-
-

Welcome to EyeText!
-

Talk or Help Interface
-
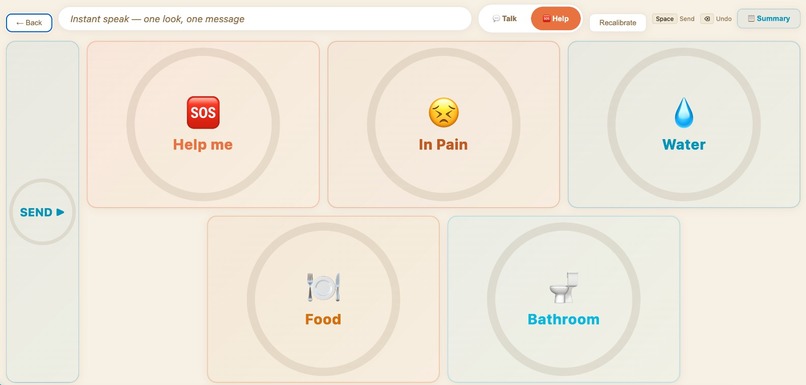
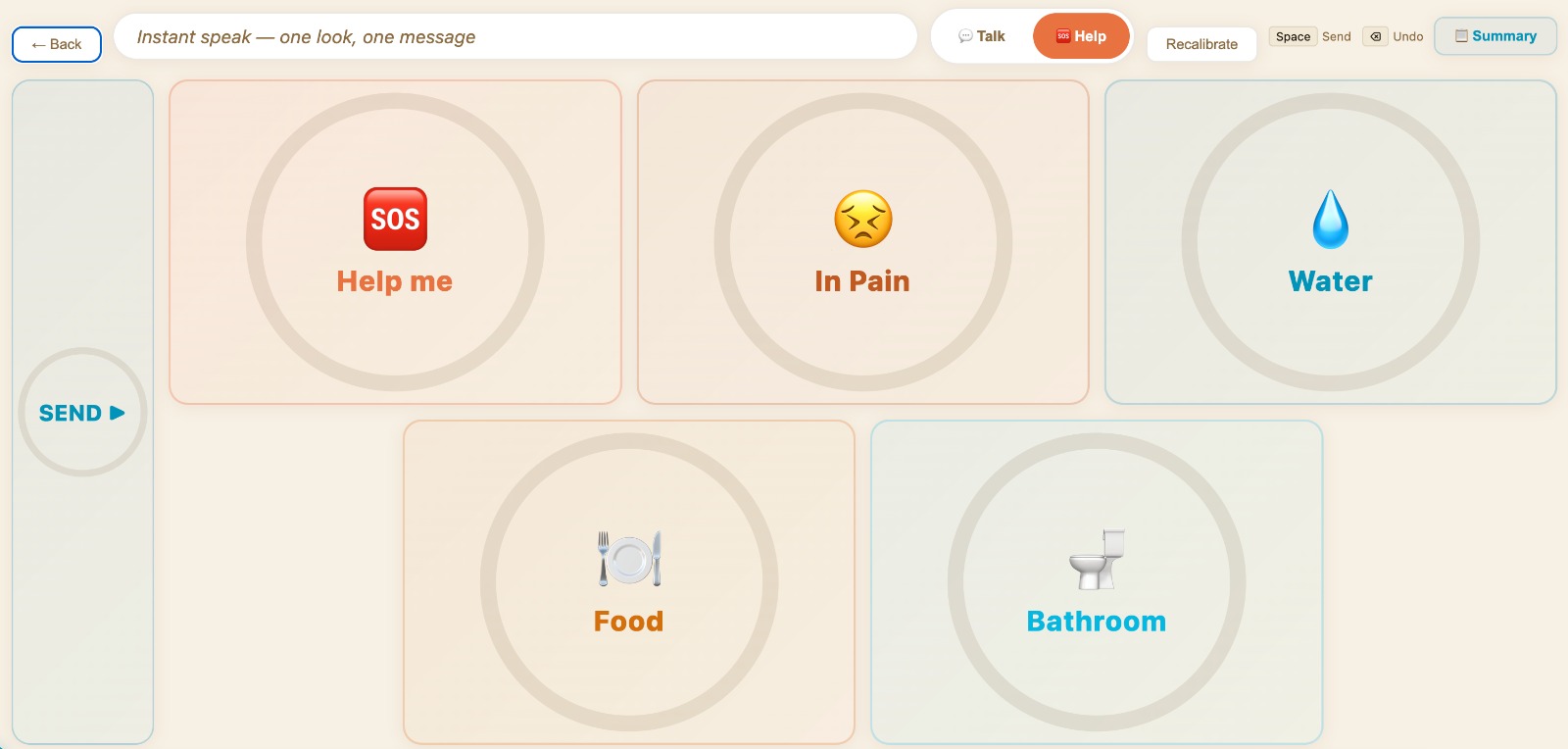
Options for Help
-
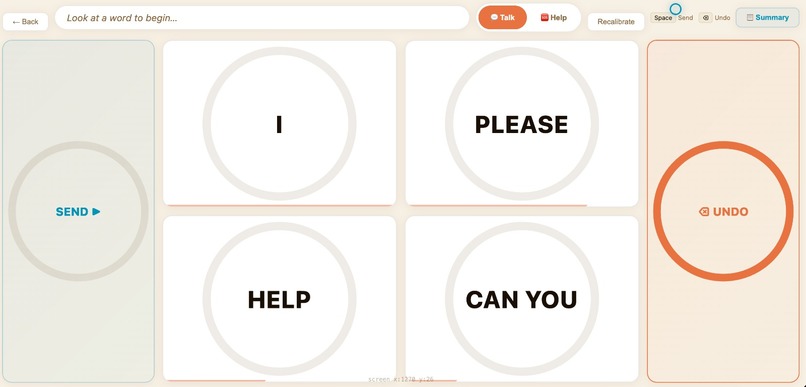
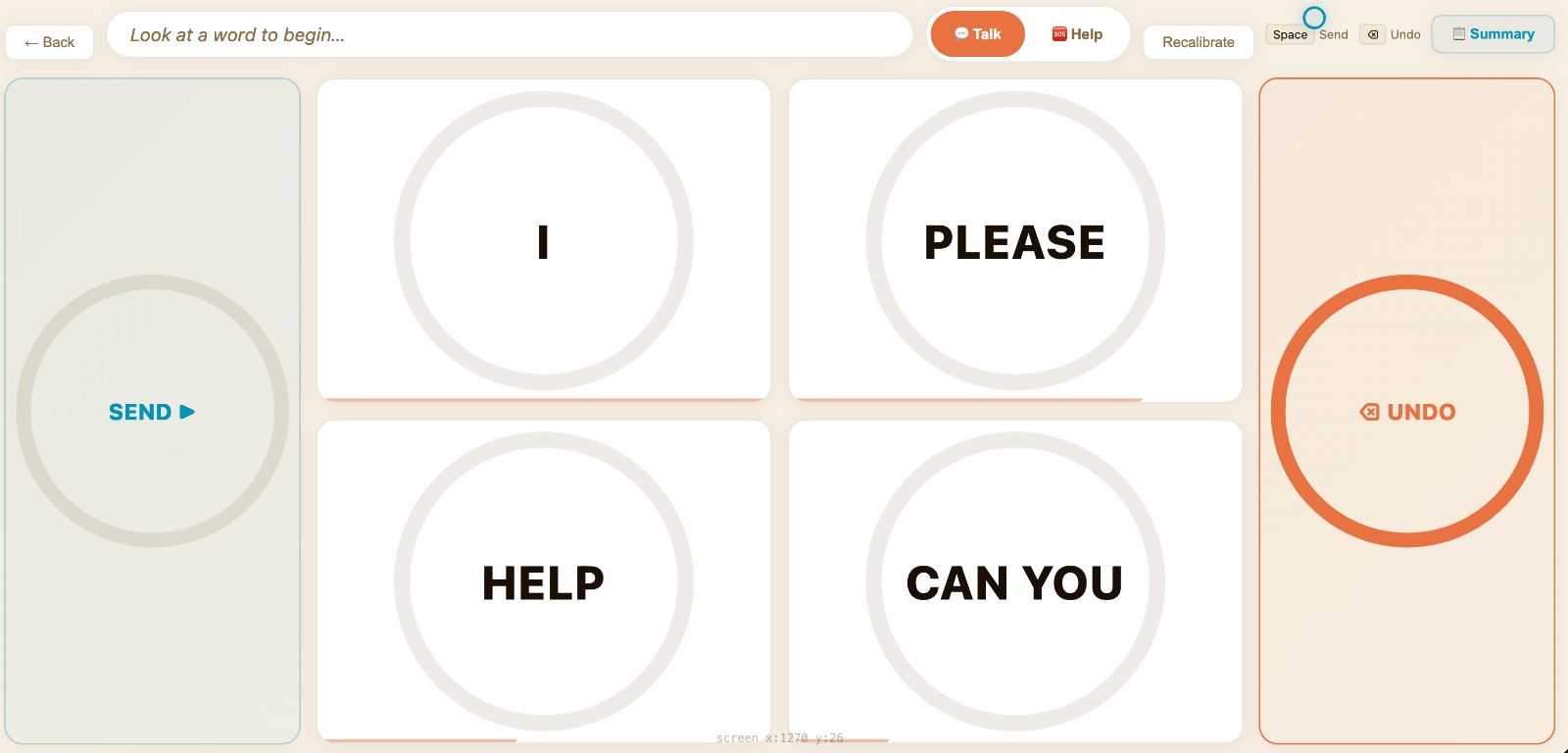
Options for Talk


Inspiration
Cerebral palsy made us ask a simple question. How do people communicate when speaking is difficult or not possible? We also thought about patients with speech impairments and physical limitations and how they express urgency, comfort or pain in daily life.
We thought about our grandparents too, especially when typing a single sentence can take several minutes.
That led us to a bigger idea. What if communication did not depend on hands at all? What if we could write with our eyes and turn gaze into language that brings thoughts to life instantly for friends, family and caregivers?
What it does
EyeText is a way to talk through your eyes.
Users select words, phrases or intent tiles just by looking at them. The system predicts what they are trying to say before they even finish forming the thought.
There are two main modes. Talk Mode allows natural conversation with friends and family. Help Mode is designed for urgent needs like water, food, medicine or assistance.
