-
Home page
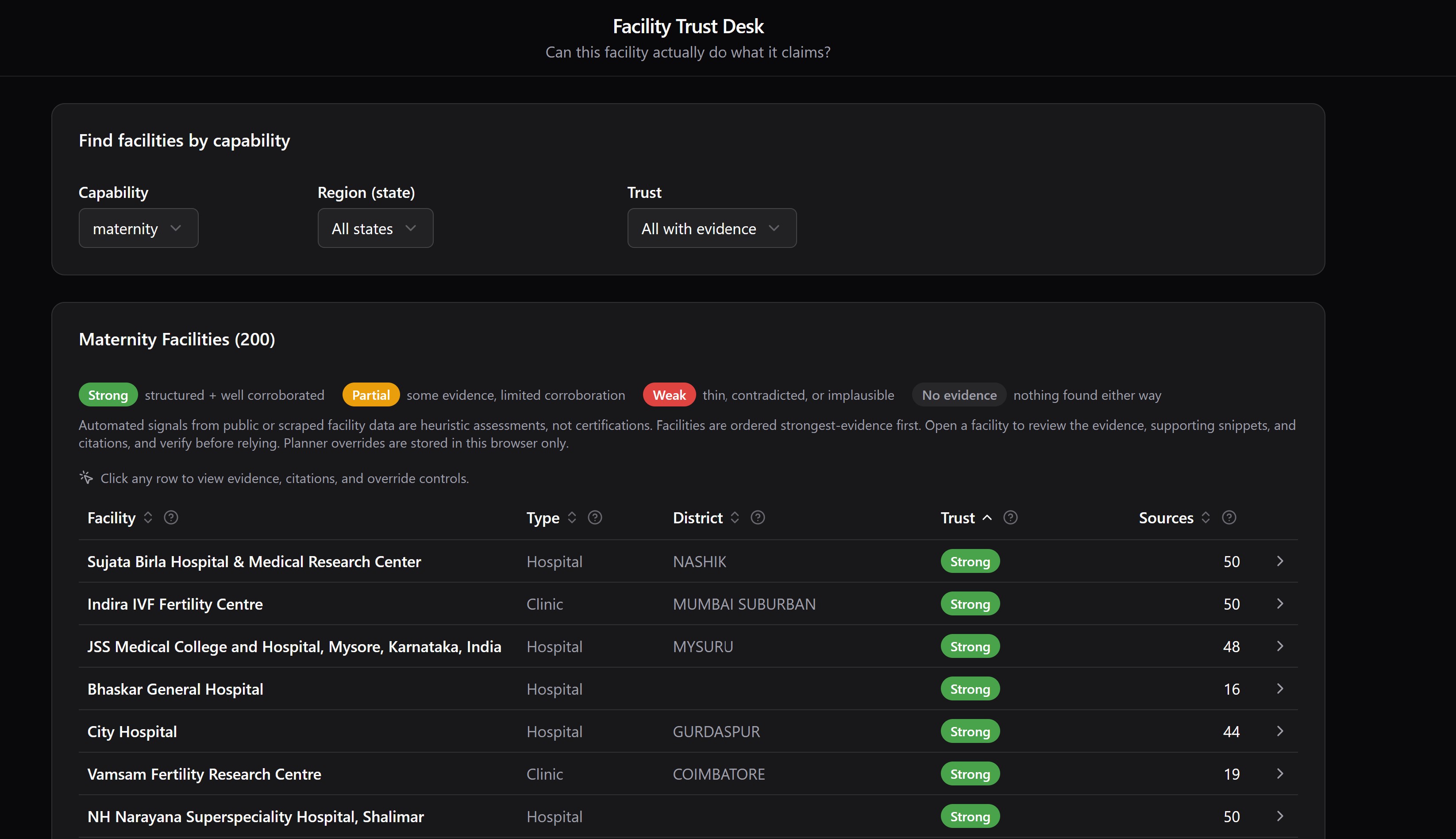
Facility Trust Desk
Inspiration
The DAIS 2026 Track 1 dataset has ~10,000 Indian healthcare facilities with self-claimed capabilities, and no good way to know if any of them can actually do what they claim. Dental clinics show up claiming oncology. Hospitals show up with coordinates in the Atlantic. We wanted a planner-facing tool that treats that messiness as an explicit, auditable part of the answer instead of hiding it under one confidence score.
