

Attentive AI
Inspiration
Human communication is not limited to verbal speech alone. Even something as simple as silence, a gesture, eye movement, or the slightest shift in tone can completely change the meaning behind what someone says. However, many current AI systems are limited to processing text, missing the emotional signals that make human interaction feel meaningful and genuine.
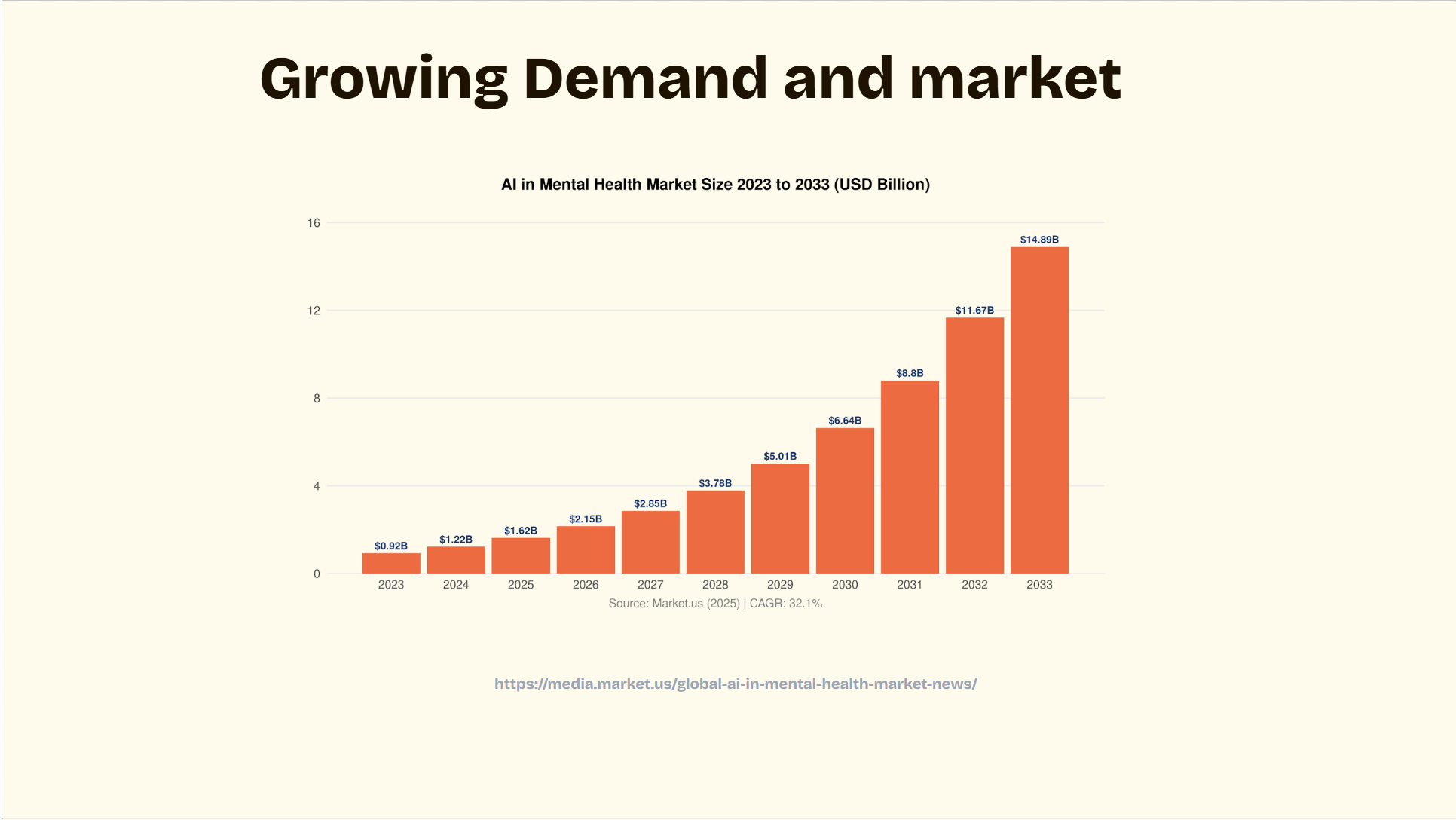
Loneliness, depression, anxiety, and emotional isolation have quietly become some of the biggest challenges of the digital generation. Millions of people communicate every day through screens, yet many still feel emotionally unheard and misunderstood.