Behind the scenes, the system uses predictive tiles and next word models, an Agentverse multi agent backend for intent understanding and routing, Cloudinary powered communication cards and session media, and video and behavior analysis for context awareness.
It is not just gaze typing. It is intent becoming language.
How we built it
EyeText is built as a full-stack gaze-driven communication system that turns eye movement into natural language through a real time pipeline of vision, agents and media generation.
At the core, the frontend is a browser based gaze engine built in TypeScript. It uses WebGazer to track eye movement through a standard webcam, applies calibration through a 7-dot setup and converts dwell time into tile selections. This allows users to build sentences simply by looking at words or phrases on screen.
The backend is a multi-service system that connects AI agents, cloud media processing and persistent memory. Every gaze interaction flows into an Agentverse powered multi-agent pipeline that interprets intent, understands context, retrieves user memory, detects emotional state, generates responses and routes communication back to the user.
We use Fetch.ai Agentverse to orchestrate this system. Each uAgent has a specialized role in the communication pipeline, and together they transform raw gaze input into structured intent and finally into natural language responses. The Agentverse infrastructure allows these agents to be discoverable and modular, enabling a scalable architecture where each reasoning step is handled independently.
Relevant Links for Fetch.ai:
ASI:ONE Chats -
Ideating all the agents: https://asi1.ai/shared-chat/a46dc48b-820e-4153-8af9-e4f9527b295b
Testing communication-router-agent: https://asi1.ai/shared-chat/41601302-d27d-4184-af71-05445fb51be9
Agentverse Agents -
user-context-agent: https://agentverse.ai/agents/details/agent1qtqrmd7du8kha6xc9l42uwr4clq35slmq633zqvdxa5exgqgnhgjksp5xs4/profile
output-generation-agent: https://agentverse.ai/agents/details/agent1q2akqd8p697zw4y92gp03w47m2824guaj6rqk4h875vz9q3pyad8xnle46n/profile
communication-router-agent: https://agentverse.ai/agents/details/agent1qdjesxt4sxndwgjk3gzemtm02f9lzm85wyhj2ct3jalmq2utrn887najgdd/profile
gaze-intent-agent: https://agentverse.ai/agents/details/agent1qty3naahpus39hcfffhl0dtznrntjc2yp304m693tcva3krwfwkfvn3mx95/profile
We use Cloudinary as our media and communication layer. Every session is recorded through the browser using MediaRecorder and uploaded to Cloudinary. From there, we dynamically extract frames and generate communication assets such as session cards and visual summaries. Cloudinary also powers the storage and transformation of session media, enabling real time visual feedback and post-session analysis.
