-
-

ExTest Logo
-
ExTest Landing Page
-
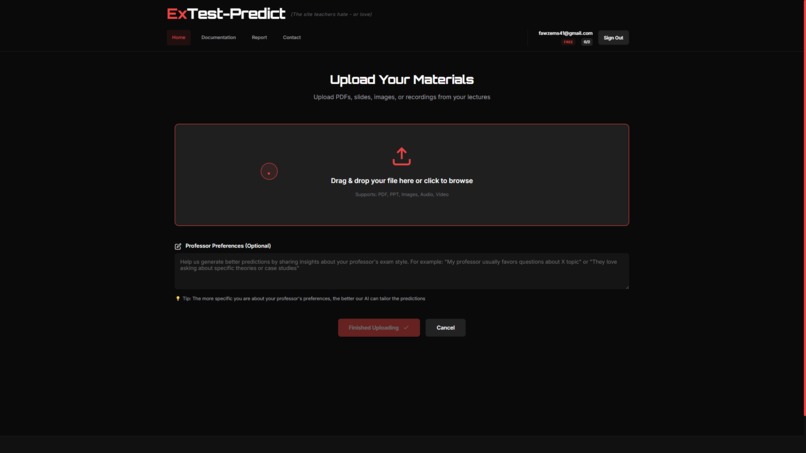
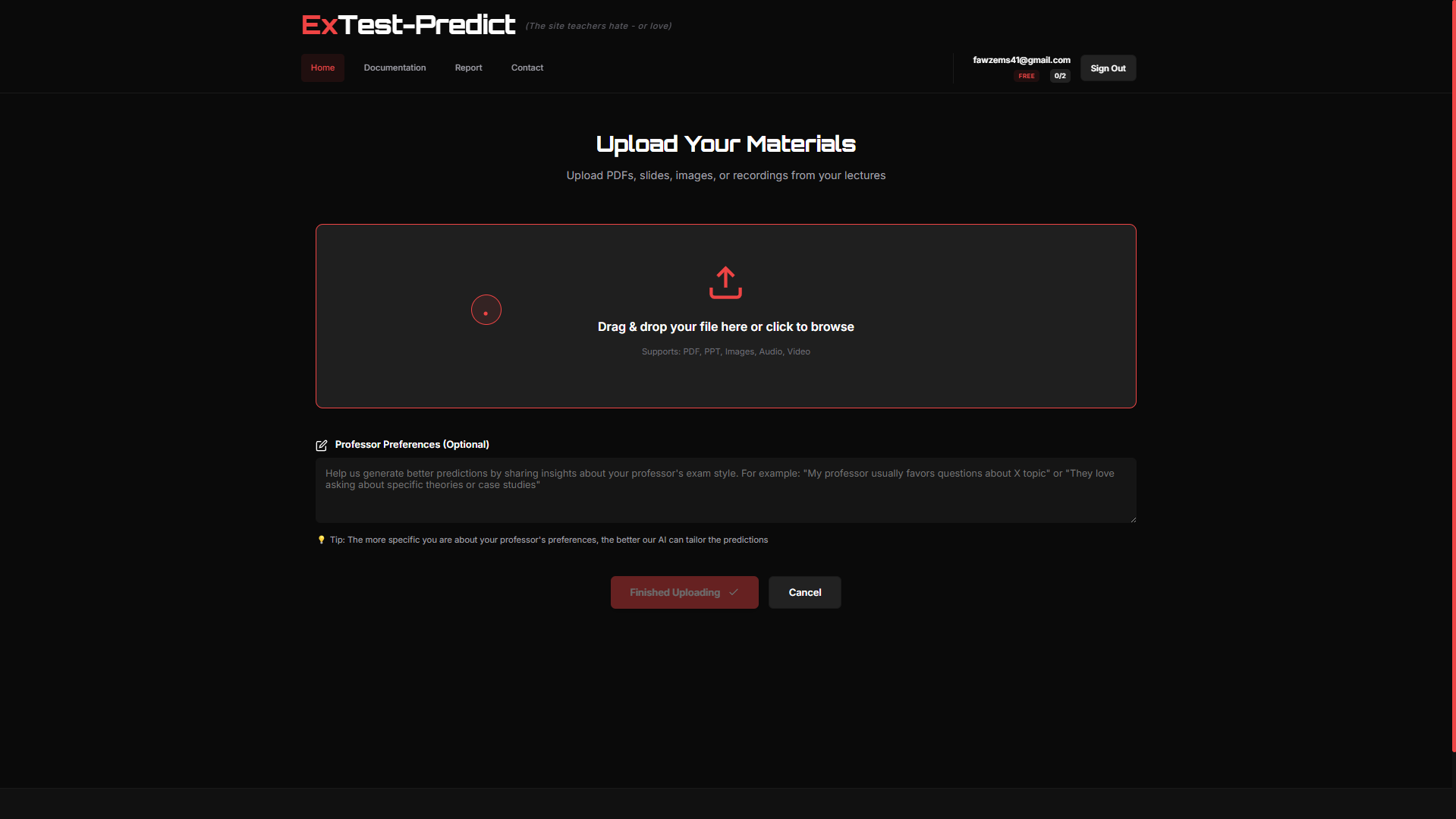
ExTest Upload Materials Page
-

