
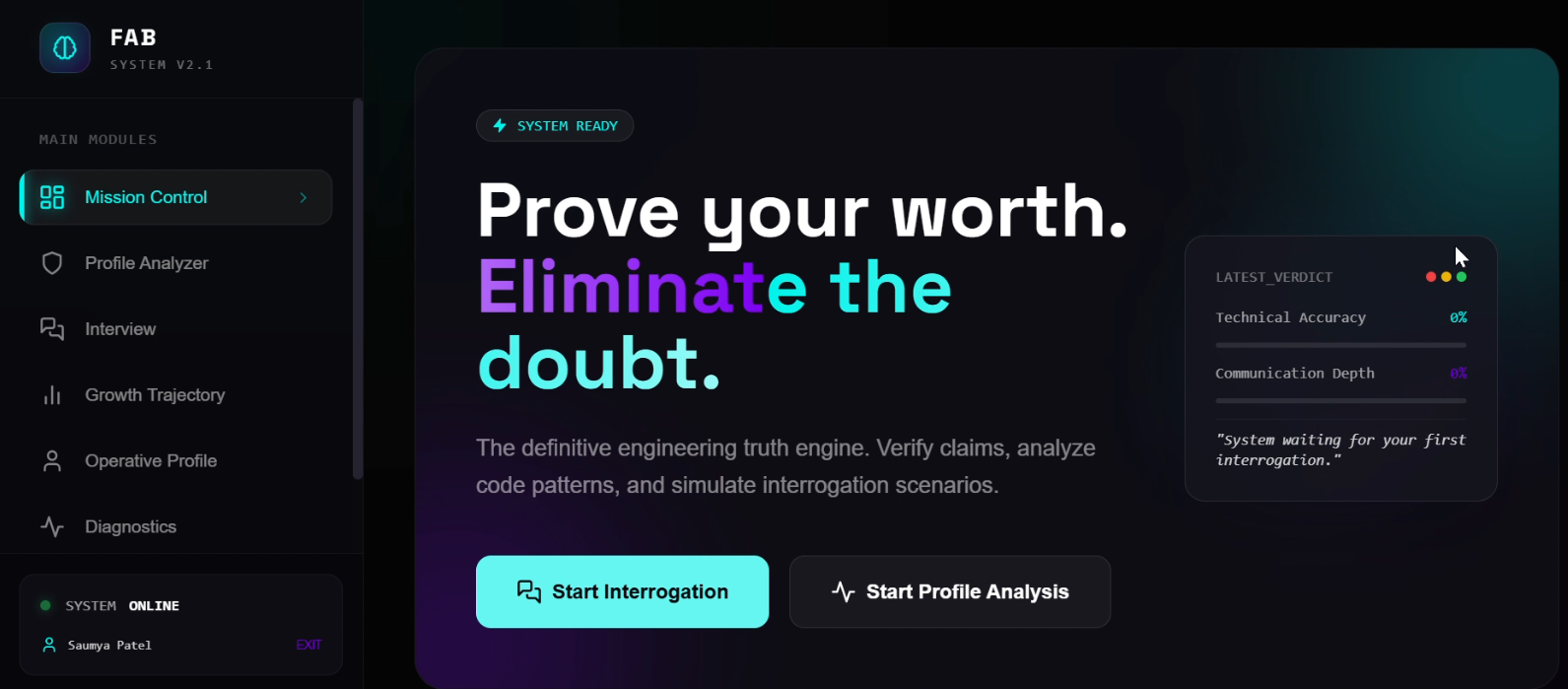
FAB (Fullstack Analysis Brain) started from two frustrations:
On the hiring side, a lot of “screening” is shallow: keyword‑matching resumes and quick calls that do not actually test how someone designs, debugs, or reasons under pressure.
On the candidate side, especially students and self‑taught developers, there is no honest mirror: your resume can say anything, your GitHub can be noisy, and interviews often feel like a lottery instead of a structured, skills‑based assessment.
The mission of FAB is to turn that chaos into a reality engine: automate deep technical vetting by cross‑referencing a candidate’s digital footprint (GitHub, resume) with a dynamic, high‑pressure interview, and then return a readiness score plus a concrete roadmap to improve.