This inspired us to ask a simple question:
What if AI could understand not just our words, but the emotions behind them?
That idea became AttentiveAI — a real-time multimodal emotion-aware communication system designed to analyze facial micro-expressions, vocal tone, speech patterns, and conversational context simultaneously.
What it does
AttentiveAI is a real-time emotionally aware AI interaction system that uses webcam and microphone input to analyze human emotions beyond text alone.
The system can process:
- Facial micro-expressions
- Eye movement and facial tension
- Vocal tone and speech emotion
- Conversational context
- Behavioral emotional patterns
By combining multiple emotional signals simultaneously, AttentiveAI creates interactions that feel more human-centered, emotionally aware, and supportive than traditional AI systems.
Users can also customize different AI face models and personalities, allowing them to choose avatars that feel warmer, more welcoming, and more relatable to themselves. This creates a more emotionally comfortable and personalized interaction experience.
Unlike human conversations, where emotions may sometimes be overlooked due to bias, exhaustion, or social pressure, AttentiveAI continuously analyzes emotional patterns through algorithms in real time. In some situations, this allows the system to detect subtle emotional changes that people may unintentionally miss.
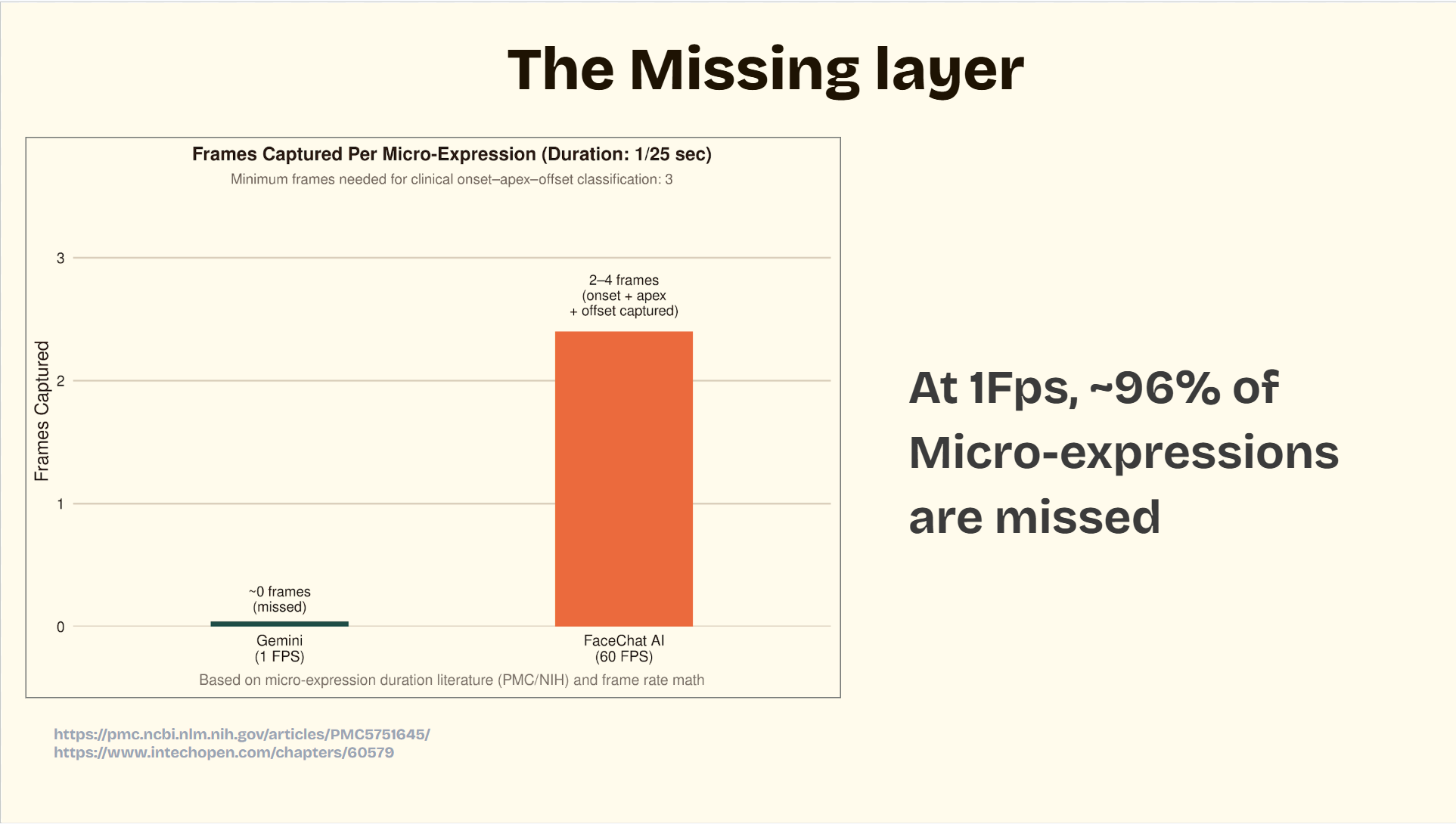
The platform operates at approximately 60 FPS, enabling smooth real-time emotional analysis and interaction.
