-

Homepage
-
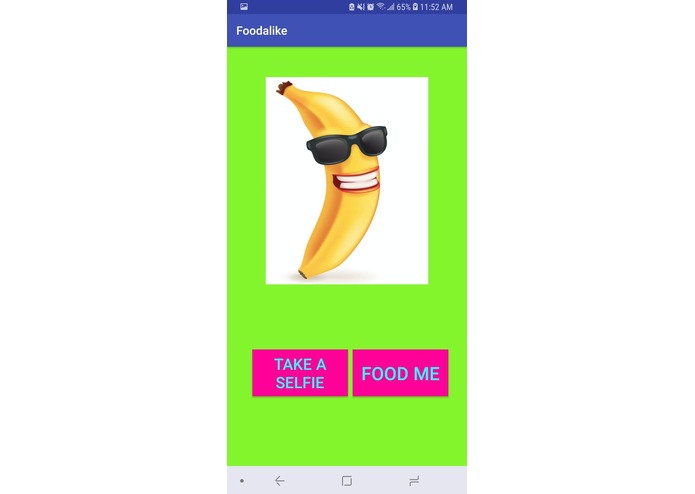
after clicking on "Send a pic"
-
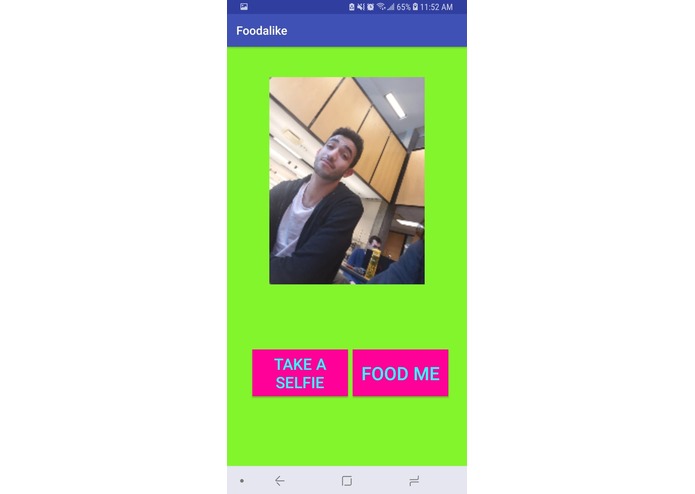
after taking a selfie

Inspiration
We were inspired by the plethora of tag yourself memes you often see all abound on your facebook or instagram timeline, as well as the current resurgence of astrology and the very derivative yet specific comparisons. We wanted to run something that had a more traditional backend, with skills transferrable to other, more serious settings, but with a lighthearted design and direction to reflect our personalities and interests.
What it does
Our foodalike app is based on a model trained on 24 categories of food, taken from http://www.vision.ee.ethz.ch/datasets_extra/food-101/ . Each category has 1000 pictures, with 250 hand-picked test images as well as uncleaned training images with varying amounts of noise. The android app, when opened, takes a selfie and sends it to the model, which then tells us what kind of food you ressemble the most, along with a list of descriptions.
How we built it
The pictures were preprocessed with numpy libraries, by resizing all of the pictures to 50x50 and converted to arrays of pixel values The pictures were then run through a 2 layer convolutional neural network for 10 epochs, returning a model with about 65-70% accuracy. We then put up the trained model on heroku through a flask framework. From there, we coded a barebones android frontend with a camera activity that asks for the user to take a selfie, which is then sent out to the model through (an http call) to heroku. The model then returns a json with the confidence values, and the highest one determines the "foodalike", with a corresponding example picture and some descriptions.
Challenges we ran into*
*are still running into
Initially, we wanted to use the Watson Visual Recognition service along with boilerplate Android code.
However, we shyed away from Watson because it was more of a plug-and-play type of library, and we wanted this project to be more of a learning experience. After running the network locally, we found out that we were limited by our machine to only 2 layers, only reaching 65% confidence values by the end of the 10th epoch. We tried running everything on aws, but our ssh connection kept timing out after a successful initial link. As such, we decided to keep our weaker model and host it on heroku through flask.
On the frontend side, we ran into multiple issues with the boilerplate synchronization with github and intellij/android studio, so we then decided to start from scratch off of the android jetpack collection, but then we had issues with android studio 3.2.1, so we went back to an older version and kept the structure to multiple, simple activities. From there, while we got the app up and running, we struggled to establish a proper connection to the backend and how to preprocess the image captured before sending through http.
Accomplishments that we're proud of
As a team that came in with no prior ideas or experience in machine learning and very little knowledge about android, we're very proud of how far we've come. Most of our time was spent doing research and learning about the technologies employed rather than actually employing them, so it was nice to have been able to establish a cnn that was functional, even if it was more of proof of concept than anything else.
What we learned
We learned tremendously across the board, particularly so because we went in blind. As mentioned before, we got to play around a lot with multiple libraries and frameworks and tools currently at the forefront of the technology, even if not all of them made it into the final product, for reasons x or y. Amongst those technolgies are pytorch, docker, colab, aws, android jetback and others.
What's next for f o o d a l i k e
We're having our first round of seed funding in March actually. Please keep in touch!
Jokes aside, options that would have been fun or interesting to implement had we had more time would include, barring obvious options such as a deeper neural network on a more powerful cloud service, gimmicks such as a second cnn trained on faces to generate a composition of the food and of the selfie in one frame or a facebook Oauth connection that would take in tagged photos and spit out a result based on those. On a more serious note, we could also have processed the selfie fed in by flipping, translating, cropping or rotating it to control for background noise. One of the biggest faults in our system, partially by design, is the lack of relation between the training/test sets used for the model and the actual inputs fed in. The intent behind the application was to draw attention to the very narrow use cases of AI and to use the technology with caution and good judgement. Just because a specific application might have worked really well, does not mean that it could be generalized, even by a bit, so it's important to keep the utilization well contextualized and framed within a bigger picture.
Built With
- amazon-web-services
- android-studio
- flask
- heroku
- java
- keras
- kotlin
- machine-learning
- numpy
- tensorflow






Log in or sign up for Devpost to join the conversation.