-

Ez Pz
-
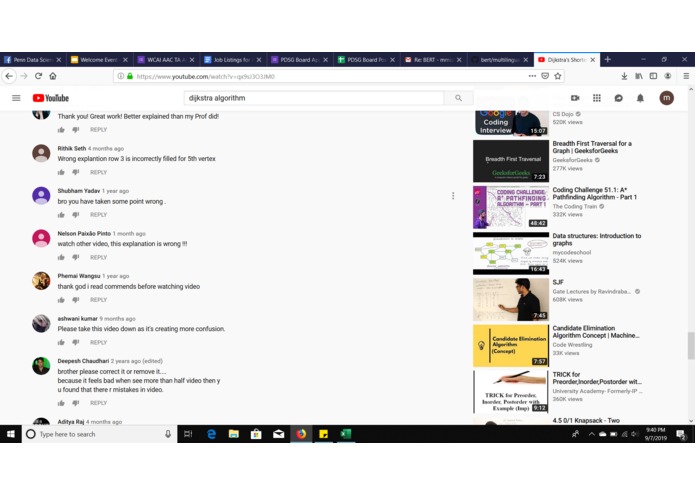
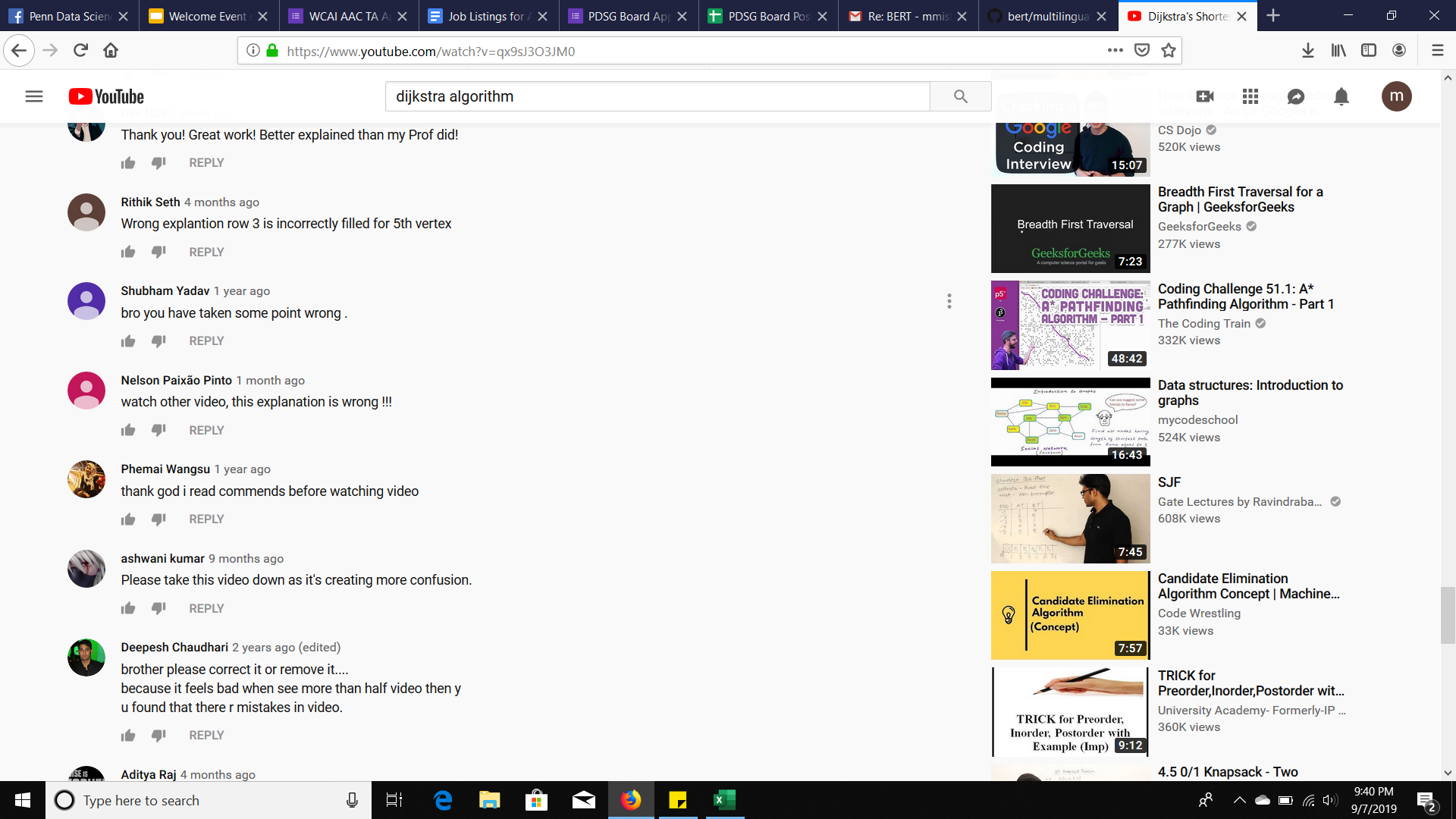
Comment saying "Thank god I read other comments before watching" --Inspiration behind this project
-
BERT Model Running as a Server
-

Django Server Running

Inspiration
My dad wanted to learn machine learning. He is a Engineer with over thirty years of experience and he came to me for help. We all know the best place to learn is Youtube, however not all videos on Youtube can be suitable for beginners. Also, there are a plethora of videos which incorrectly explain fundamental concepts and algorithms. In order to weed out the bad videos from the good ones, views and likes are not the only metric, and I turned to reading the comment section before recommending the video to my father. By going through the comments I could find out about the quality of the video from other users on the Youtube platform without having to go through the entire video myself. Not to mention how many times I myself have turned to Youtube the night before an exam to learn some concepts. Being able to quickly draw inferences about the video from the content of comments was the inspiration behind this hack.
What it does
Upon making a keyword search for a Youtube video on the webpage, the application scrapes data for the top videos and the comment section as well. Using natural language processing, we are able to rank the videos based on what people wrote in the comments section. Our algorithm ensures that videos of higher scores were understood by more people, had concepts explained correctly, and were popular on the platform.
How we built it
The applications involves the usage of Django Framework, Youtube API, Bert-Embeddings, and Spacy. The Django Framework is used to enter the search terms while the Youtube API is used to get Youtube data for processing. We used Bert models to figure out which comments were associated with the user being able to understand/not understand the concept and developed a scoring system. By scoring a video based on the nature of the comments, likes, dislikes, and views, we created a rank list which is in the order of easiest comprehension, correctness of conceptual knowledge, and production value.
Challenges we ran into
1) Scraping data from Youtube involves the use of of Youtube API which has a max limit of 10,000 requests per day. 2) Deciding on a clustering approach 3) Dealing with comments from different languages 4) Encoding issues
Accomplishments that we're proud of
1) Implementation of Bert encodings 2) Adding another dimension to search algorithms on Youtube that may prove beneficial to students
What we learned
1) Usage of Youtube API 2) Bert Encodings 3) Intensive Pandas Dataframe operations
What's next for Ez Pz
1) Add spam comment detection 2) Add multi language support 3) Integrate onto a website/webapp
Log in or sign up for Devpost to join the conversation.