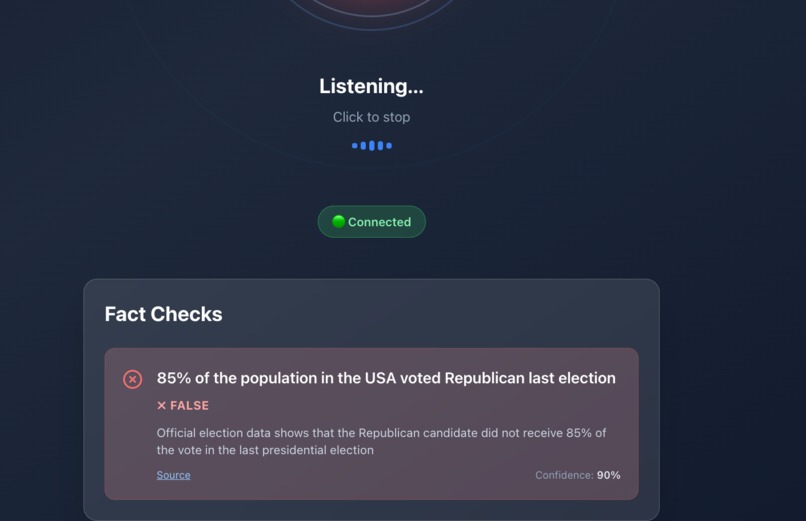
false
-
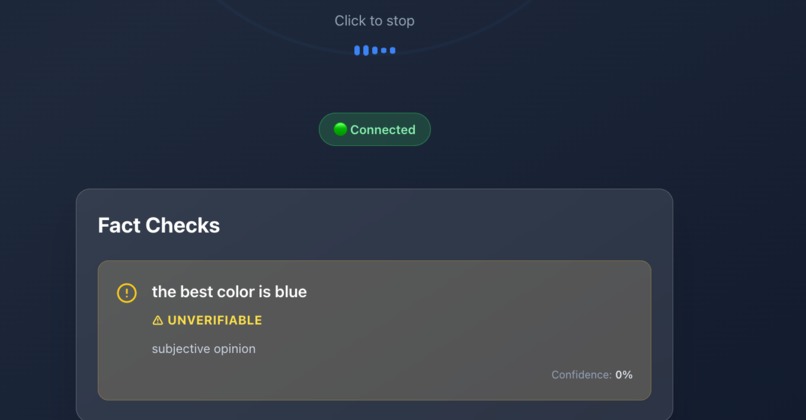
subjective
-
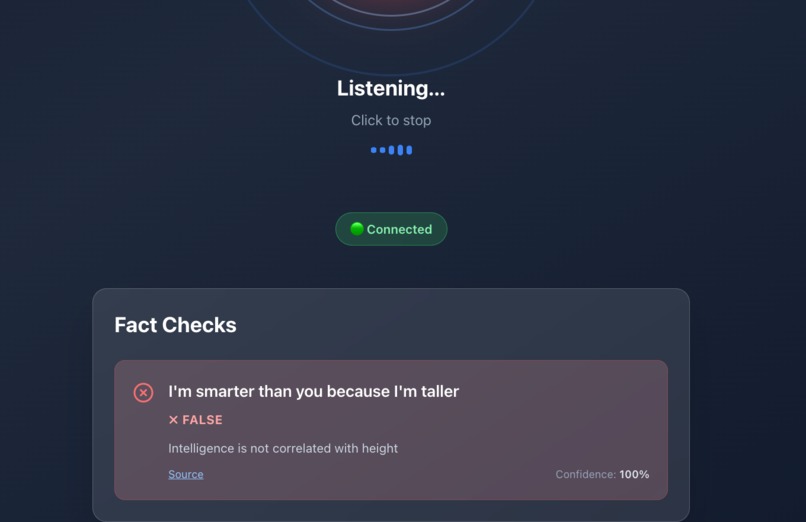
false
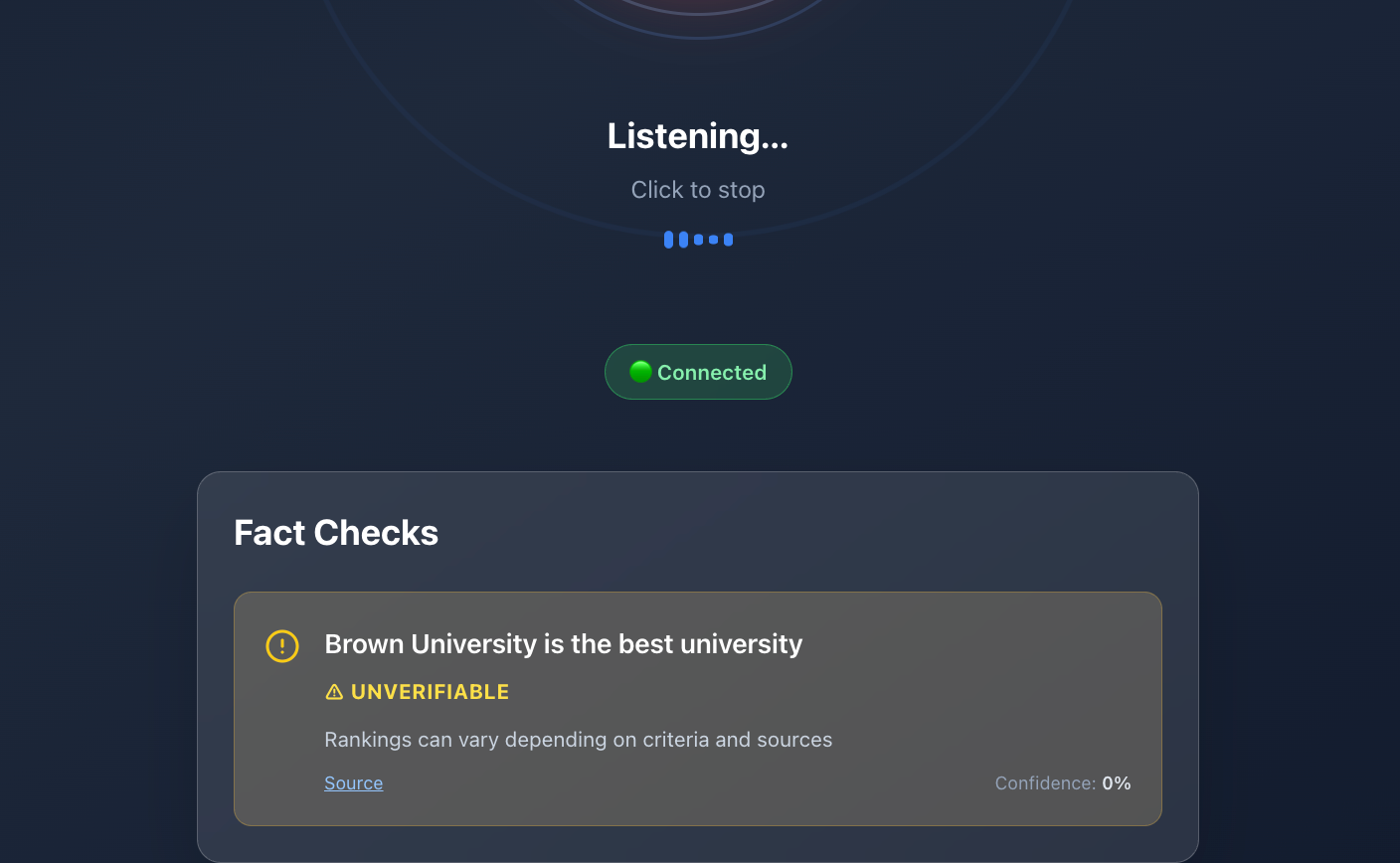
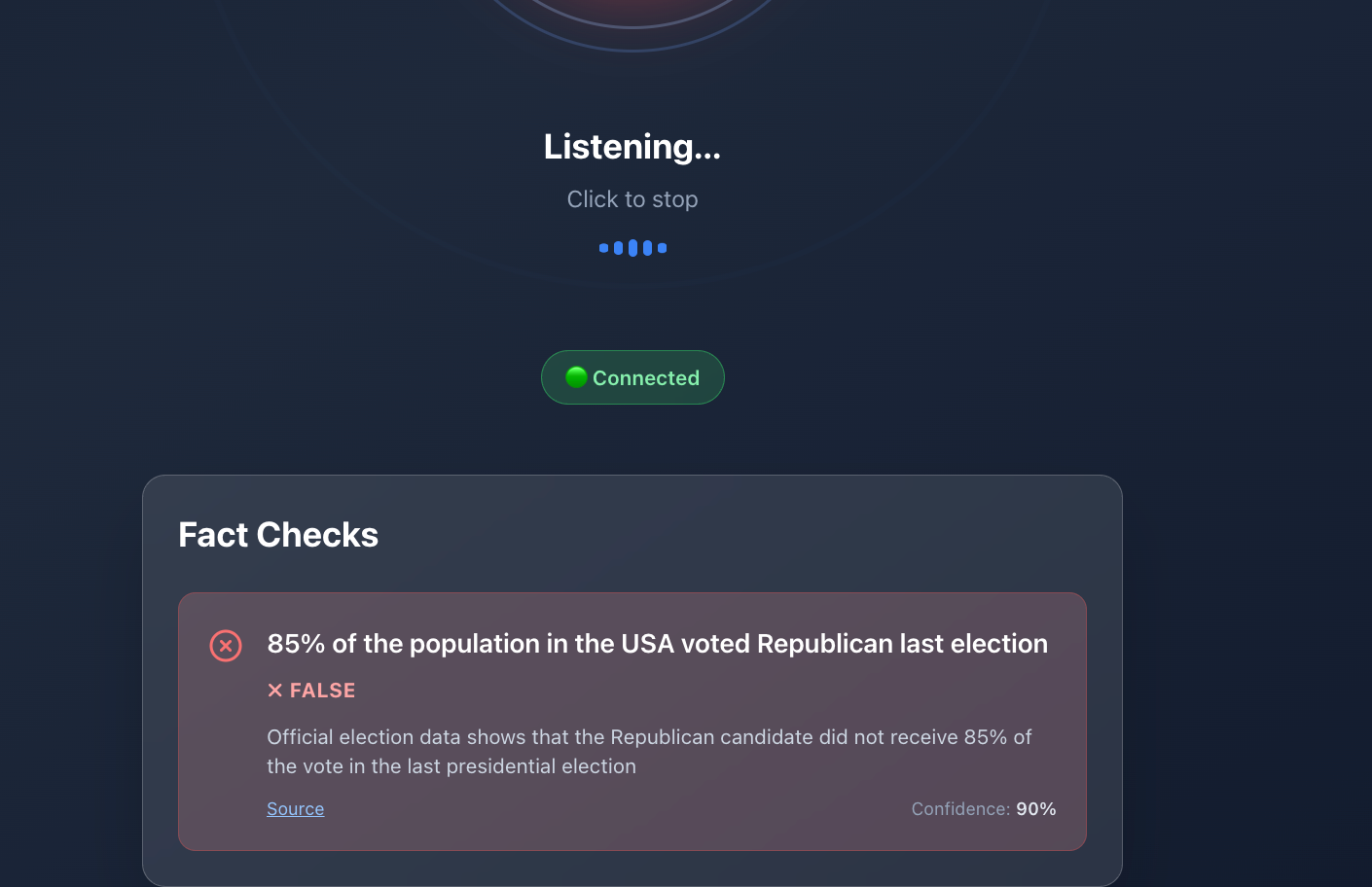
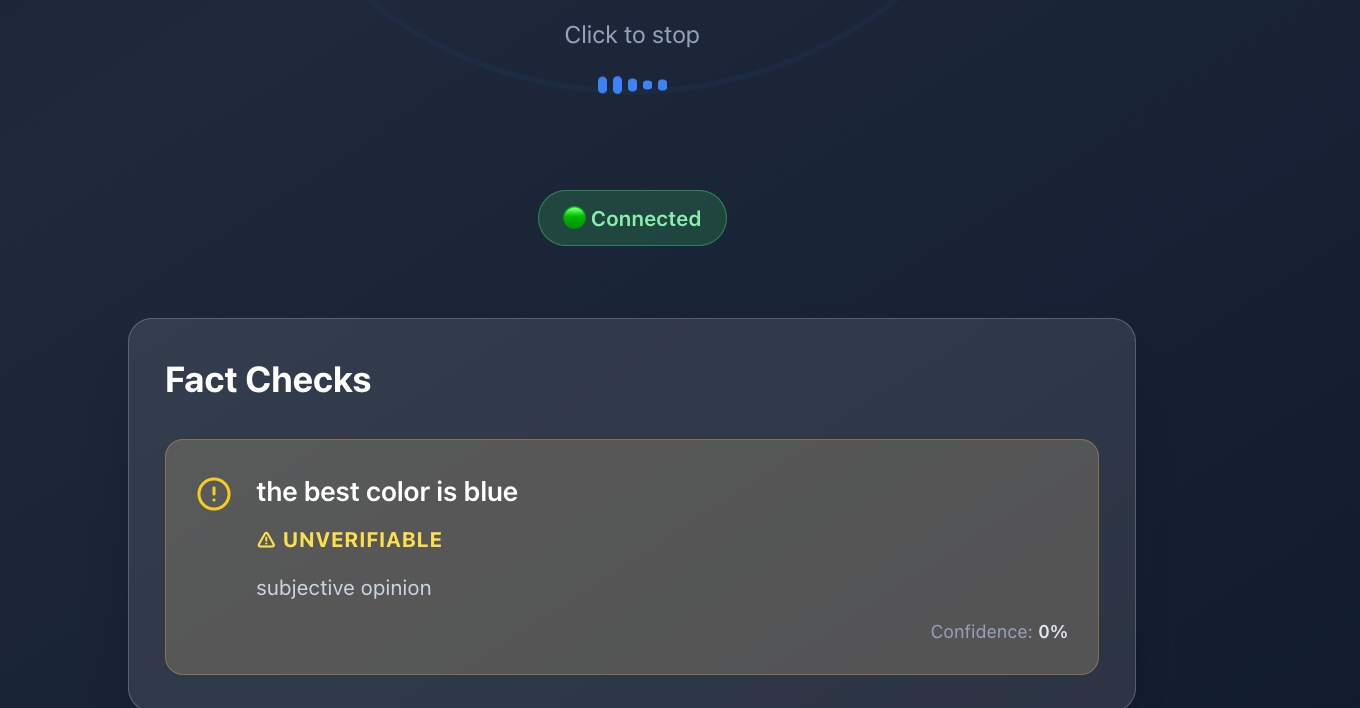
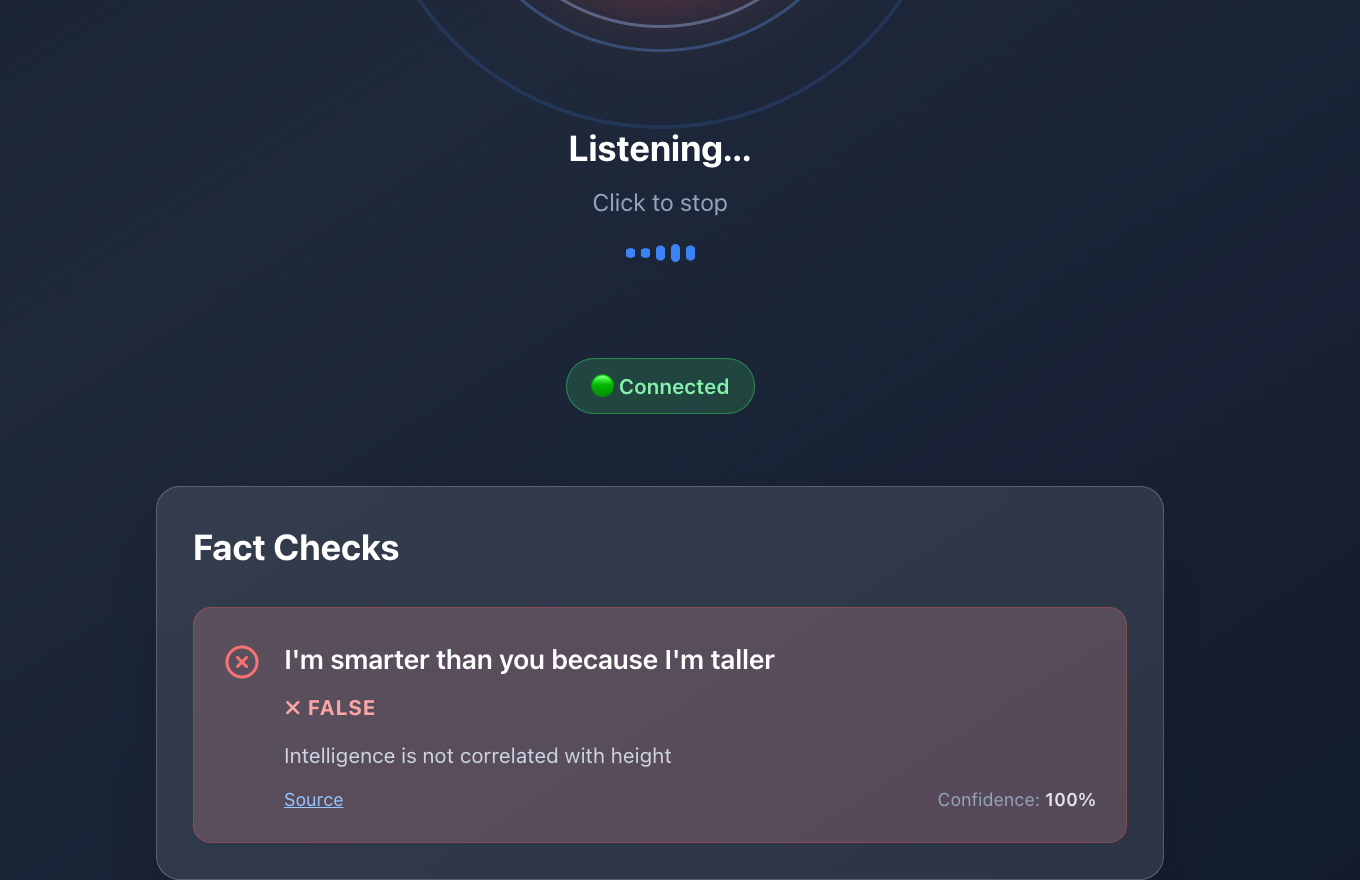
Real-Time Audio Fact Checking with AI
Inspiration
This project was born out of a sense of urgency. Recent political events made it painfully clear how fast misinformation can spread, especially through audio-first mediums like speeches, livestreams, podcasts, and social media clips. Unlike written claims, spoken statements often go unchecked in the moment, gaining credibility simply because they are heard live.
We wanted to explore a simple but ambitious question: what if claims could be fact-checked as they are spoken?
