-
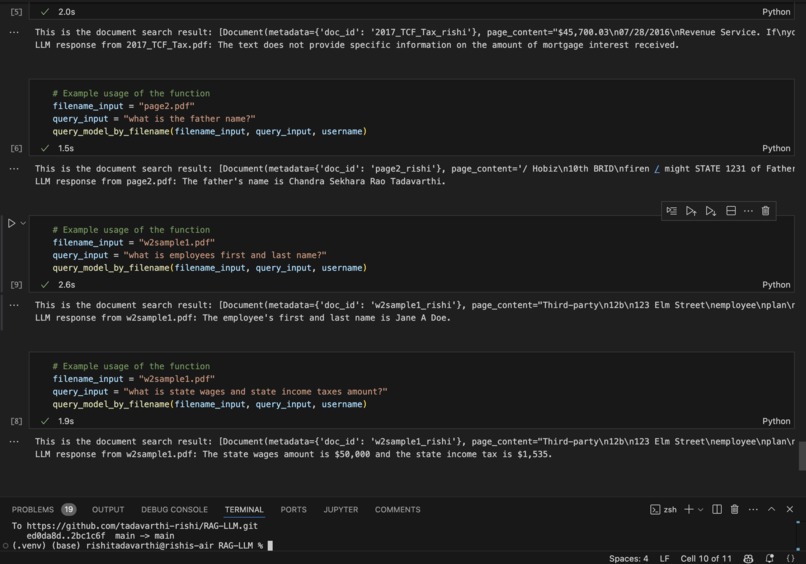
LLM response based on our query
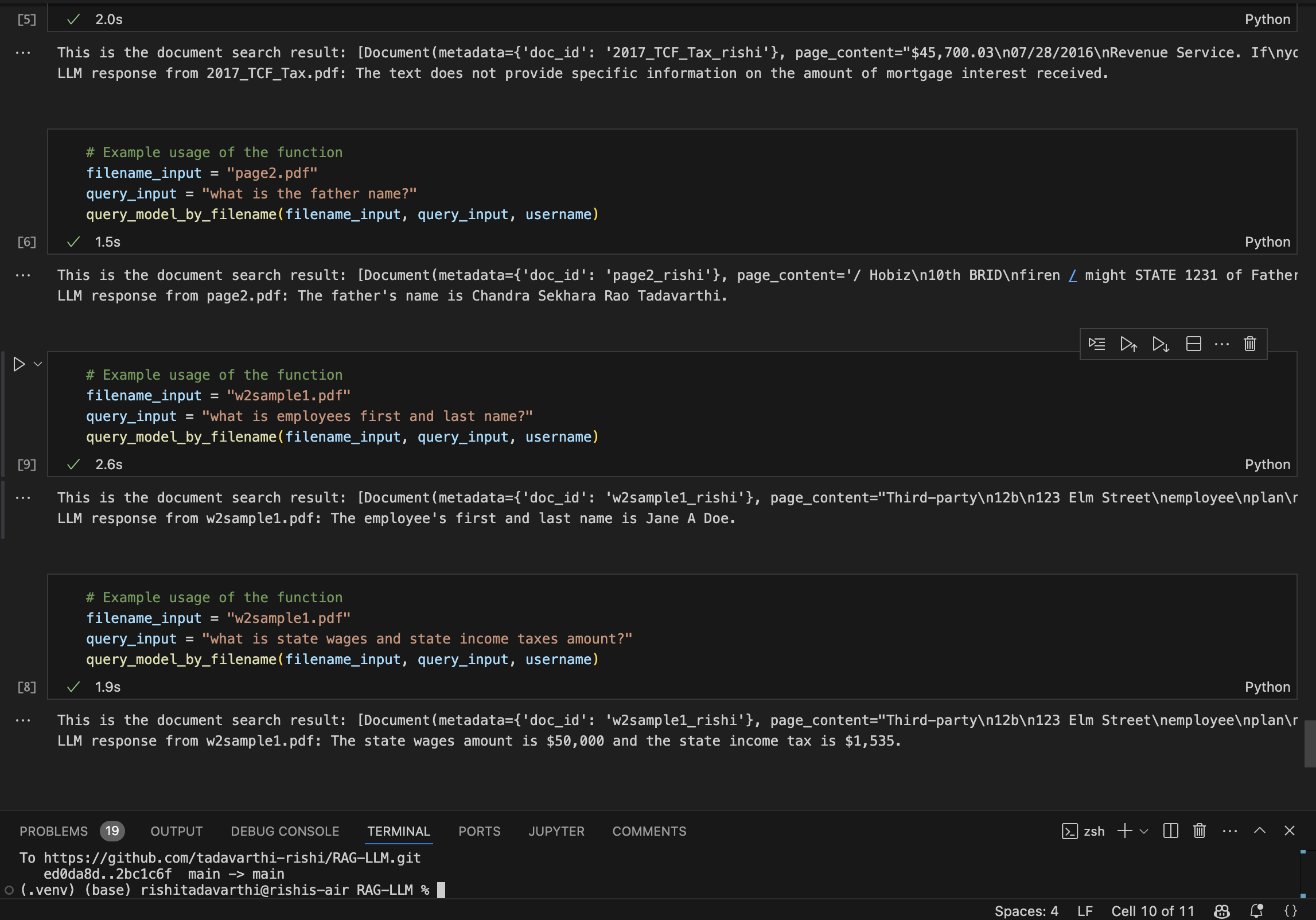
Smart RAG-LLM
Inspiration
The inspiration for this project came from the need to provide accurate and context-aware responses based on uploaded documents. Leveraging the power of Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs), we aimed to create a system that can understand and generate responses based on the content of various documents.
What it does
Smart RAG-LLM processes and understands documents, retrieves relevant information, and generates accurate responses to user queries. It integrates document loading, text extraction, embedding generation, and LLM-based response generation to provide a seamless user experience.
How we built it
- Document Loading: We used the
PyPDFDirectoryLoaderfrom LangChain to load PDF documents from a specified directory. - Text Extraction: We utilized
textractto extract text from various document formats, ensuring that the content is accurately captured for further processing. - Text Splitting: The
RecursiveCharacterTextSplitterwas employed to split the loaded documents into manageable chunks. - Embedding Generation: We utilized the
OpenAIEmbeddingsto generate embeddings for the document chunks. - Vector Store: Pinecone was used to store and manage the document embeddings.
- LLM Integration: We integrated OpenAI's language models to generate responses based on the retrieved document embeddings.
- Query Handling: Functions were created to handle user queries, retrieve relevant document chunks, and generate responses using the LLM.
Challenges we ran into
- Data Handling: Managing and processing large documents efficiently was a significant challenge. We had to ensure that the text splitting and embedding generation processes were optimized.
- Integration Issues: Integrating multiple libraries and ensuring they worked seamlessly together required extensive debugging and testing.
