-

FacilityIQ Logo
-
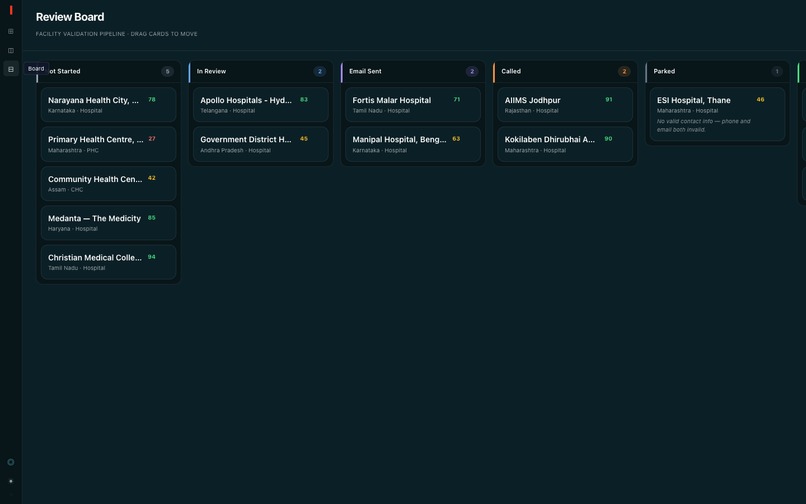
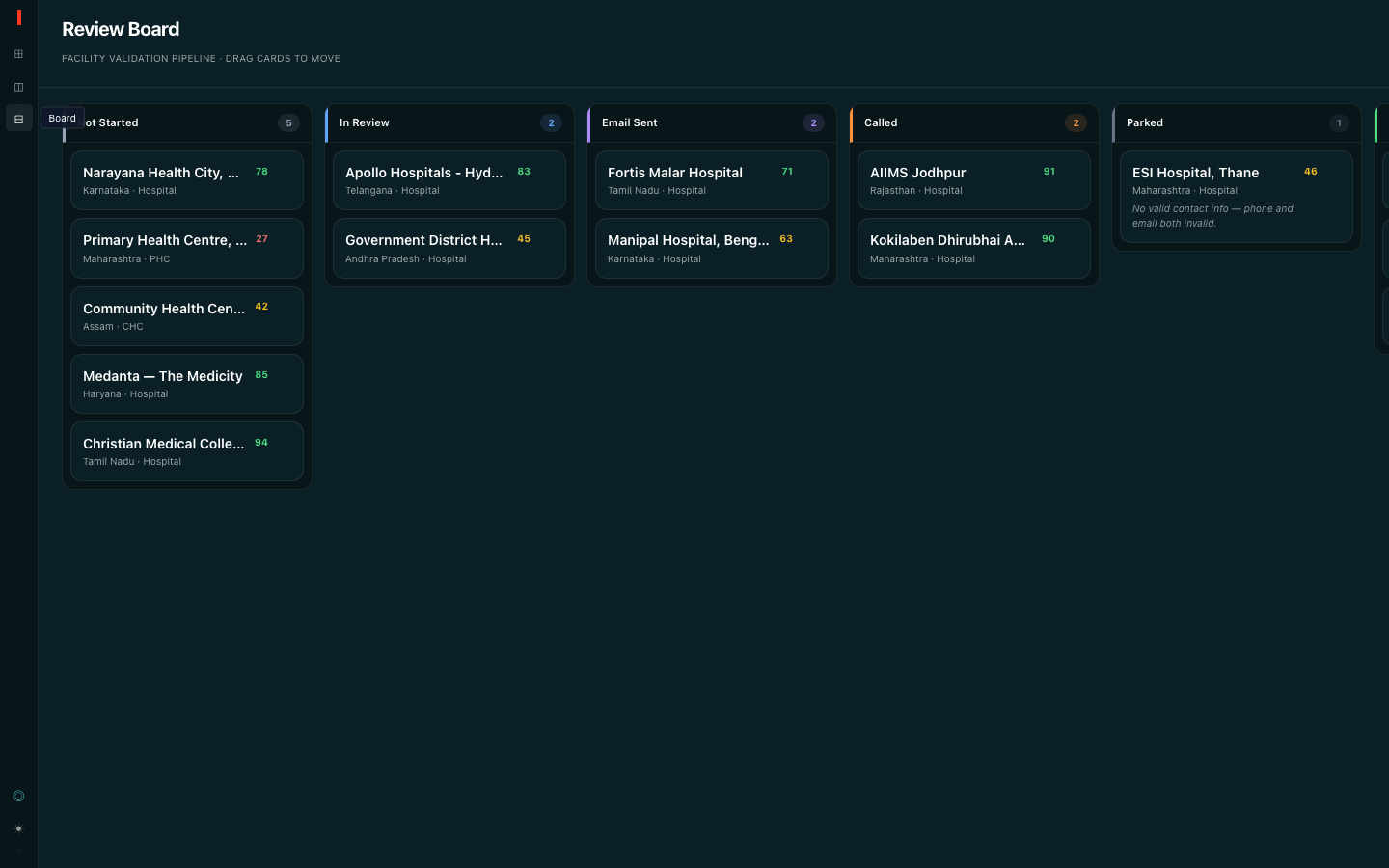
Kanban Board
-
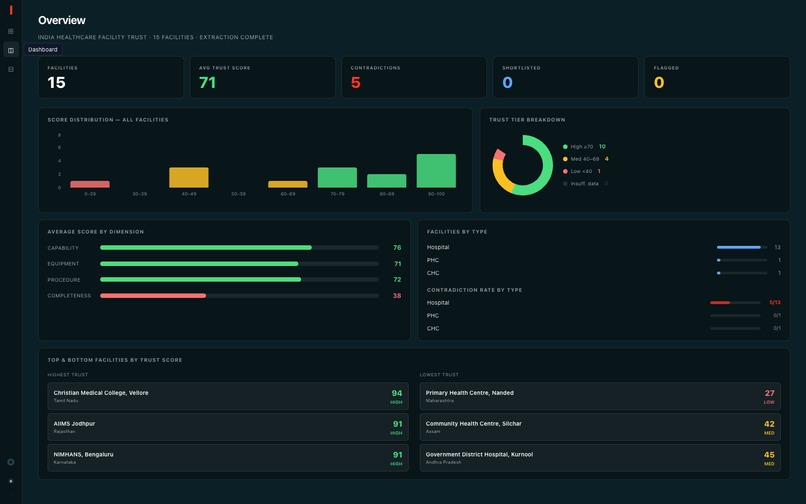
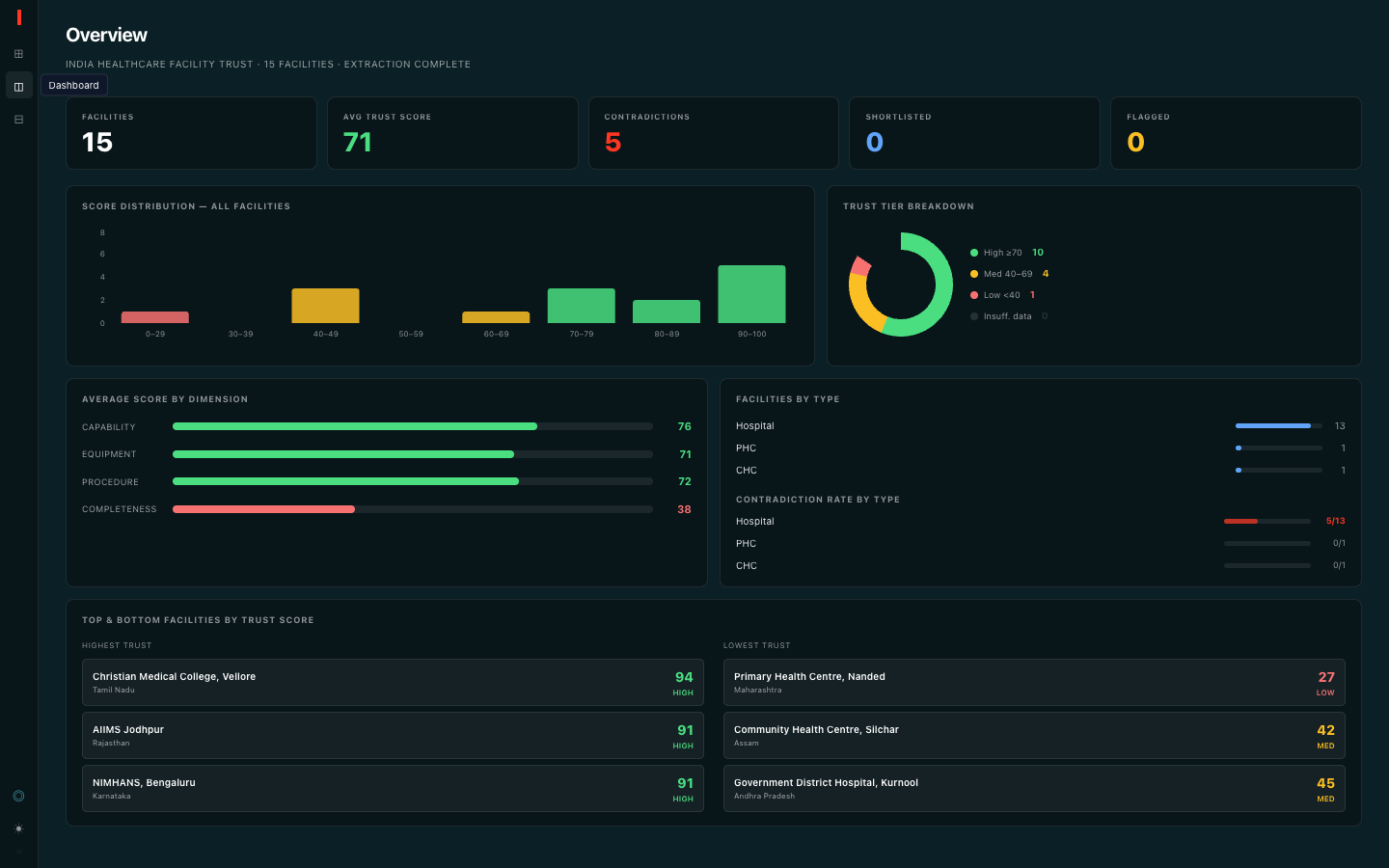
Dashboard
-