That idea pushed us to build an app that listens to live audio, extracts claims, and verifies them in real time using AI.
What We Learned
This hackathon was a crash course in many dimensions of engineering.
First, two of us were first-time hackers, so we learned the fundamentals of how hackathons actually work: rapid ideation, dividing responsibilities, shipping imperfect but functional systems, and making tradeoffs under extreme time pressure. We learned that velocity often matters more than perfection.
Second, we gained hands-on experience with AI-driven audio processing. We learned how raw audio must be transformed into structured representations before AI models can reason over it, and how fragile that pipeline can be. We also learned how to design prompts and agent workflows that balance speed, accuracy, and interpretability.
Finally, we learned how to effectively use AI as a development accelerator, not a replacement. AI helped us debug, scaffold components, and reason about unfamiliar APIs, but our own coding experience was essential for system design, integration, and knowing when generated solutions were wrong.
How We Built It
Our architecture centered around a lightweight but flexible web stack:
- Node.js + Express for the backend API and real-time request handling
- Vite for fast local development and build tooling
- Tailwind CSS for rapid, responsive UI styling
- Additional AI services for transcription, claim extraction, and fact verification
At a high level, the system works as follows:
- Live audio is captured and streamed from the client.
- The audio is converted into a format suitable for transcription.
- Transcribed text is parsed to identify factual claims.
- Claims are sent to AI agents that verify them against known sources.
