-
-
-

Gradio App
-
Gradio App

FabMi: Exploring LLM Fine-Tuning for Semiconductor Defect Analysis
Inspiration
A Gap Between Detection and Understanding
In semiconductor manufacturing, AI-powered defect detection has matured significantly—vision systems can classify defect patterns with high accuracy. However, the reasoning step that follows remains largely manual: understanding why a defect occurred and how to fix it.
This root cause analysis (RCA) typically requires experienced process engineers who can:
- Correlate subtle patterns: "Wafers 3, 5, 7, 9 affected → likely FOUP slot contamination"
- Apply domain knowledge: "RF-hours approaching 3,000 → check O-ring condition"
- Recommend specific actions: "Inspect part P/N 839-0234, verify leak rate"
With the semiconductor industry growing toward $1 trillion and experienced engineers becoming scarce, I was curious: Could a small, fine-tuned LLM learn to assist with this reasoning task?
This project was my exploration of that question.
What I Built
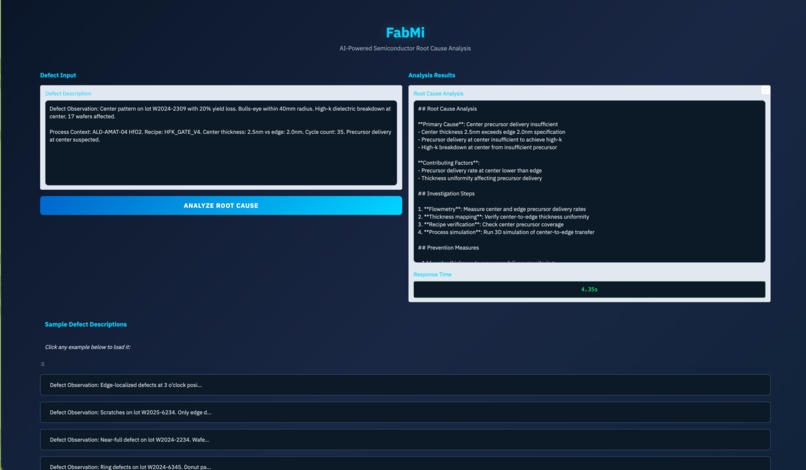
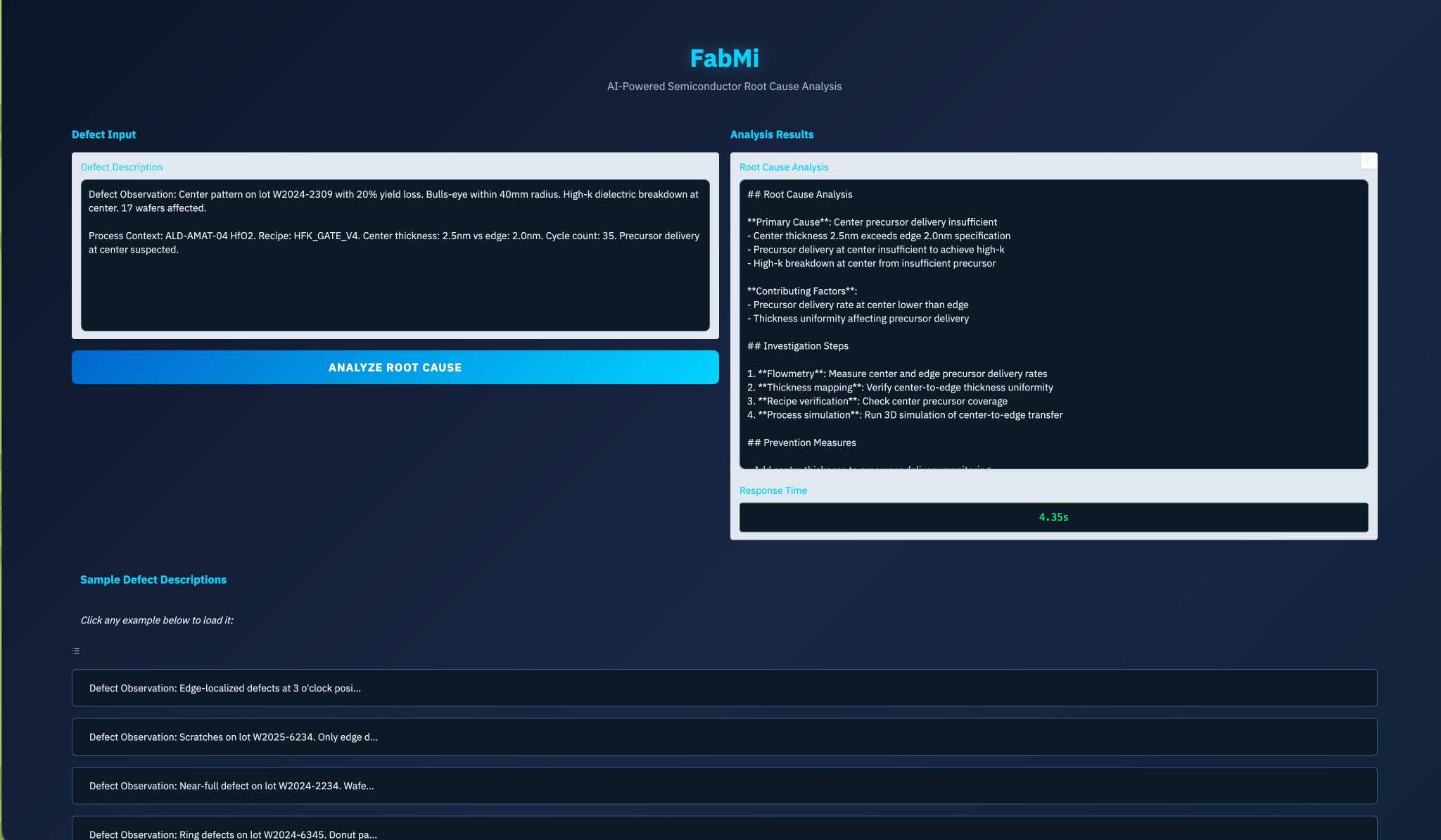
