-
Final Project Poster
Title: Extracting emotions from speech
Who: Nancy, Kaley, Keyan
Introduction:
What problem are you trying to solve and why?
We are trying to accurately depict and classify emotions in speech. This project can help with several elements.
Enhancing conversational Agents and other machine learning techniques Improving Human-Computer Interaction Addressing research gaps- Filling gaps in SER (Speech-emotional recognition) methods Healthcare applications- Identifying patient's mental health safely. Increasing our understanding of emotional recognition in humans as well
If you are implementing an existing paper, describe the paper’s objectives and why you chose this paper.
Paper Objectives: Paper: https://arxiv.org/abs/2211.08213 Exploring relationships between speaker recognition and emotion detection. Aims to understand how changes in speaker identity due to emotional expression can affect the extracted speaker embeddings and how these embeddings can be utilized for emotion recognition. Propose a novel approach to SER by leveraging Global Style Tokens (GST) in conjunction with a DeepTalk network for speaker recognition Evaluating the Performance of the Proposed Approach: performance of the proposed approach through experiments conducted on various datasets with different types of emotions (acted, semi-natural, and natural). The authors compare the performance of their approach with baseline methods and analyze the results to assess its efficacy in SER tasks.
We chose this paper because we found it very interesting how models can take something as complex as human emotions and start identifying what emotion and how real the emotion is based on functions and datasets.
If you are doing something new, detail how you arrived at this topic and what motivated you. What kind of problem is this? Classification? Regression? Structured prediction? Reinforcement Learning? Unsupervised Learning? Etc.
Although this topic isn’t new, we were very interested in the effect of sound during the start of this project after doing some research we found something that meshed a lot of our interests together: computer humans and the ever-difficult emotions.
Related Work: Are you aware of any, or is there any prior work that you drew on to do your project?
A lot of us have taken CLPS classes before and also Neuroscience. So we have some background knowledge about human interactions, the brain, and how emotions are expressed.
Please read and briefly summarize (no more than one paragraph) at least one paper/article/blog relevant to your topic beyond the paper you are re-implementing/novel idea you are researching.
Article: https://www.audeering.com/how-speaker-identification-affects-emotion-detection/
The article explores the role of speaker identification in enhancing emotion detection from speech. It emphasizes how individual voice characteristics contribute to the uniqueness of each speaker, making speaker identification a valuable component in accurately discerning emotions. Using speaker-dependent technology, emotion detection systems can tailor their responses to match the specific traits of each speaker, thereby improving accuracy. The article also discusses the importance of self-learning techniques for adapting to different speakers over time, while ensuring data privacy compliance according to GDPR and German Telemedia Law. Overall, the integration of speaker identification offers a promising avenue for optimizing emotion detection technology, enabling personalized and accurate results while safeguarding user data privacy.
In this section, also include URLs to any public implementations you find of the paper you’re trying to implement. Please keep this as a “living list”–if you stumble across a new implementation later down the line, add it to this list.
In progress.
Data: What data are you using (if any)? If you’re using a standard dataset (e.g. MNIST), you can just mention that briefly. Otherwise, say something more about where your data come from (especially if there’s anything interesting about how you will gather it).
https://www.kaggle.com/datasets/imsparsh/audio-speech-sentiment We are also using MELD : https://affective-meld.github.io/ And we are using RAVDESS: https://zenodo.org/records/1188976#.YFZuJ0j7SL8 How big is it? Will you need to do significant preprocessing?
The Kaggle data set is small so we will not have to do significant preprocessing. However Meld and Ravdess are quite large.
Methodology: What is the architecture of your model?