How we built it
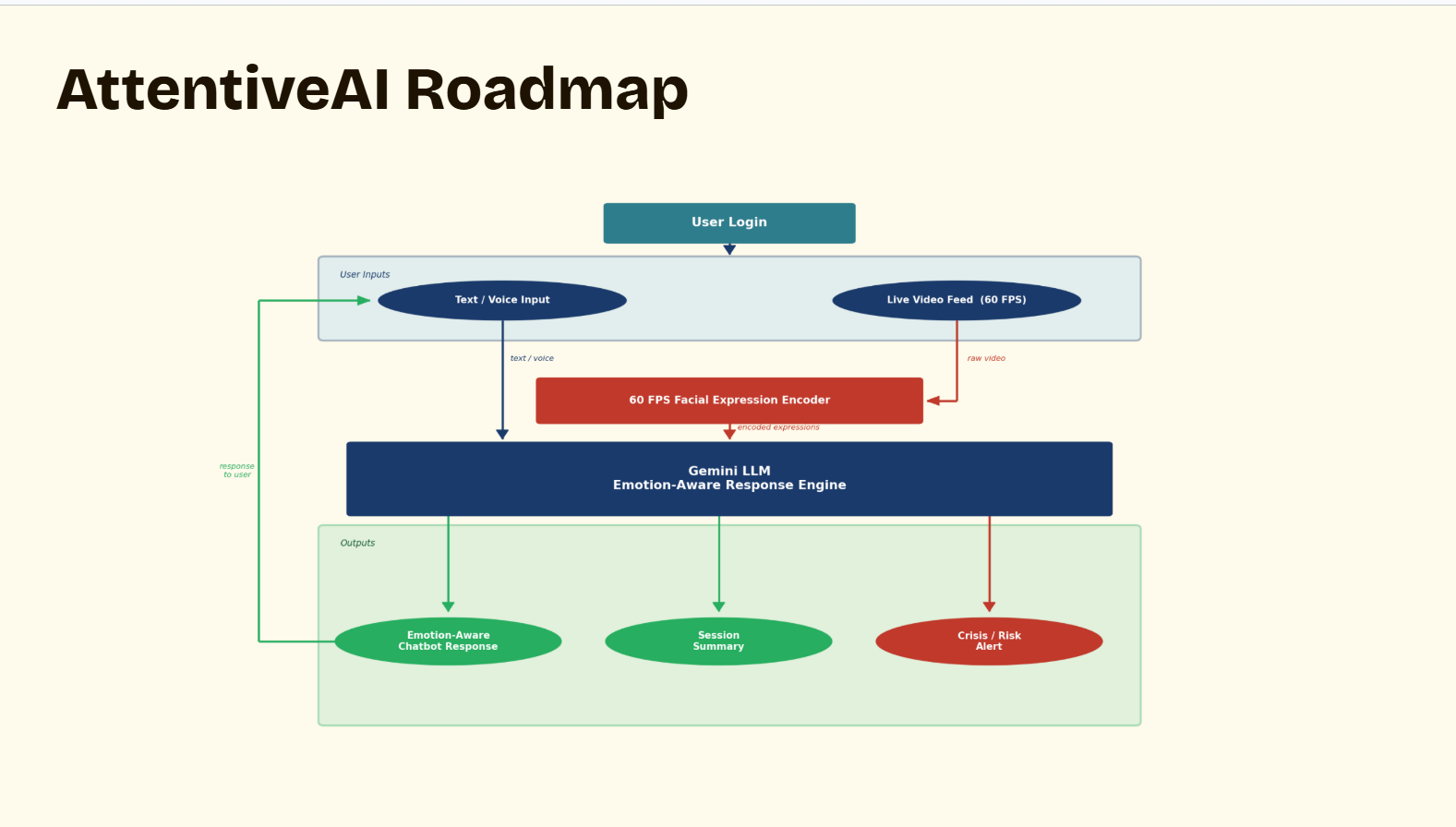
We built AttentiveAI using a multimodal AI pipeline that combines computer vision, facial expression encoding, real-time inference systems, and large language models.