What it does
For each facility x capability pair across six Track 1 capabilities (ICU, NICU, maternity, emergency, oncology, trauma), Facility Trust Desk returns one of four trust signals: strong, partial, weak_suspicious, no_claim.
Planners pick a capability and region in the Databricks AppKit web app and see ranked facilities with the trust tier, matched evidence snippets, citation URLs, and LLM-surfaced supporting snippets. They can override a tier and add a free-text note that's stored per-browser in localStorage.
A deterministic SQL rule always owns the final tier. An optional LLM sidecar refines ambiguous sub-signals as inputs to that rule — it never writes the tier directly.
How we built it
- Medallion SQL pipeline — 10 numbered scripts take the raw catalog through
silver(cleaned) togold(serving). Pincode → district → state lookup repairs broken geography; NFHS-5 indicators add district demand context. - Databricks AppKit web app — React + Vite client using the Analytics plugin against a SQL warehouse, planner overrides in
localStorage, deployed as a Databricks App via Asset Bundles. - Python LLM review runner — Pydantic + Databricks JSON-schema response format for typed I/O, prompt versioning, parallel scoring with QPS pacing, group-by-facility batching. Writes back to
silver.facility_capability_llm_outputs_raw;--refresh-goldrebuilds the LLM signal and final assessment tables. - Two provider paths — Databricks model serving (default Llama 3.1 8B) or the OpenAI Responses API, both writing back through the same Databricks SQL tables.
Challenges we ran into
Dirty data. 254 distinct "states" (should be ~36), 493 state mismatches, JSON blobs in ID columns, literal
"null"strings everywhere. We added anevidence_fingerprintjust so the LLM layer could distinguish current, stale, and missing reviews.Keeping the tier deterministic with an LLM in the loop — resisted letting the model write the tier; deterministic SQL recomputes it from versioned sub-signals.
Accomplishments that we're proud of
- A complete planner workflow end-to-end: clean → score → rank → drill-down → override → audit.
- A two-layer trust engine where the LLM measurably improves ambiguous cases (e.g. a clinic that claims oncology but is really screening-only drops from
strongtoweak_suspicious) without ever overriding the deterministic rule. - 9,932 unique facilities after dedup; 9,572 pincode-matched; 6,174 joinable to NFHS district indicators.
- Typed, versioned, parallel LLM I/O with stale-vs-current detection built in.
What we learned
- Cleaning is the work. The hard part of "can this facility do what it claims?" was repairing geography and parsing JSON-in-strings, not the model call.
- Determinism is a feature. Recomputing the tier deterministically from versioned sub-signals beats letting an LLM write tiers directly — planners need to know why.
- Group-by-facility prompts were dramatically cheaper than per-
(facility, capability)calls, with no quality loss. - Schema-constrained outputs turned the LLM step from "parse a probably-OK string" into a regular pipeline stage.
- A missing metric beats a misleading one.
What's next for Facility Trust Desk
- Real citation-support grading — crawl each
source_urls[], extract per-claim snippets, and grade evidence per claim. - Broader capability catalog beyond the six Track 1 buckets, using
specialtiesas the spine (213 specialties with ≥25 mentions) plus curated service capabilities (dialysis, cath lab, PET-CT, ...). - Move overrides to a Delta- or Lakebase-backed audit table with reviewer identity and shareable review queues.
Built With
- databricks
- python
- sql
- typescript

Log in or sign up for Devpost to join the conversation.