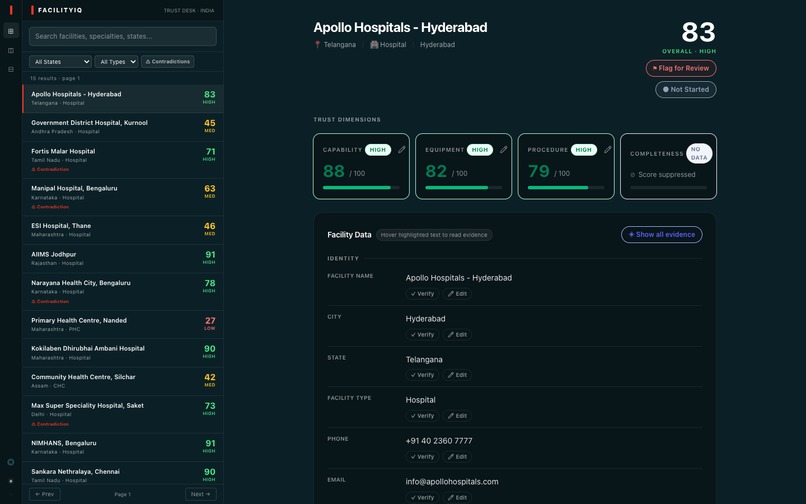
Scorecard
-
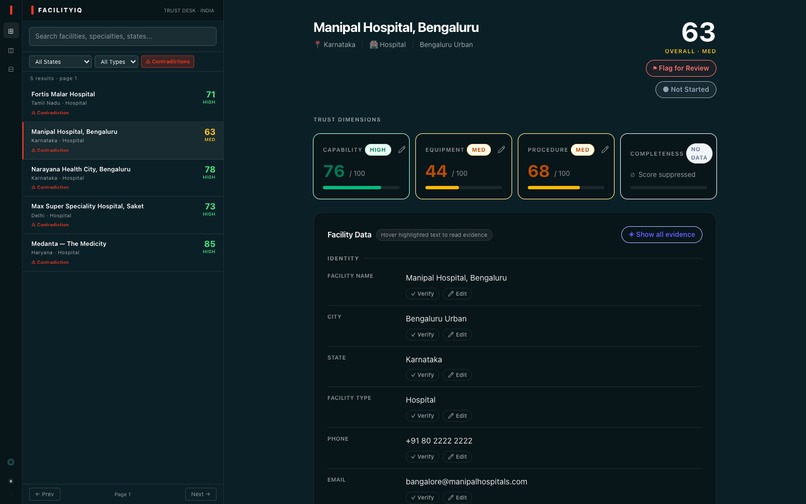
Contradiction Filter
-
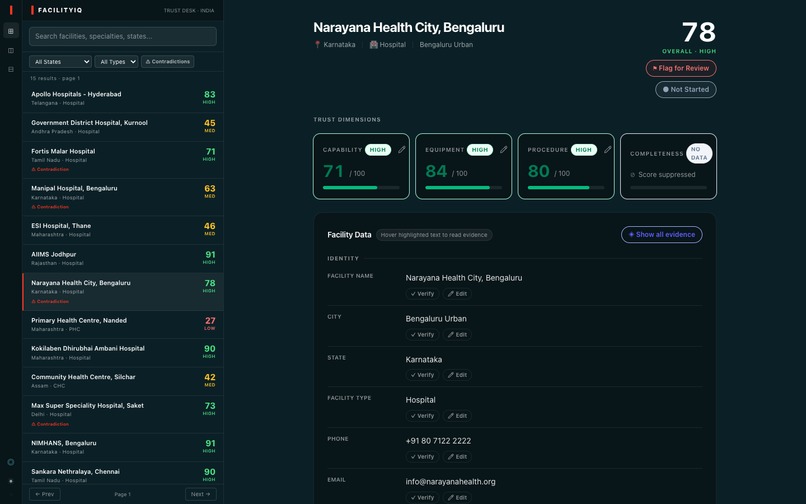
Scorecard
-
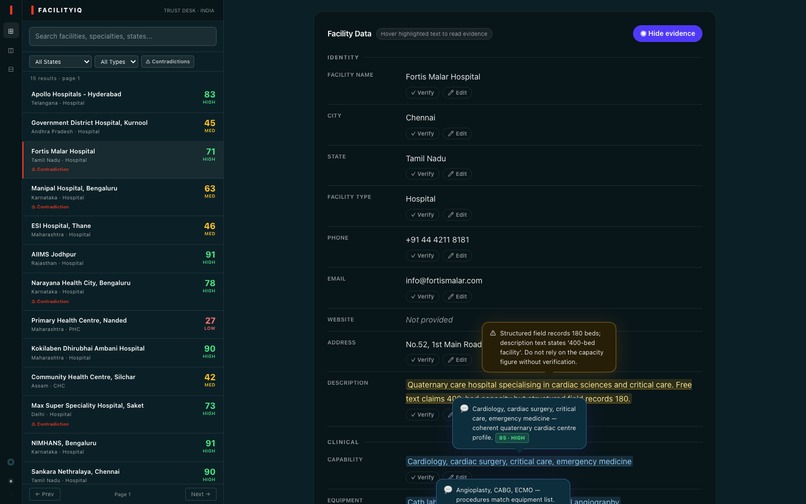