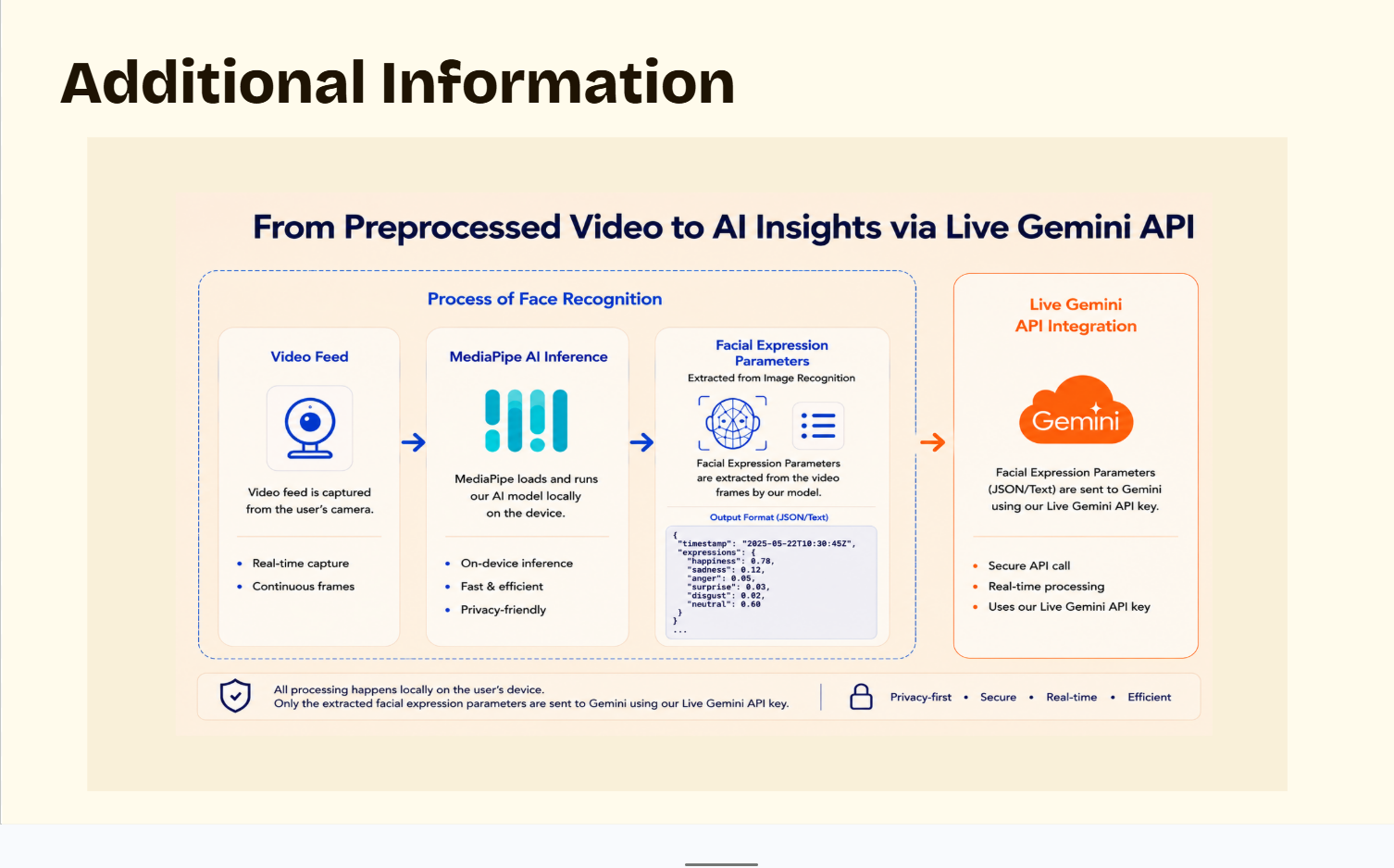
For facial analysis, we developed a custom facial-expression encoding pipeline capable of processing video streams at approximately 60 FPS. Instead of relying entirely on standard video inference from Gemini, we used our own preprocessing system to extract high-frequency emotional and facial micro-expression data directly from webcam input. This allowed us to capture subtle emotional transitions that are often missed at lower frame rates.