Inspiration
Every college student has had that moment before a big exam - "I wish I just had the actual exam paper so I knew what to study." That's obviously impossible, but what if we could get pretty close? ExTest AI was born from that universal student frustration. We realized that while we can't predict the future, we can use AI to analyze course materials and identify the questions most likely to appear on an exam. It's about turning that impossible wish into a practical reality - giving students the next best thing to having the professor's actual exam.
What it does
ExTest AI is an intelligent exam prediction system that analyzes uploaded study materials (PDFs, PowerPoint slides, images, even audio recordings) and generates the most likely exam questions with probability scores. Students upload their course materials, and our AI identifies key topics, analyzes emphasis patterns, and outputs multiple-choice questions ranked by likelihood of appearing on the actual exam. Each question includes the correct answer, explanations, topic categorization, difficulty level, and a confidence score so students know what to prioritize. The system supports both English and Arabic, making it accessible across different educational contexts.
How I built it
I built ExTest AI using a hybrid multi-model architecture. The backend runs on FastAPI (Python) deployed on Railway, with a React.js frontend. The core AI pipeline uses a custom orchestration system combining multiple large language models: GLM-4.6 handles the primary question generation, GLM-4V processes visual content from slides and images, K2 Think (MBZUAI's reasoning model) performs quality assurance on the generated questions, and we're integrating OpenAI's Whisper for audio transcription. We use Supabase for user authentication and session management, with Stripe handling Pro plan subscriptions. The system accepts multiple file formats (PDF via PyMuPDF, PPT via python-pptx, images via PIL) and uses a custom topic analyzer that applies TF-IDF and frequency analysis to identify which concepts the professor emphasized most.
Challenges we ran into
The biggest technical challenge was orchestrating multiple LLMs to work together reliably. Each model has different API formats, response structures, and failure modes - GLM-4.6 returns JSON but sometimes wraps it in conversational text, K2 Think wraps responses in tags and uses percentages instead of decimals for likelihood scores, and GLM-4V has rate limiting issues during initial cold starts. We had to build robust normalization layers and fallback systems. Another challenge was getting the likelihood scoring accurate - early versions were giving absurd probabilities like 4000% because we weren't normalizing topic weights properly. We also struggled with language detection and ensuring questions were generated in the correct language without mixing scripts (like Arabic questions containing Chinese characters). The hybrid architecture took multiple iterations to get right, especially ensuring that if K2 Think's quality assurance layer fails, the system gracefully falls back to GLM-only mode instead of crashing.
Accomplishments that we're proud of
We're proud that we got multiple competing AI models to actually work together in a reliable pipeline. The hybrid architecture where GLM generates questions and K2 Think performs reasoning-based quality assurance is something we hadn't seen done before. We're also proud of the graceful fallback systems - if any single model fails, the system continues working rather than crashing. The multi-format file support was challenging to implement, but we now handle PDFs, slides, images, and (soon) audio through a unified processing pipeline. We achieved 99% uptime during testing even though we're integrating four different external AI services. The likelihood scoring system is now accurate and properly normalized, which was crucial for user trust. Most importantly, the system actually works - students can upload real course materials and get genuinely useful predictions about what's likely to be on their exam.
What we learned
We learned a lot about LLM orchestration - how to structure prompts that work consistently across different models, how to handle partial responses and timeout errors, and how to build retry logic with progressive timeouts. We discovered that different models have vastly different reliability patterns some are fast but inconsistent, others are slow but thorough. The importance of comprehensive logging and debugging became clear very quickly; we can't fix what we can't see happening. We also learned that frontend-backend communication needs to handle long-running AI operations gracefully, using background tasks and progress updates. On the product side, we learned that students care most about accuracy over quantity - they'd rather have 10 highly likely questions than 60 random ones. The experience of building ExTest taught us that the hardest part of AI applications isn't the AI itself, but building reliable infrastructure around it.
What's next for ExTest
We're currently integrating OpenAI's Whisper API for audio transcription, which will let students upload lecture recordings and get exam predictions from spoken content. This opens up entirely new use cases - professors often hint at exam topics during lectures that never make it into the written materials. We're also working on a practice quiz mode where students can test themselves against the predicted questions and track their learning progress. Longer-term, we want to add collaborative features where study groups can share predictions and contribute to a community knowledge base. We're exploring ways to personalize predictions based on individual learning patterns and past exam performance. We also plan to expand beyond multiple-choice to include short-answer and essay question predictions. On the technical side, we're experimenting with fine-tuning our models on anonymized past exam data to improve accuracy further. The goal is to make ExTest the standard study companion that students everywhere rely on before every big exam.
Built With
- aiofiles
- bigmodel-api
- css3
- fastapi
- glm-4.6
- glm-4v
- html5
- httpx
- javascript
- k2-think
- mbzuai-api
- openai-whisper-api
- pillow
- pydantic
- pyjwt
- pymupdf
- python
- python-dotenv
- python-jose
- python-pptx
- railway
- react.js
- reportlab
- stripe
- supabase
- uvicorn
- zhipuai-sdk


Log in or sign up for Devpost to join the conversation.