Contradiction
-

Splash Screen


FacilityIQ - Our Story
Inspiration
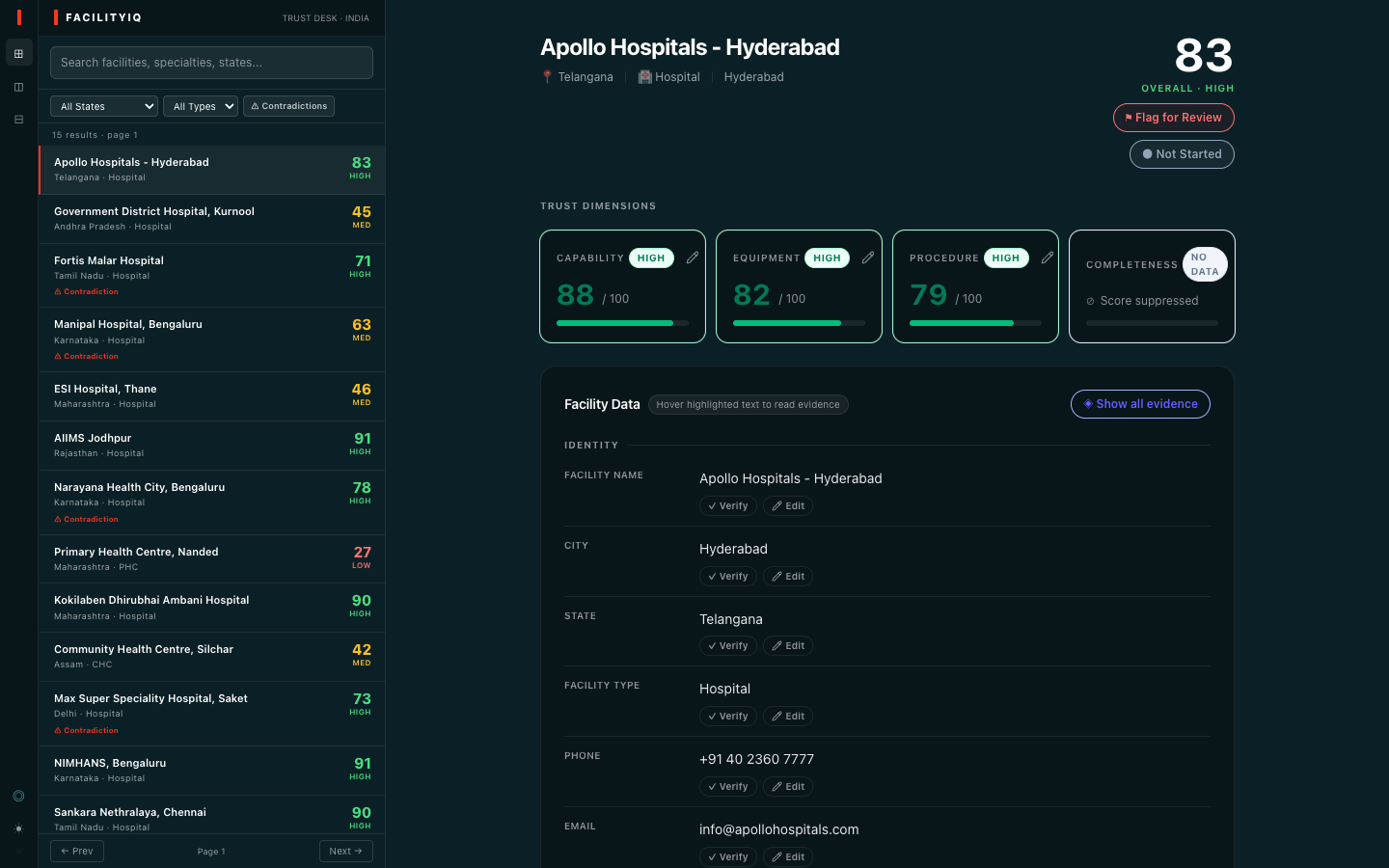
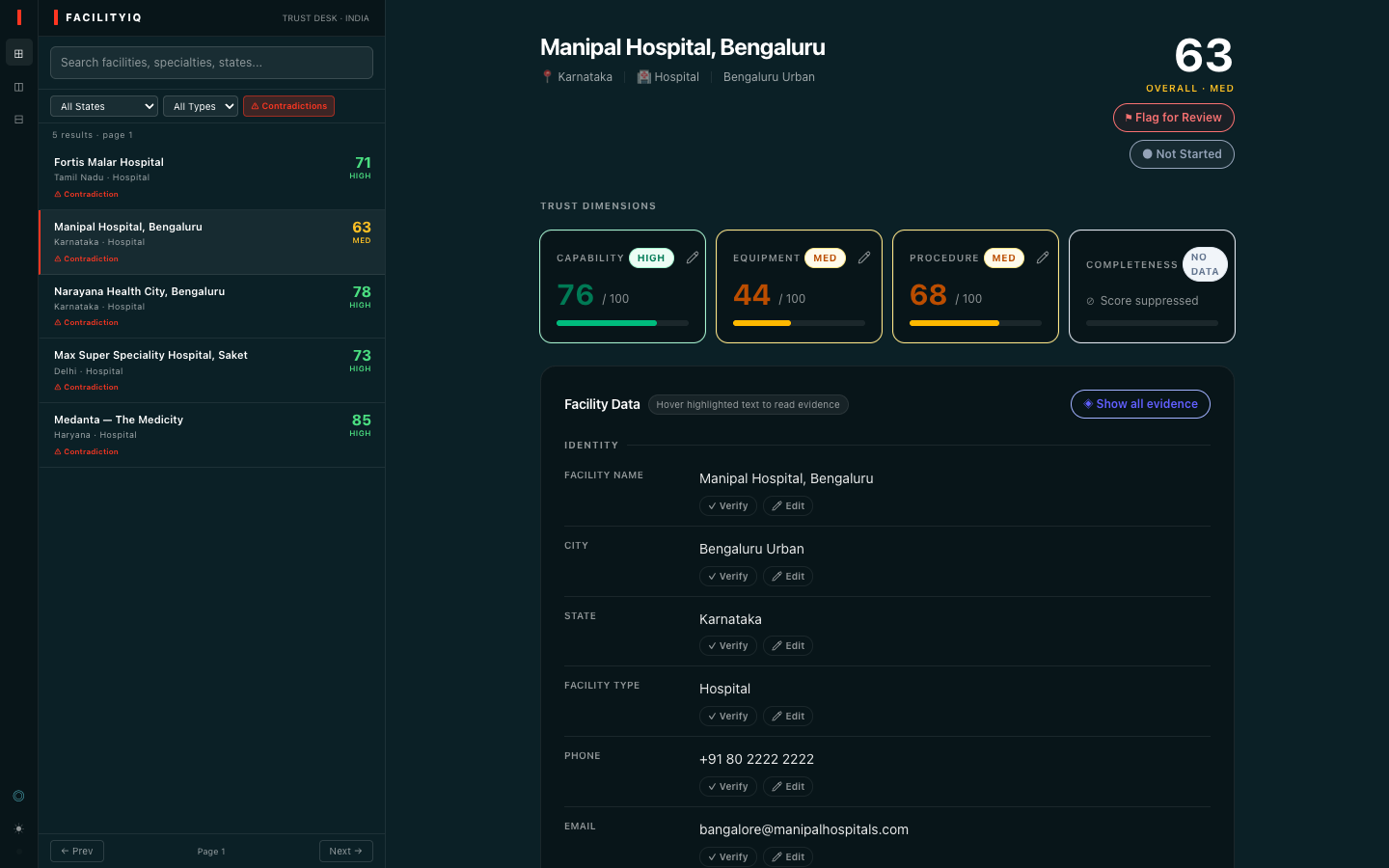
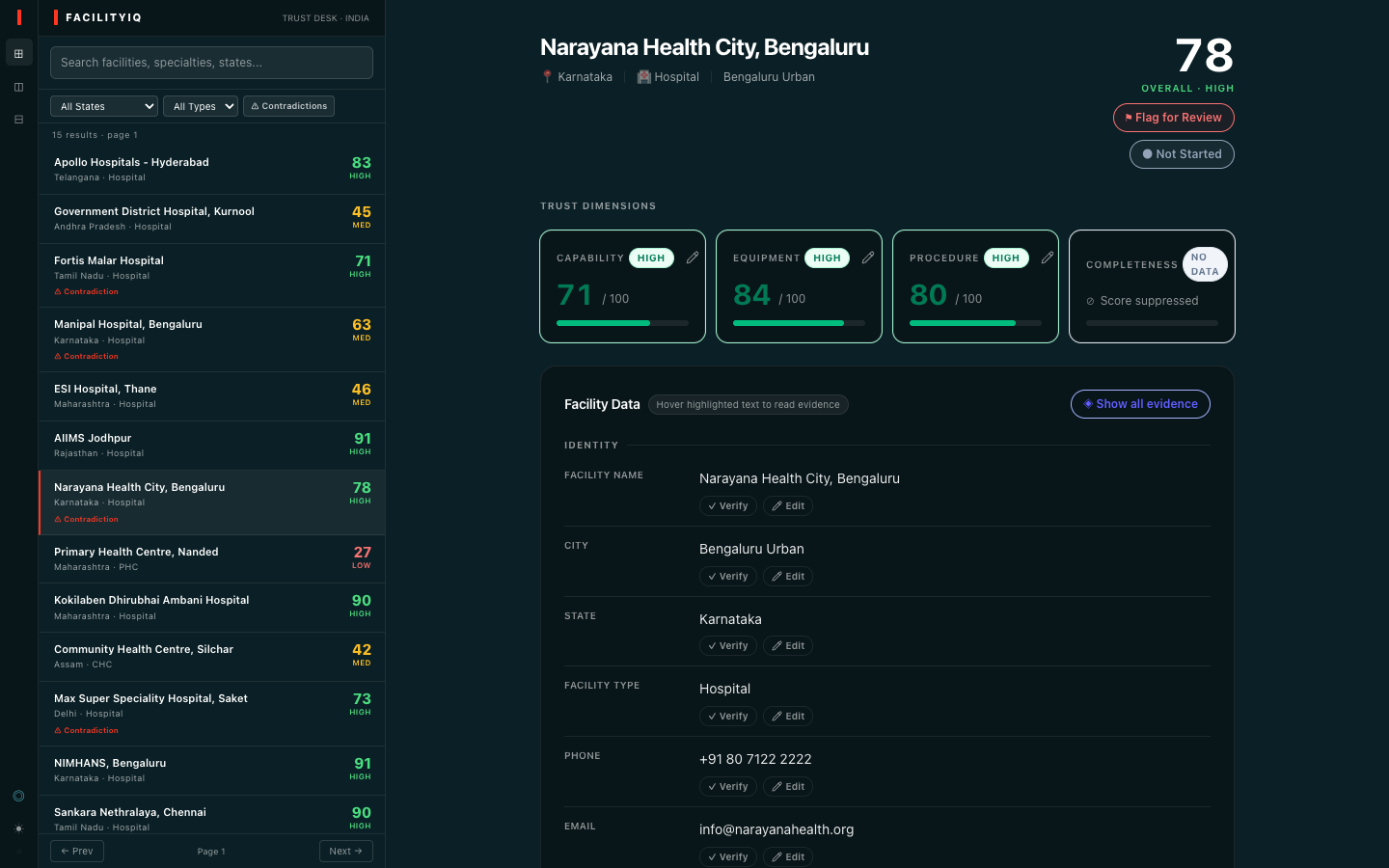
We work in language services - specifically healthcare language services, the industry that sits at the intersection of patient care, cultural nuance, and the terrifying responsibility of making sure the right information reaches the right people at the right moment. Every day, the question we answer is not just what did someone say, but should this be trusted - is this the right facility, the right capability, the right match for this patient's need?