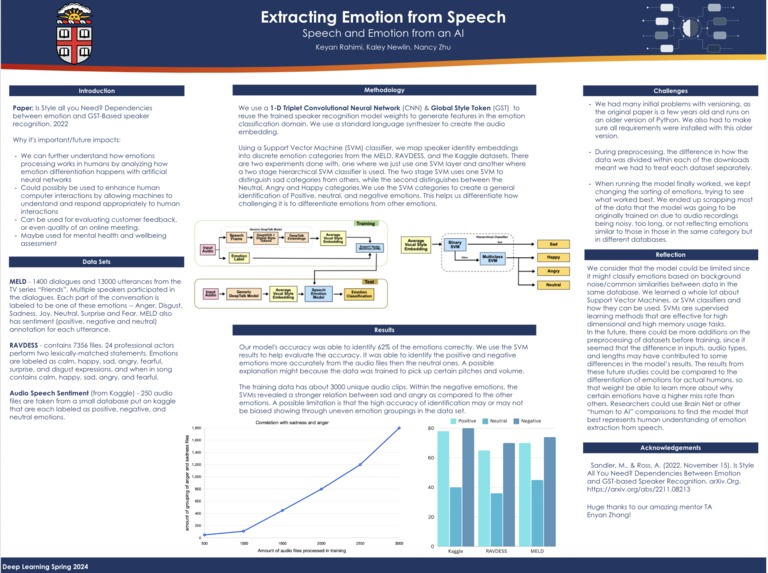
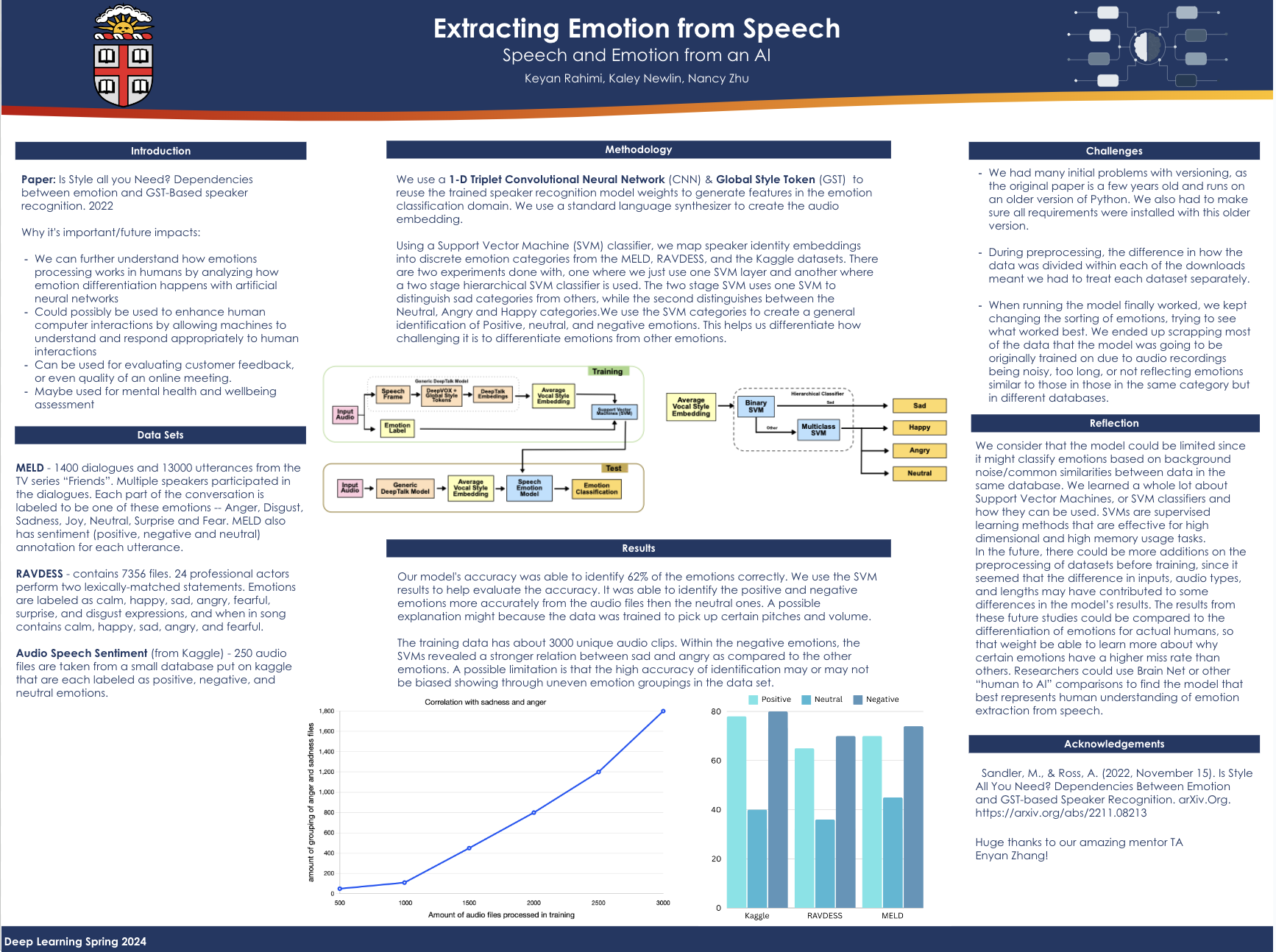
DeepVOX-It directly extracts features from raw audio data Global Style Tokens (GST): these style tokens contain emotional content and are crucial for capturing emotion-related information from the speech signal. Speaker Recognition Network: This network aims to maximize the speaker-dependent vocal style information in the embeddings. Support Vector Machines (SVM): used to map the speaker identity embeddings extracted by the DeepTalk network into discrete emotion categories Hierarchical Classifier: The hierarchical classifier consists of two SVMs in sequence: the first SVM distinguishes one emotion category (e.g., Sad) from the rest, while the second SVM distinguishes among the remaining emotion categories (e.g., Angry, Happy, Neutral).