- Performance Optimization: Ensuring the system responded quickly and accurately to user queries involved fine-tuning the model parameters and optimizing the data retrieval process.
Accomplishments that we're proud of
- Successfully integrating multiple technologies and libraries to create a cohesive system.
- Optimizing the document processing pipeline to handle large datasets efficiently.
- Achieving accurate and context-aware responses from the LLM based on the retrieved document content.
What we learned
Throughout the development of this project, we learned how to integrate multiple technologies and libraries such as OpenAI, LangChain, Pinecone, and textract. We also gained insights into handling document processing, text extraction, and embedding generation. Additionally, we explored the challenges of working with large datasets and optimizing the performance of our models.
What's next for Smart RAG-LLM
- Api gateway: Currently working on AWS CDK to create multiple stacks for s3, lambdas, api gateway, sns so user can upload a file from UI and it will be stored in s3 and triggers lambda function to call textract and then do the further process as same from this already developed project, which can improve the performance using AWS services.
- Enhanced Document Support: Expanding support for more document formats beyond PDFs.
- Improved Query Handling: Enhancing the query handling mechanism to provide even more accurate and context-aware responses.
- Scalability: Improving the scalability of the system to handle larger datasets and more concurrent users.
- User Interface: Developing a user-friendly interface to make the system more accessible to non-technical users.
Built With
- a
- api
- cdk
- gateway:
- iam:
- lambda:
- langchain
- llm
- manager:
- openapi
- pinecone
- python
- restful
- s3:
- sdk
- secrets
- textract:
- typescript
- vectors

Log in or sign up for Devpost to join the conversation.