FabMi is a fine-tuned ERNIE-4.5-0.3B model that generates structured root cause analysis reports for semiconductor wafer defects. Given a defect observation and process context, it produces outputs like:
## Root Cause Analysis
**Primary Cause**: O-ring seal degradation in etch chamber
- RF-hours (2,847) approaching 3,000-hour limit
- Edge-ring pattern suggests gas leakage at chamber seal
## Corrective Actions
1. **Immediate**: Tool down ETCH-LAM-07
2. **Inspect**: Main chamber O-ring for degradation
3. **Replace**: O-ring P/N 839-0234 (Viton, ID 350mm)
4. **Verify**: Leak rate < 1 mTorr/min after replacement
**Severity**: Critical | **Yield Impact**: 15%
Results
I compared the fine-tuned 0.3B model against a zero-shot 21B baseline on a held-out test set:
| Metric | Baseline (21B zero-shot) | FabMi (0.3B fine-tuned) |
|---|---|---|
| ROUGE-L | 0.063 | 0.446 |
| ROUGE-1 | 0.101 | 0.561 |
| ROUGE-2 | 0.028 | 0.282 |
| Severity Accuracy | 20.0% | 60.0% |
| Structure Score | 35.5% | 88.0% |
The results suggest that domain-specific fine-tuning can help smaller models perform reasonably well on specialized tasks, even compared to larger models used zero-shot.