The video feed is processed locally using MediaPipe AI inference pipelines and PyTorch-trained emotion recognition models. Facial landmarks, blendshape parameters, eye movement, and facial tension are converted into structured JSON/text embeddings representing emotional states in real time.
At the same time, live microphone input is streamed directly into the Gemini API for conversational understanding and speech analysis. By combining both audio and facial-expression embeddings, Gemini can generate emotionally aware responses that take into account both what the user says and how they emotionally express it.
On the frontend side, we designed customizable AI avatars and emotionally adaptive interfaces to create a warmer and more approachable user experience. The system architecture also supports therapist summaries, emotional memory, crisis/risk alerts, and personalized AI interactions.
Our stack included:
- PyTorch for emotion-recognition model training
- MediaPipe AI inference for on-device model execution
- Gemini Live API for conversational reasoning
- Real-time webcam and microphone processing pipelines
- Frontend avatar and UI systems for interactive communication
Challenges we ran into
One of the biggest challenges we faced was balancing real-time performance with emotional recognition accuracy. Human emotions can change extremely quickly, especially through micro-expressions that may only appear for fractions of a second. Most existing APIs process video at very low frame rates, making subtle emotional transitions difficult to detect reliably.
Another challenge was coordinating multiple streams of information simultaneously. Facial expressions, voice tone, speech content, and conversational history can sometimes contradict each other, requiring the AI system to interpret emotional context carefully instead of relying on a single signal.
Real-time optimization was also difficult. Processing webcam input, facial landmark extraction, emotional encoding, audio streaming, and Gemini API responses simultaneously required careful optimization to maintain smooth low-latency interaction around 60 FPS.
We also encountered challenges involving privacy and ethical considerations. Since emotional analysis can be highly sensitive, we focused heavily on privacy-first architecture and local preprocessing so that only encoded emotional embeddings — rather than raw video streams — are sent into the language model pipeline whenever possible.
Finally, designing emotionally aware AI without making interactions feel artificial was a major challenge. We wanted the system to feel supportive, natural, and emotionally intelligent rather than robotic or overly scripted.
🏅 Accomplishments That We're Proud Of
What’s most remarkable is our ability to create an entire system based on real-time multimodal AI that has the capability of analyzing and interpreting human emotions based on multiple streams of input. AttentiveAI can process multiple streams of information from facial microexpressions, tone of voice, speech patterns, and even conversations at around 60 FPS. This makes the entire user experience more human-like as compared to the typical machine-based interactions that conventional AI technologies offer. We managed to convert a theoretical concept into reality through the combination of computer vision, audio analysis, and real-time inference pipelines.
📚 What We Learned
Our creation of the AttentiveAI system has taught us just how difficult human-centered AI actually is. We have gained practical experience with computer vision technology, multimodal AI processing systems, optimization for real-time inference, and real-time frontend/backend coordination. Moreover, we discovered the complexity involved in reading human emotions because facial expressions, voice intonations, and even the content of the speech may contradict each other. We have learned how to build interactions that appear natural and not forced, by taking into account the requirements of speed, efficiency, and emotion recognition accuracy. Finally, through creating the system, we realized that the next step in the evolution of AI is to make it more emotionally conscious.
What's next for AttentiveAI
- Improve emotional accuracy using larger multimodal datasets and advanced real-time inference systems
- Increase micro-expression detection precision through higher temporal resolution processing at approximately 60 FPS
- Develop emotionally adaptive AI avatars and customizable personalities
Additional future goals include:
- Multilingual emotional understanding
- Personalized AI personalities and face models
- Long-term conversational emotional memory
- Accessibility and mental health support applications
- Privacy-focused on-device emotional inference
- More advanced real-time behavioral analysis
AttentiveAI is ultimately an experiment in making technology feel less cold — and making digital conversations feel more human.
Built With
- gemini
- mediapipe
- python
- three.js
- typescript




Log in or sign up for Devpost to join the conversation.