When Virtue Foundation brought their India facility dataset to this hackathon, we didn't see 10,000 rows of structured data. We saw 10,000 conversations with no speaker verification. Facilities claiming cardiac surgery capability in free text while structured fields listed them as "Primary Health Centre." Records with capacity populated for only 1 in 4 facilities. year_established is present in fewer than half of the records. Free-text capability claims written with confidence, evidence nowhere to be found.
This is a problem we have spent our careers inside. In language services, an unverified claim in a healthcare context isn't a data quality issue - it is a routing error waiting to harm someone. We didn't build FacilityIQ because the hackathon asked us to use the Virtue dataset. We built it because we finally had a platform powerful enough to do what we have always wanted to do: turn unstructured healthcare claims into grounded, evidenced, trustworthy signals - at scale, in hours.
VF Match already shows you the facilities. FacilityIQ tells you whether to trust them.
How We Built It
FacilityIQ is a two-layer system: a Databricks LLM extraction pipeline that processes the raw facility dataset into structured trust signals, and a TypeScript/AppKit analyst workbench that surfaces those signals to planners in an interactive, evidence-anchored UI.
Layer 1 - The Trust Extraction Pipeline
The pipeline runs three notebooks in sequence, deployed as a DABs job:
FDR CSV → 00_setup.py → facilities_raw (Delta)
→ 01_trust_extraction.py → facilities_trust_signals (Delta)
→ facilities_quality_scores (Delta)
→ 02_validate_signals.py → validation report
Each facility gets a single LLM call to databricks-meta-llama-3-3-70b-instruct with temperature=0.0, extracting all four trust dimensions - capability, equipment, procedure, and completeness - in a single JSON response. One call per facility means 4× fewer API calls and the full record in context for cross-dimension contradiction detection.
Trust Score is an LLM-grounded signal: \(s_d \in [0, 1]\) for dimension \(d\), with evidence_text required to be an exact quote from the source field. The composite displayed in the UI is the mean over scoreable dimensions:
$$\bar{S} = \frac{1}{|D_{\text{scored}}|} \sum_{d \in D_{\text{scored}}} s_d \times 100$$
where \(D_{\text{scored}}\) excludes any dimension flagged insufficient_data.
Quality Score is computed separately - deterministically, in SQL - and answers a different question: not are the claims trustworthy but does the record itself have integrity. Each SQL check in sql/data_quality/ returns (facility_id, penalty_points, issue_summary). The score is:
$$Q = \max!\left(0,\; 100 - \sum_{c \in \text{checks}} \max_{f \in \text{failures}(c)} p_{c,f}\right)$$
where we take the worst penalty per check type to avoid double-counting repeated instances of the same issue. Tiers:
| Score range | Tier |
|---|---|
| \(Q \geq 85\) | high_quality |
| \(65 \leq Q < 8\) | needs_review |
| \(40 \leq Q < 65\) | low_quality |
| \(Q < 40\) | critical_issue |
Coverage guard - two fields fail a dataset-level coverage threshold and are permanently suppressed from scoring. Coverage is defined as the fraction of non-null, non-empty values across all 10,000 records:
$$\text{cov}(\text{capacity}) \approx 0.25, \quad \text{cov}(\text{year_established}) \approx 0.48$$
Any field with \(\text{cov} < 0.50\) always receives confidence_tier: "insufficient_data" and trust_score: null. An "Insufficient Data" badge is more honest than a low score that implies the field was assessed when it mostly wasn't.
Layer 2 - The Analyst Workbench
The app is a TypeScript/React frontend backed by an AppKit/Express server, deployed to Databricks Apps. Data flows from Delta tables into Lakebase Synced Tables (one-way Delta → Postgres sync), enabling sub-100ms reads for the app without Spark cold starts.