How I built it At a high level, FAB is a full‑stack system with:
Backend: Express.js (TypeScript) as a stateless orchestrator
Frontend: React + Vite + Tailwind CSS for a dense, interactive UI
Data: SQLite as the single source of truth for users, skills, projects, and interview history
AI “Brains”: A dual‑brain layer that can run either:
locally via Ollama (Gemma/Llama), or
remotely on Colab/Kaggle GPUs through a FastAPI microservice and ngrok tunnels
The backend is organized into clear domains:
analyzer/ – a unified progressive analysis pipeline that:
Scans GitHub history and languages
Parses the resume for explicit claims
Cross‑verifies claims against commit history and file‑level code
Produces a preliminary readiness score and verified skill map
assessment/ – secondary analyzers:
ultra-deep-analyzer.ts for file‑level code review of “best” projects
resume-gap-analyzer.ts to compute the difference between target stack and actual skills
project-comparator.ts to compare candidate repos against industry reference projects
career-trajectory-analyzer.ts for long‑term growth tracking
interview/ – The Interrogator (Live Lab):
session.ts manages state, TTL, and recovery
ai-questioner.ts constructs prompts and personas like “The Architect” or “The Brutal EM” and drives a 12‑minute interrogation loop
llm/ – the polymorphic Brain Factory:
factory.ts chooses between RemoteProvider and OllamaProvider with self‑healing fallbacks
On the frontend, React pages like Home, Profile, InterviewLive, Growth, and Settings consume a typed AppService client. Visual components such as VibePulseMeter and InterviewQuestionCard handle the “feel” of pressure and feedback (animated meters, typewriter questions, etc.), while the Growth page renders readiness over time and recommended “Gap Crusher” projects.
Scoring is explicit and math‑driven. A simplified example from the analyzer:
Score=0.4⋅CodeQuality+0.3⋅LogicComplexity+0.3⋅Consistency and the overall readiness score aggregates multiple dimensions (technical depth, portfolio quality, accuracy of claims, communication clarity, growth).
What I learned Building FAB forced a shift from “just make it work” to staff‑level engineering thinking:
System design: How to coordinate a 6‑phase pipeline (ingest → verify → interrogate → analyze → coach → track) without blocking the user, using progressive disclosure and background processing.
AI as a subsystem, not a magic box: Wrapped LLMs behind strict factories, JSON extractors, and schema validators so that “chatty” model output does not break the system.
Truth vs. aesthetics: Designed a “Truth Engine” that cross‑checks resume claims against GitHub, while also building a UI that feels premium (glassmorphism, charts, pulse meters) so the harsh feedback is still approachable.
Dual‑brain operations: Handling the realities of Colab GPUs (latency, timeouts, tunnels dying) and making the app automatically fall back to local models without the user feeling the complexity.
Operational thinking: Logging, rate limits, SQLite locking behavior, and the importance of small but critical utilities (like extractJSON) in making the whole AI pipeline reliable.
Challenges I faced
- Reconciling messy real‑world data
GitHub histories are noisy: forks, tutorials, abandoned repos.
Resumes are inconsistent: buzzwords, vague bullet points, copy‑pasted job descriptions.
Designing the progressive analysis pipeline meant carefully prioritizing high‑signal repos, using fuzzy matching between resume skills and code artifacts, and defining evidence strengths like STRONG, MODERATE, NONE rather than a simple yes/no.
- Making “Brutal Mode” safe and useful
The interview engine is explicitly harsh: it escalates difficulty, calls out weak answers, and probes trade‑offs. The challenge was to keep it constructive:
Every critique must come with an actionable suggestion.
The persona must be consistent across turns.
The feedback schema (score, vibe, comment, nextQuestion) has to stay machine‑readable while still feeling human.
- Latency, fallbacks, and resilience
Remote GPUs can stall for up to 2 minutes; GitHub APIs can throttle; LLMs can return invalid JSON. FAB had to:
Set hard timeouts and always have a fallback (cached data, local brain, partial report).
Recover interview sessions after page refreshes without losing context.
Protect the user experience with a clear status/progress model rather than a single giant “Please wait” spinner.
- Security and data hygiene
Handling resumes and GitHub tokens required:
Keeping PATs out of the database and logs.
Redacting PII from resume text before sending it to any remote brain.
Implementing log rotation, token redaction, and a strict .env culture so that the system is safe to run on real candidate data.
Built With
- a
- and
- and-interview-history-ai-?brains?:-a-dual?brain-layer-that-can-run-either:-locally-via-ollama-(gemma/llama)
- backend:-express.js-(typescript)-as-a-stateless-orchestrator-frontend:-react-+-vite-+-tailwind-css-for-a-dense
- colab/kaggle
- fastapi
- gpus
- interactive-ui-data:-sqlite-as-the-single-source-of-truth-for-users
- microservice
- ngrok
- on
- or
- projects
- remotely
- skills
- through
Log in or sign up for Devpost to join the conversation.