How I Built It
1. Synthetic Data Generation
Real semiconductor RCA data is proprietary and hard to obtain. I created synthetic training data using multiple LLMs (Claude, Gemini, GPT, Grok) to ensure diversity:
$$\mathcal{D} = \bigcup_{i \in {\text{sources}}} \mathcal{D}_i$$
I generated 1,511 samples across 9 defect types:
| Defect Pattern | Samples | Example Root Cause |
|---|---|---|
| Edge-Ring | 242 | Seal degradation |
| Donut | 186 | Edge ring wear |
| Center | 180 | Showerhead issues |
| Scratch | 174 | Mechanical damage |
| Edge-LOC | 162 | Chuck contamination |
| Random | 158 | Particle sources |
| LOC | 152 | Localized contamination |
| Near-Full | 147 | Process failures |
| None | 110 | Normal baseline |
Each sample captures domain-specific reasoning patterns, such as:
Input: "Wafers 3,5,7,9 affected, slots 1,2,4,6,8 clean"
Reasoning: Odd-slot pattern → FOUP-side contamination
(not robot arm, which would show sequential pattern)
2. Fine-Tuning with LoRA
I used LLaMA-Factory to fine-tune ERNIE-4.5-0.3B-PT with Low-Rank Adaptation (LoRA):
$$W' = W_0 + BA$$
Where $B \in \mathbb{R}^{d \times r}$, $A \in \mathbb{R}^{r \times k}$, with rank $r = 16$.
Training setup:
- Base model:
baidu/ERNIE-4.5-0.3B-PT - LoRA config: rank=16, alpha=32
- Learning rate: $5 \times 10^{-5}$ with cosine decay
- Training: 10 epochs
- Data split: 90/10 train/test (1,356 / 155 samples)
The resulting LoRA adapter is only 24MB, making it easy to share and deploy.
3. Evaluation Approach
I evaluated using multiple metrics to capture different aspects of output quality:
- ROUGE scores: Measure textual overlap with reference outputs
- Severity accuracy: Whether the model correctly classifies Critical/Major/Minor
- Structure score: Presence of expected sections (Root Cause, Corrective Actions, etc.)
$$S_{\text{structure}} = \frac{1}{n}\sum_{i=1}^{n} \mathbb{1}[\text{section}_i \in \text{output}]$$
Challenges Faced
Challenge 1: Training Data Scarcity
Problem: Semiconductor RCA data is proprietary and not publicly available.
Solution: I used multiple LLMs to generate diverse synthetic training samples, encoding domain-specific reasoning patterns based on publicly available semiconductor process knowledge.
Challenge 2: Output Format Consistency
Problem: LLMs often produce inconsistent formats, making downstream integration difficult.
Solution: I used consistent Alpaca-style formatting across all training samples:
{
"instruction": "Analyze semiconductor defect...",
"input": "Defect observation + process context",
"output": "Structured markdown RCA report"
}
This achieved 88% structure score on the test set.
Challenge 3: Evaluation Design
Problem: No standard benchmark exists for semiconductor RCA evaluation.
Solution: I designed a multi-metric evaluation framework:
- ROUGE scores for textual quality
- Severity classification accuracy
- Structure score for format compliance
Challenge 4: Efficient Model Selection
Problem: Balancing model capability with deployment efficiency.
Solution: LoRA fine-tuning on ERNIE-4.5-0.3B achieved strong results while keeping the adapter size at just 24MB—practical for real-world deployment.
What I Learned
Domain-specific fine-tuning is effective: A small model with targeted training data can perform well on specialized tasks, even compared to larger models used zero-shot.
Multi-source synthetic data works: Using multiple LLMs to generate diverse training data helped create a robust dataset covering various reasoning patterns.
Structure can be learned: Consistent formatting in training data translated to reliable structured outputs (88% structure score).
LoRA enables practical deployment: The 24MB adapter size makes it feasible to share and deploy without heavy infrastructure.
Future Directions
- Retrieval-augmented generation for equipment-specific manuals
- Multi-modal input (wafer map images + sensor data)
- Expansion to additional process modules (CVD, PVD, implant, CMP)
- Integration with fab MES/FDC systems
Acknowledgments
- Baidu ERNIE for the base model
- LLaMA-Factory for the fine-tuning framework
Built with ERNIE-4.5-0.3B and LLaMA-Factory for the Baidu ERNIE AI Developer Challenge.

Log in or sign up for Devpost to join the conversation.