How are you training the model?
Feeding data Feature extraction- special speech samples Training the Speaker Recognition Network-rained using a triplet-based speaker embedding learning framework. This involves presenting the model with triplets of speech samples Training the Emotion Classification Model-fine-tuned for emotion classification using the extracted speaker embeddings Model Evaluation:he trained model is evaluated on separate validation and test datasets
If you are implementing an existing paper, detail what you think will be the hardest part about implementing the model here.
Getting the model to work and having the resources to run the model so that it does not fail the accuracy test.
If you are doing something new, justify your design. Also note some backup ideas you may have to experiment with if you run into issues.
Might be implementing a lie detector? Some additional ideas may include making new permutations to when preprocessing the data to make the identifying features of emotion more apparent. Basically, disregards data from the audio that is not needed, and only feeding in the parts that are important.
Metrics: What constitutes “success?”
The model and accuracy least 65%
What experiments do you plan to run?
For most of our assignments, we have looked at the accuracy of the model. Testing how efficient it is to use different models and also the models in different order.
Does the notion of “accuracy” apply for your project, or is some other metric more appropriate?
Yes, Identifying the correct emotion from speech is very important.
If you are implementing an existing project, detail what the authors of that paper were hoping to find and how they quantified the results of their model.
The authors of the paper explored the idea that speaker identity embeddings extracted from speech samples could aid in the detection and classification of emotion. They utilized a 1-D Triplet Convolutional Neural Network (CNN) and Global Style Token (GST) scheme, such as the DeepTalk Network, to learn speaker identities and then repurpose the trained speaker recognition model weights for emotion classification. Their experiments involved training ASR networks with triplet loss functions on datasets like VoxCeleb1, VoxCeleb2, and Librispeech, and mapping the resulting speaker identity embeddings to discrete emotion categories using SVM classifiers. Then they evaluated the model's performance on three emotion datasets: CREMA-D, IEMOCAP, and MSP-Podcast, reporting accuracy metrics ranging from 66.9% to 81.2%. Additionally, they introduced a novel two-stage hierarchical classifier approach, which yielded a +2% accuracy improvement on CREMA-D emotion samples. Overall, the authors demonstrated the effectiveness of their approach in speech emotion recognition by leveraging speaker identity embeddings, providing a promising avenue for future research in this field.
If you are doing something new, explain how you will assess your model’s performance. What are your base, target, and stretch goals?
Running own voices and if they identify correctly then it's a pass! Running on the paper the same data sets and with 65% accuracy then it is a pass!
Aiming for 80+ percent accuracy and efficiency! To the paper.
*Ethics: Choose 2 of the following bullet points to discuss * not all questions will be relevant to all projects so try to pick questions where there’s interesting engagement with your project. (Remember that there’s not necessarily an ethical/unethical binary; rather, we want to encourage you to think critically about your problem setup.)
Why is Deep Learning a good approach to this problem? Deep learning models can automatically learn relevant features directly from raw speech signals, eliminating the need for handcrafted feature engineering. This is particularly advantageous in speech emotion recognition, where extracting discriminative features from speech signals can be challenging due to the complex and dynamic nature of emotional expression. Non-linearity: Deep learning models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are capable of capturing non-linear relationships in data.
Lastly, with new advances, these models will become more and more accurate and provide more information to help people in the workforce.
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain?
We are a little skeptical about the Kaggle data set. Since the dataset lacks detailed information about its origins, it's essential to exercise caution and consider the potential limitations of the data. we should conduct thorough preprocessing and validation procedures to ensure the quality and reliability of the dataset before using it for analysis or model training. It appears to be a curated collection of audio recordings labeled with sentiment categories, likely obtained from various sources such as public databases, research projects, or audio recording platforms.
Division of labor: Briefly outline who will be responsible for which part(s) of the project.
TEAM: MODEL TRAINING + MODEL EVALUATIONS Collectively plan on contributing to preprocessing data and data collection. Keyan will mainly focus on architecture, and Nancy will mainly focus on increasing accuracy, however, most parts will be collaborative and subject to change. ** WILL BE UPDATED AND CHANGED.
DL checkin update 3: https://docs.google.com/document/d/1ECb6-hWzA5PkbQb64GRjFqct1CDAf-74NLNEBDMDYCY/edit?usp=sharing
Final reflection: https://docs.google.com/document/d/1_ahSvEPhb7JRiWoROd5mwru8z4JlUJ-kTceoipErDuU/edit?usp=sharing
Built With
- python
- pytoch
- tensorflow


Log in or sign up for Devpost to join the conversation.