We use Gemini to generate multimodal session summaries. After each interaction session, Cloudinary extracted frames and transcript data are sent to Gemini, which produces a structured clinical summary including emotional context, key interactions and communication patterns. This is shown to caregivers to help them better understand patient needs over time.
We use MongoDB Atlas as the memory layer of the system. It stores user phrases, session history and generated summaries. Atlas Search enables semantic retrieval of past patient vocabulary, allowing the system to personalize predictions and improve communication accuracy over time.
We also use WebGazer for real time gaze tracking directly in the browser. This removes the need for specialized hardware and makes EyeText deployable on any device with a webcam.
Figma Make
Figma Make became our “speed layer” during EyeText’s earliest decisions. Before we committed to implementation, we used Make to rapidly prototype a gaze-first interface and test whether the interaction felt understandable at a glance for users who may not be able to rely on hands or speech.
We built a quick predictive text mockup in Make with dwell-based selection timing, a large high-contrast tile grid, and a live composition area.
https://icon-said-33772519.figma.site/
That prototype helped us answer key questions fast:
Is the information hierarchy clear in under a second? Are the hit targets visually confidence-inspiring for gaze interaction? Does a predictive board feel assistive or overwhelming? Because it was so fast to iterate in Make, we were able to throw out weaker layouts early, tighten spacing and copy, and align the team on a shared interaction model before writing heavy logic. This saved us hours of engineering churn and gave us a concrete artifact to pitch internally while we were still shaping the product direction.
Most importantly, Figma Make helped us think in interaction loops, not static screens: from experimenting through gaze → prediction → selection → message. The final EyeText experience evolved beyond the initial mockup, but Make was the tool that helped us get to the right starting point quickly and confidently.
Together, these components form a loop where eye movement becomes intent, intent becomes reasoning through agents, reasoning becomes language and language becomes action delivered to caregivers or family members.
Challenges we ran into
We spent a lot of time staring at screens trying to make eye tracking feel natural instead of frustrating. It was surprisingly hard to make eyes feel like a reliable input method.
We also had to coordinate webcams, prediction models and backend agents so everything worked in sync without noticeable lag.
We realized that in accessibility tools even a small delay of 200 milliseconds can completely change the user experience.
Debugging gaze tracking also felt like arguing with physics because small movements change everything.
Accomplishments that we are proud of
We built a predictive tile system that actually feels usable in practice.
Users can look at a phrase, see the system predict intent and instantly trigger a response.
The system does not just output text. It behaves like an assistant that understands context and responds appropriately.
It can also trigger immediate help requests when needed, which makes it feel practical for real world use.
Overall, it feels less like a user interface and more like a conversation.
What we learned
We learned that eye tracking is surprisingly emotional because it changes how you think about basic interaction.
We also learned how much people rely on their hands without realizing it.
Building communication systems is much harder than building fast systems because meaning matters more than speed.
We found that forming full sentences from gaze patterns is both chaotic and fascinating.
We also learned that people can express a lot without moving at all.
What is next for EyeText - Your eyes are the new keyboard
Next, we want to build a pain mapping mode where users can look at parts of a body diagram to indicate pain locations for doctors.
We also want to integrate food and delivery services like Uber Eats and DoorDash so that Help Mode can directly place requests.
We plan to add multi person conversation support so users can communicate with multiple people naturally through gaze based routing.
We also want to improve emotional understanding so the system can detect urgency, discomfort and hesitation beyond just words.
EyeText starts with communication, but it moves toward something bigger.
It moves toward expression without limitation.
Built With
- agentverse
- api
- cloudinary
- express.js
- fastapi
- fetch.ai
- gemini
- mediarecorder
- mongodb
- node.js
- python
- react
- typescript
- webgazer






Log in or sign up for Devpost to join the conversation.