-

Main page
-

Recording surrounding 1...
-

Recording surrounding 2...



Inspiration
We wanted to do something that is actually valuable for society so we decided to apply computer science to help blind people's life as much as possible. The idea came when one of the team members saw a blind person in the underground (we are from Barcelona) that hit the recycle bin, he thought about how difficult has to be to walk with a surrounding full of obstacle without seeing.
What it does
EyeTales tries to solve this issue by capturing images of the surroundings and describing them with audio to the user. The application captures images from the camera and converts them in base64. Those images are sent to the backend API which generates a text and transforms it into speech. After that, the raw audio is sent back to be reproduced.
The text is generated based on two parts: the main one is based on the object detection results we get, we take them and we build the sentences based on that; the other one uses an end-to-end system based on deep learning that takes the image and outputs the text.
How we built it
Frontend and backend are very different components connected by API requests and deployed with Docker compose.
The website was built using Plain JavaScript with the help of jQuery. The backend is done in Python using Flask. The Text2Speech part uses the Google Cloud Speech-To-Text API and the Computer Vision part is build upon two main components: the object detection Transloadit API and a Show, Attend and Tell model (neural image captioning model) that was build using Tensorflow 2.0 and trained on a subset of the MS-COCO dataset in Google Colab.
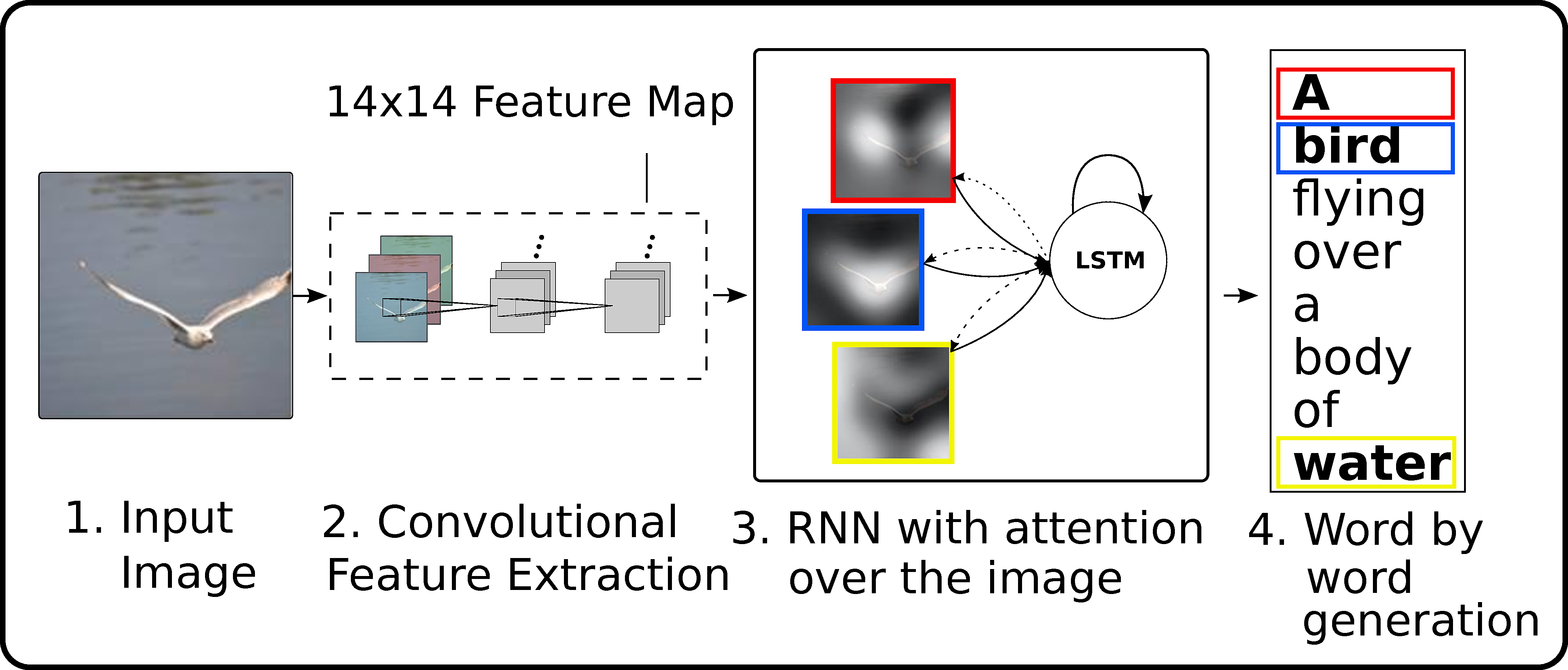
Neural Image Captioning Model
Basically the model extracts feature using an InceptionV3 from Keras applications model zoo with the ImageNet weights (by taking the last layer features), passes them through a CNN encoder and a Recurrent NN decoder that generates the output text.
Backend API
We have the backend which is implemented with Python 3.7. For creating the API that allows the communication between the two components, we have used Flask and OpenAPI (connected themselves with Connexion library), integrated with Docker compose. This API is hosted using uWSGI and Nginx in a small Google Cloud engine with 8 CPUs and 32GB of Memory RAM.
Challenges we ran into
Google Cloud Platform did not deliver us GPU instances so we had to train with Google Colab (which can be painful and stressful some times). At the beginning I could not get webcam access and when I managed to get access during the conversion to base64 it was converting a white screen.
Accomplishments that we're proud of
IT WORKS :D!! We get an image from the camera, process the image and get audio that makes sense :D.
Also, despite all the problems we have had, we have been able to train the model and make it work.
What we learned
It was the first hackathon for one of the team members, he learned git and he was in charge of the website but he had no idea, so he had to learn JavaScript, HTML, and CSS. Moreover, we have learned about how Image Captioning based on Deep Learning works (really cool stuff tho) and how to deal with the audio management on JavaScript.
What's next for EyeTales
We could use another object detection model like MobileNet or TinyYOLO to improve the results output and add more rich and real sentences in the script that generates text.







Log in or sign up for Devpost to join the conversation.