- Results are returned to the UI with confidence indicators and explanations.
We treated the AI components as modular agents rather than a single monolithic model, which made it easier to iterate and debug under time constraints.
Challenges We Faced
The hardest problem by far was audio formatting and processing.
AI models are extremely sensitive to how audio is encoded, chunked, and streamed. Small mismatches in sample rate, encoding format, or buffering strategy caused failures ranging from silent errors to completely unusable transcriptions. Ensuring that audio was consistently processed in the exact format expected by downstream AI agents took a surprising amount of time.
We also had to balance latency and accuracy. Smaller audio chunks reduced delay but increased the likelihood of incomplete or ambiguous claims, while larger chunks improved context at the cost of responsiveness. Finding a workable middle ground required constant iteration.
Despite these challenges, the moment we saw the system successfully transcribe and fact-check live speech in real time made every debugging session worth it.
Reflection
This project pushed us technically and mentally. We walked away with a deeper understanding of real-time systems, AI-assisted development, and collaborative problem-solving under pressure. Most importantly, we proved to ourselves that even with limited time and first-time hackers on the team, it is possible to build something meaningful, ambitious, and relevant.
If misinformation moves at the speed of sound, fact-checking should too.
Built With
- deepgram
- express.js
- gemini
- google-web-speech-api
- grok-api
- groq
- node.js
- react.js
- socket.io
- tailwind

Log in or sign up for Devpost to join the conversation.