-
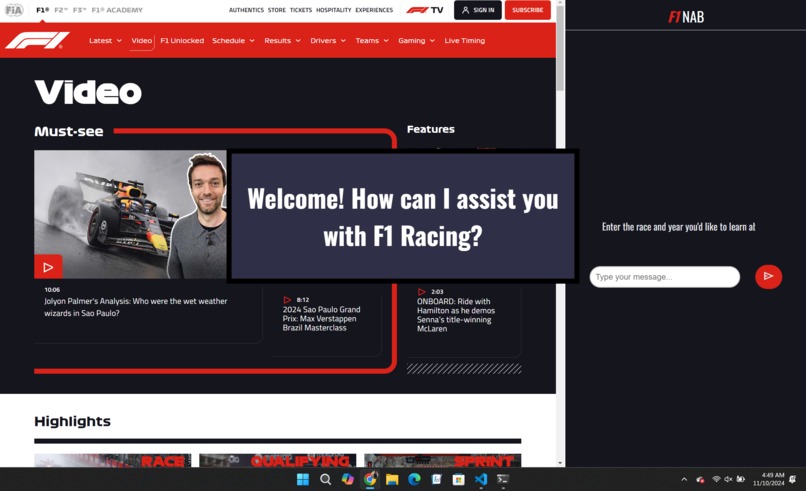
Our awesome Frontend!
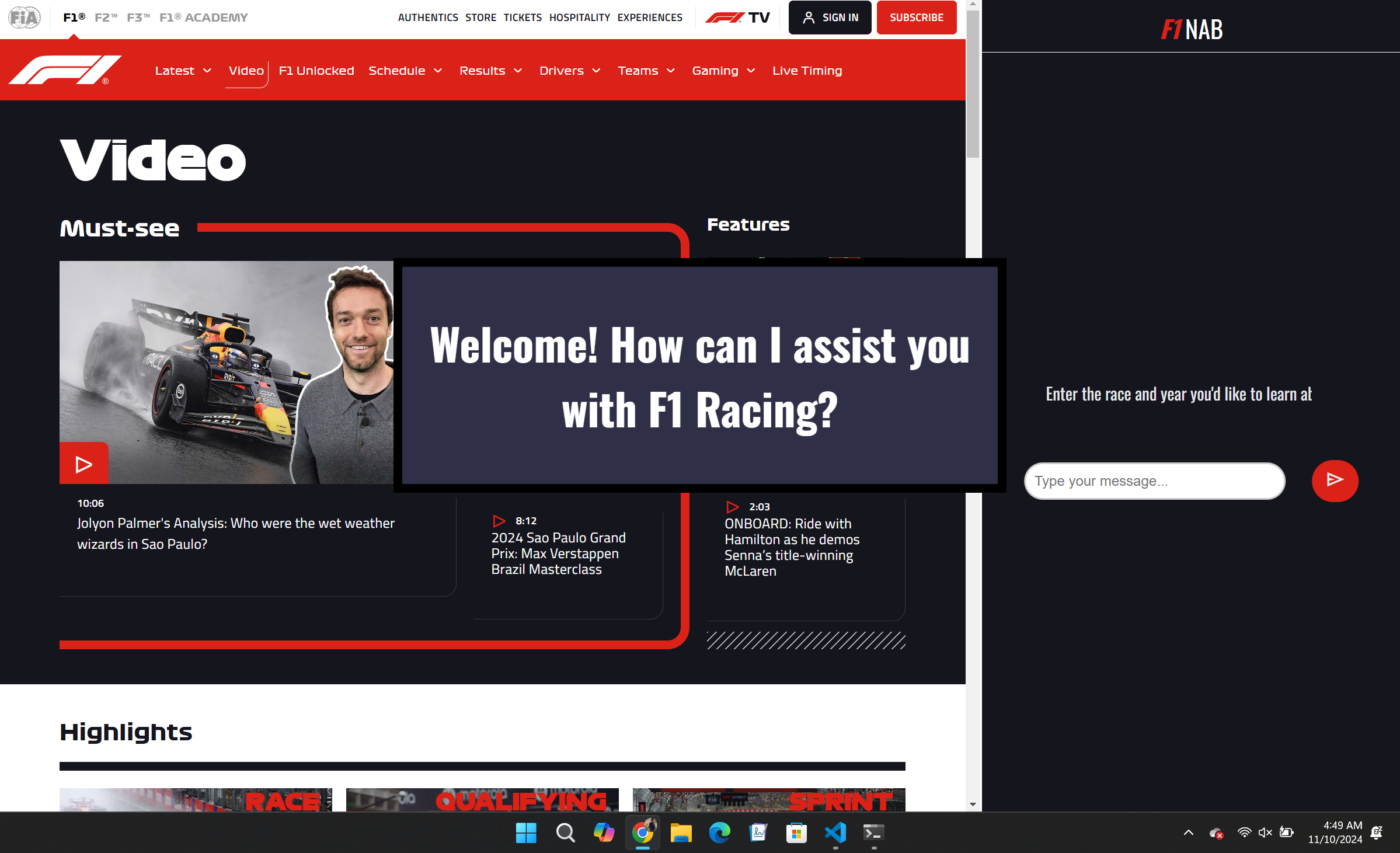
Inspiration
I was inspired to create this F1 chatbot because, as an enthusiastic fan, I know how tough it can be for newcomers to understand the sport. My friends didn’t watch the sport when I started watching it, and Google was barely any help, so I often felt lost with F1 terminology, strategies, and split-second decisions and I know how bad that feels. Hence I aimed to design this tool to guide new fans and make sure they don’t have to struggle like I did.