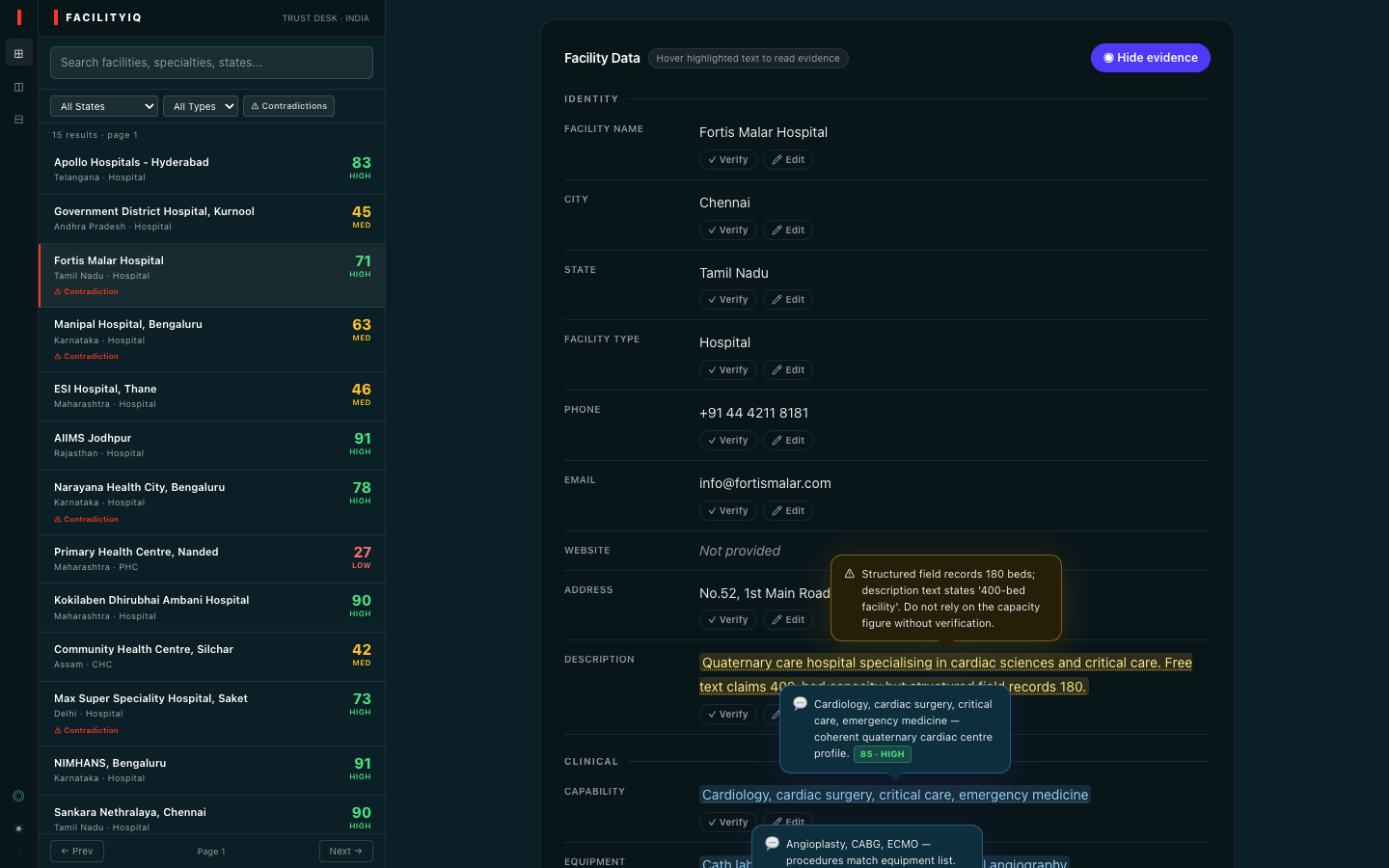
The centerpiece is GuidedAnalysis - a facility profile in which raw data is the primary surface, and AI evidence appears as floating annotation bubbles anchored to the exact phrases the model cited. The analyst sees the facility's own words; the trust signal is an annotation on those words, not a number that replaced them.
Analyst actions (notes, score overrides, flags) are written to a separate facilityiq.user_actions table in Lakebase Postgres and resolved latest-wins at read time. Overrides feed back into the Delta gold table, closing the loop from planner judgment to dataset improvement.
What We Learned
Sequential LLM loops do not scale - we learned this the hard way. The extraction pipeline processes each facility in a tight Python for loop, one LLM call at a time, with a one-second sleep between batches. At 10,000 facilities and roughly 4–5 seconds per call, the math is unforgiving:
$$T_{\text{total}} \approx N \cdot \bar{t}{\text{call}} + \left\lfloor \frac{N}{B} \right\rfloor \cdot t{\text{sleep}} \approx 10{,}000 \times 4.5\text{s} + 200 \times 1\text{s} \approx 13\text{ hours}$$
The pipeline ran from Sunday evening into Monday morning. In hindsight, the fix is straightforward: load the DataFrame with Spark, apply the LLM call via a pandas_udf or applyInPandas, and let the cluster distribute the work across workers. We never triggered Spark at all - we just called .toPandas() and looped. That's the one architectural decision we'd change first.
Design pipeline restarts before you need them. We built a skip-list that prevents re-processing already-extracted facilities by querying the output table. The logic was sound, but the query crashed if the table didn't exist yet on a clean first run. We found this bug at 5:38 am, mid-run, and fixed it while the pipeline was still going. Build the idempotent guard before you start the job, not after you hear the error in the logs at 5am.