What it does
The F1 chatbot answers race-specific questions by providing real-time insights into race events, driver performance, and strategies. It helps users understand terminology, strategy calls, and unique race moments, making the complexities of F1 accessible and engaging for new fans. With each question, it pulls relevant data from the races to offer precise, context-aware answers, enhancing the fan experience.
How we built it
For the front end, we designed an interface where users can watch an F1 race and chat with the bot simultaneously. To keep this experience seamless, we embedded the Formula 1 racing website into our web app. This required a Chrome extension to enable embedding, which we integrated with React. The setup process involved toggling Developer Mode in Chrome’s extensions tab, selecting "Load Unpacked," and choosing the build folder in our React app. Using JavaScript, HTML, CSS, and React, we built an accessible user interface that allows users to ask questions without leaving the race screen.
On the backend, we implemented a Retrieval-Augmented Generation (RAG) approach to pair accurate race data with user questions. Using Ergast API, we collected F1 data such as lap times, driver stats, and race details, storing it in a SQL database. This data was then embedded with vector embeddings and uploaded to Pinecone, enabling efficient retrieval by context. The chatbot fetches relevant race information from Pinecone based on user input and sends this combined context to the OpenAI API, producing precise, informed responses. We also maintain a session-based chat history with a first-in, first-out system to enhance answer continuity. This approach makes the chatbot a comprehensive guide for new fans to learn about F1 in real-time while they watch.
Challenges we ran into
On the frontend, we initially experimented with Django but found React to be a better fit, which required learning both frameworks from scratch. This switch came with a steep learning curve, especially with React's component-based structure, which presented additional challenges in managing state and positioning elements correctly. One major struggle was positioning the text boxes after user input—these would often overlap or appear in the wrong locations, disrupting the user experience. Embedding the Formula 1 website added even more complexity, as the site restricted direct embedding. To work around this, we had to find and integrate a Chrome extension into React, navigate Developer Mode setup, and troubleshoot compatibility issues to allow live race viewing alongside the chatbot.
On the backend, data acquisition and processing presented multiple issues. Initially, our attempts at web scraping were hindered by site limitations, inconsistent data formatting, and gaps in the data, making it difficult to convert and use effectively. Realizing this approach wouldn’t provide reliable results, we tracked down the Ergast API, which offered more structured F1 data. However, even with this API, we encountered limitations like rate limiting, which led to bottlenecks, requiring careful request management to maintain steady data flow. Additionally, the API data needed reformatting to match our requirements, and handling large data volumes for vector embedding presented storage and retrieval challenges with Pinecone.
To overcome these backend hurdles, we implemented timed request handling to prevent API overload and selected a more efficient embedding model to handle size constraints and vector dimension mismatches in Pinecone. We also established a system to track embedded entries, avoiding duplicate processing and conserving API calls and storage. These steps allowed us to streamline the backend, enabling smooth, efficient data retrieval that enhanced the chatbot’s ability to deliver accurate, real-time responses.
Accomplishments that we're proud of
On the frontend, we’re proud to have learned both React and Django, gaining a deeper understanding of web development beyond school projects. This project strengthened our JavaScript skills, especially within the context of a real-world application, and we successfully debugged and resolved challenging issues, from UI positioning to embedding the F1 website seamlessly into our app.
On the backend, we’re incredibly proud of building a sophisticated Retrieval-Augmented Generation (RAG) pipeline from the ground up. This project required us to master the entire data lifecycle—acquiring, processing, and embedding extensive F1 data, then integrating it into Pinecone for fast, context-driven retrieval. We successfully optimized the pipeline to handle large data volumes, overcame challenges with rate limits and vector embedding, and created an efficient system that feeds high-quality, race-specific context into OpenAI for precise responses. Developing this pipeline was a major accomplishment, pushing our skills in data management, optimization, and advanced retrieval techniques.
What we learned
This project taught us a lot about both frontend and backend development. On the frontend, we learned how to work with React and Django, manage state, and troubleshoot UI challenges. Embedding an external site within our app pushed us to think creatively, and we improved our JavaScript skills by applying them to a practical, interactive project.
On the backend, we learned how to build a system that combines user questions with relevant data. We figured out how to collect and store large amounts of F1 data, use Pinecone to quickly retrieve it, and send it to OpenAI to give helpful answers. We also dealt with API limits and learned to manage data to keep the system fast and efficient. Overall, this experience taught us how to design and optimize systems that make complex information more accessible.
What's next for F1NAB
We plan to enhance F1NAB by expanding its database with more historical and detailed race data, including sector times, weather conditions, and team strategies. Additionally, we aim to refine the chatbot’s ability to handle more complex questions, giving even deeper insights into race dynamics. We’d also like to add multilingual support, making F1NAB accessible to fans worldwide. Finally, we’re exploring the potential for real-time integration, allowing F1NAB to provide live insights and answer questions during ongoing races for an even more interactive fan experience.





Log in or sign up for Devpost to join the conversation.