Schema decisions mid-pipeline are expensive. At 8:53pm - after the extraction run was already underway - we caught that trust_score was declared FLOAT in the setup notebook. LLM outputs were being silently truncated. The fix was a one-line schema change, but it required stopping the run, dropping and recreating the table, and restarting from scratch. Type your output schema against your actual model output before you kick off 13 hours of API calls.
Separating Trust Score from Quality Score was a mid-session insight, not a planned design. The original pipeline conflated record quality and claim trustworthiness into one pass. Around 1 pm on Day 1, we split them: Trust Score from the LLM, Quality Score from deterministic SQL checks. The separation made both scores meaningful and independently actionable. It also cleaned up the UI considerably - two distinct numbers with two distinct explanations are far easier for an analyst to act on than one muddled composite.
Evidence grounding is harder than scoring. The model will hallucinate plausible evidence if you give it room to do so. Getting evidence_text to be a verbatim quote from the source field - not a paraphrase, not a summary - required explicit prompt rules that treat a missing quote as grounds for returning insufficient_data. We validated extractions by checking evidence_text as a substring of the original field value; anything that failed the substring match was flagged for review.
Lakebase Synced Tables are genuinely production-grade. The Delta → Postgres sync is fast, reliable, and the correct boundary between pipeline output and app reads. We expected rough edges; we did not find them.
Challenges
The pipeline ran for 13 hours overnight. This was the defining constraint of the hackathon for us. We started the extraction Sunday evening and watched it run through the night. By the time 10,000 facilities had been scored, it was Monday morning, and we were already deep into the UI build on a parallel branch. We got the data we needed, but the timeline left no room for iteration on the extraction itself. If we had distributed the LLM calls across a Spark cluster instead of looping in Python, the same job would have run in roughly 30–45 minutes.
DABs configuration was a sustained source of friction. Deploying two bundles - one for the data pipeline, one for the app - with distinct names, targets, auth methods, and workspace paths produced a string of fixes across multiple PRs: conflicting bundle names, notebook source path mismatches, an oauth-m2m auth change that required reverting a force push, and root path updates that broke the app deployment. DABs are powerful once they are configured correctly. Getting it configured the first time correctly, under time pressure, is a grind.
A schema type error appeared mid-pipeline. trust_score was declared FLOAT in the table setup. The LLM returns scores as JSON floats, which Spark silently truncated on write. We caught the mismatch at 8:53pm - after the run had been going for hours - changed the schema to DOUBLE, and had to restart from zero. The lesson is simple and now permanently in our heads: validate your output schema against a sample LLM response before launching a multi-hour batch job.
React Joyride's v3 API is not its v2 API. The guided demo tour was the last feature we built, squeezed into the morning of Day 2. We installed the library, wired it up against the v2 documentation we had referenced in planning, and hit immediate runtime errors: onEvent, LIFECYCLE, and the options interface all changed between versions. An hour of debugging on submission morning to resolve an API version mismatch is exactly the kind of friction you do not want at that stage.
The circular import that TypeScript quietly tolerated until it didn't. The tour module needed an AppView type that lived in App.tsx. Importing it created a circular dependency. TypeScript gave no compile error - the import appeared to work until runtime, when the type resolved to undefined. The fix was a local re-declaration of AppView in the tour module. Five minutes to fix; longer to diagnose.
After two days, FacilityIQ had processed 10,000 facilities, extracted 40,000 trust signals, and deployed a live analyst workbench on Databricks Apps. Every score cites the exact text that produced it. Every uncertainty is surfaced visibly. Every analyst decision persists.
In language services, we say that trust is not given - it is earned, phrase by phrase. That is exactly what we built.
What's Next for FacilityIQ
Conversational facility discovery. The current analyst workbench is search-and-filter. The natural next step is a chat interface backed by an agent that understands the trust-signal schema: "Find facilities in Tamil Nadu that can perform cardiac surgery with a capability trust score above 80 and no contradictions."* That query requires no special UI - just an agent with read access to Lakebase and the ability to reason about trust tiers, dimension scores, and confidence levels together.
Automated outreach to validate data at the source. The most powerful validator of a facility's claims is the facility itself. An agent-driven outreach pipeline could draft and send structured verification requests to facilities flagged with contradictions or low trust scores, then parse responses to update the record. Combined with web search and public-record scraping - ministry registries, hospital accreditation databases, news archives - this turns FacilityIQ from a static analysis tool into a self-improving dataset.
Score recalculation when analyst overrides are approved. Right now, analyst overrides persist in the database but do not trigger a pipeline re-run. The correct behavior is a feedback loop: when a second analyst approves an override, the pipeline should re-score the affected facility using the corrected field values, propagate the change through the medallion layers, and surface the updated trust signal in the UI. This closes the loop from human judgment to dataset improvement in a way that scales with the analyst team.
Broader dataset coverage. The pipeline is not India-specific. The trust extraction prompt, quality scoring SQL, and evidence-grounding rules all operate on the schema, not on geography. Extending FacilityIQ to VF Match's full global dataset - or to other countries' facility registries - is a configuration change, not a rewrite.
Built With
- databricks
- lakebase
- postgresql
- python
- react
- typescript
- vite

Log in or sign up for Devpost to join the conversation.