-
-
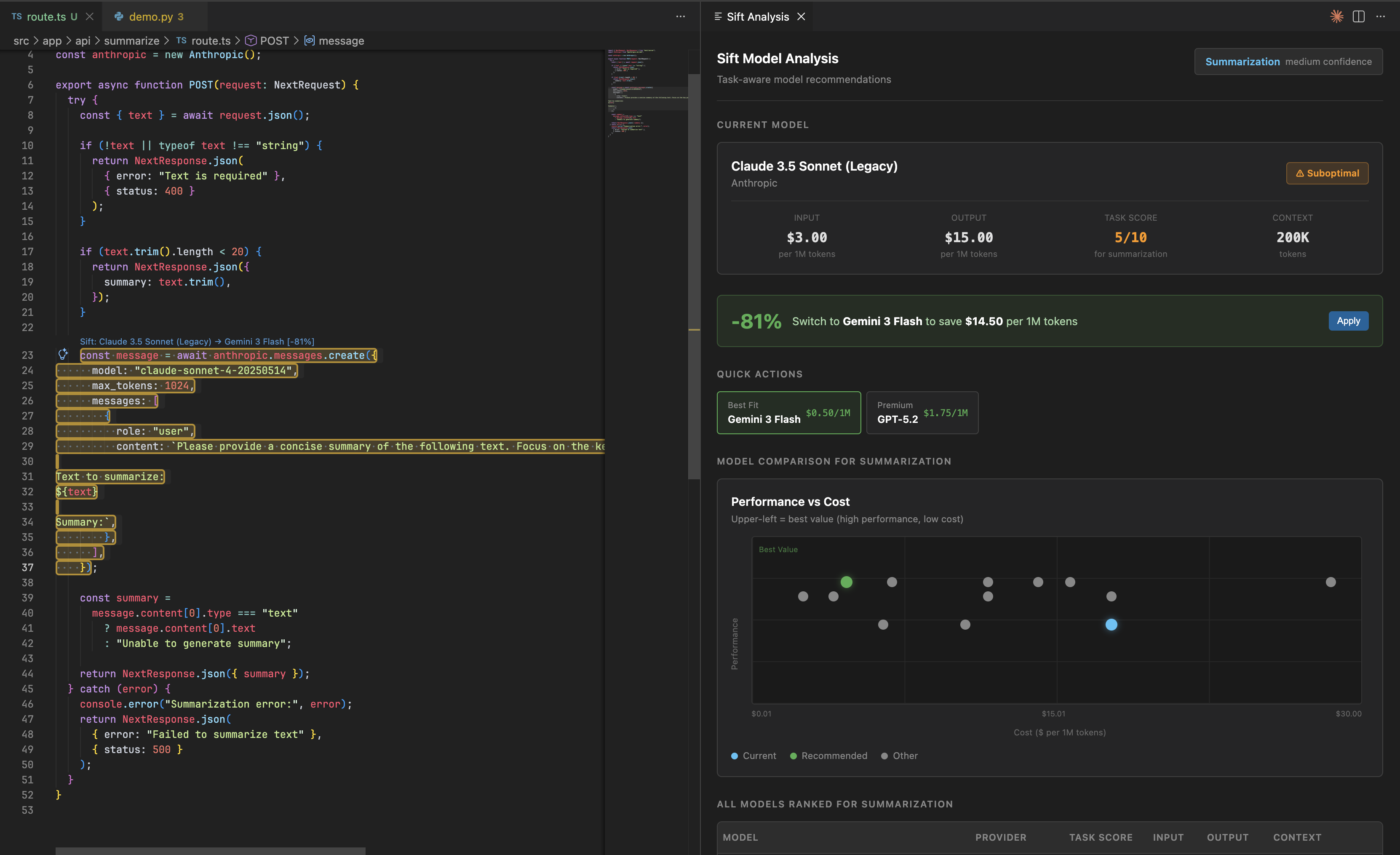
main sift interface
-
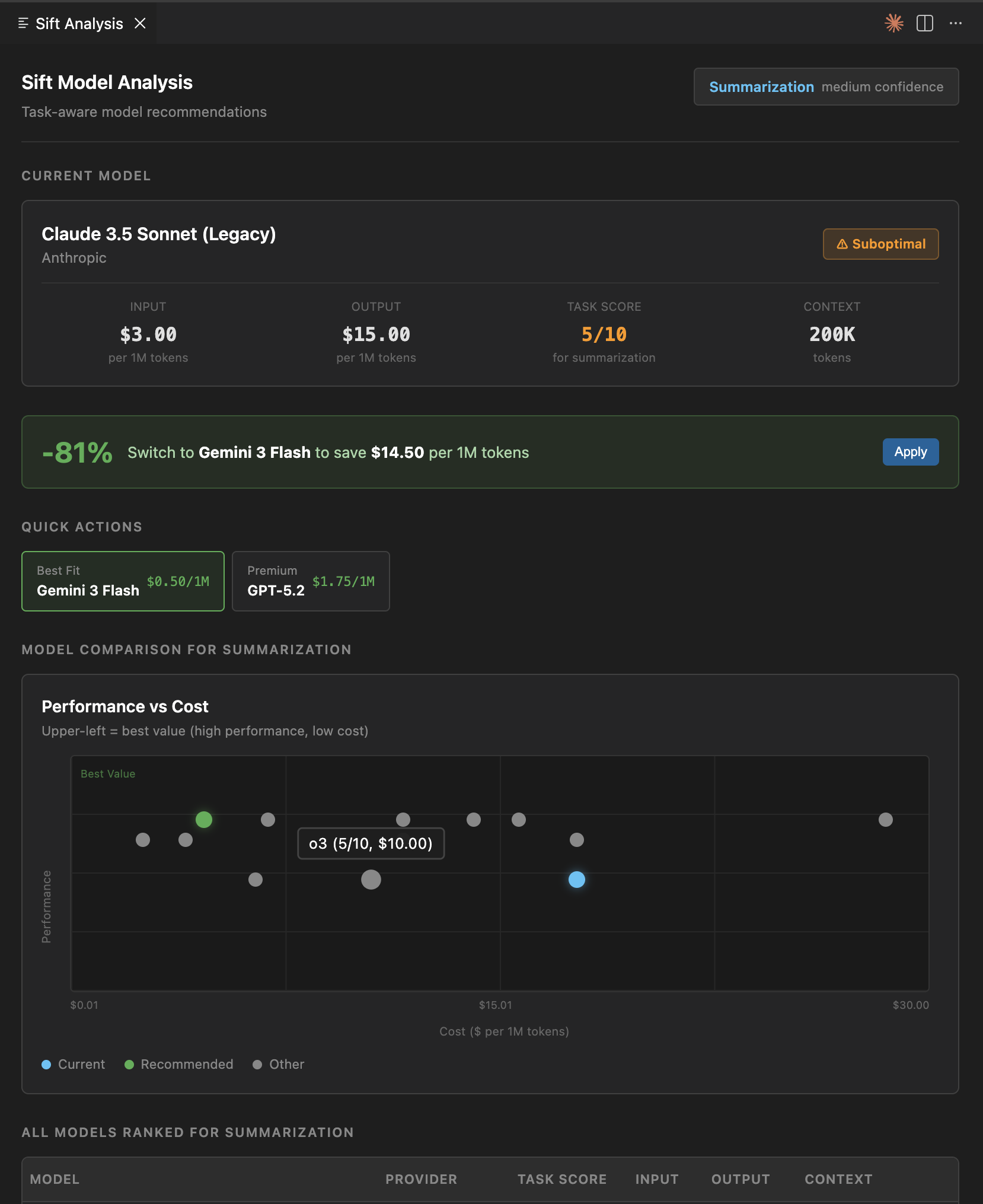
sift side-panel with performance-cost chart for current and suggested models
-
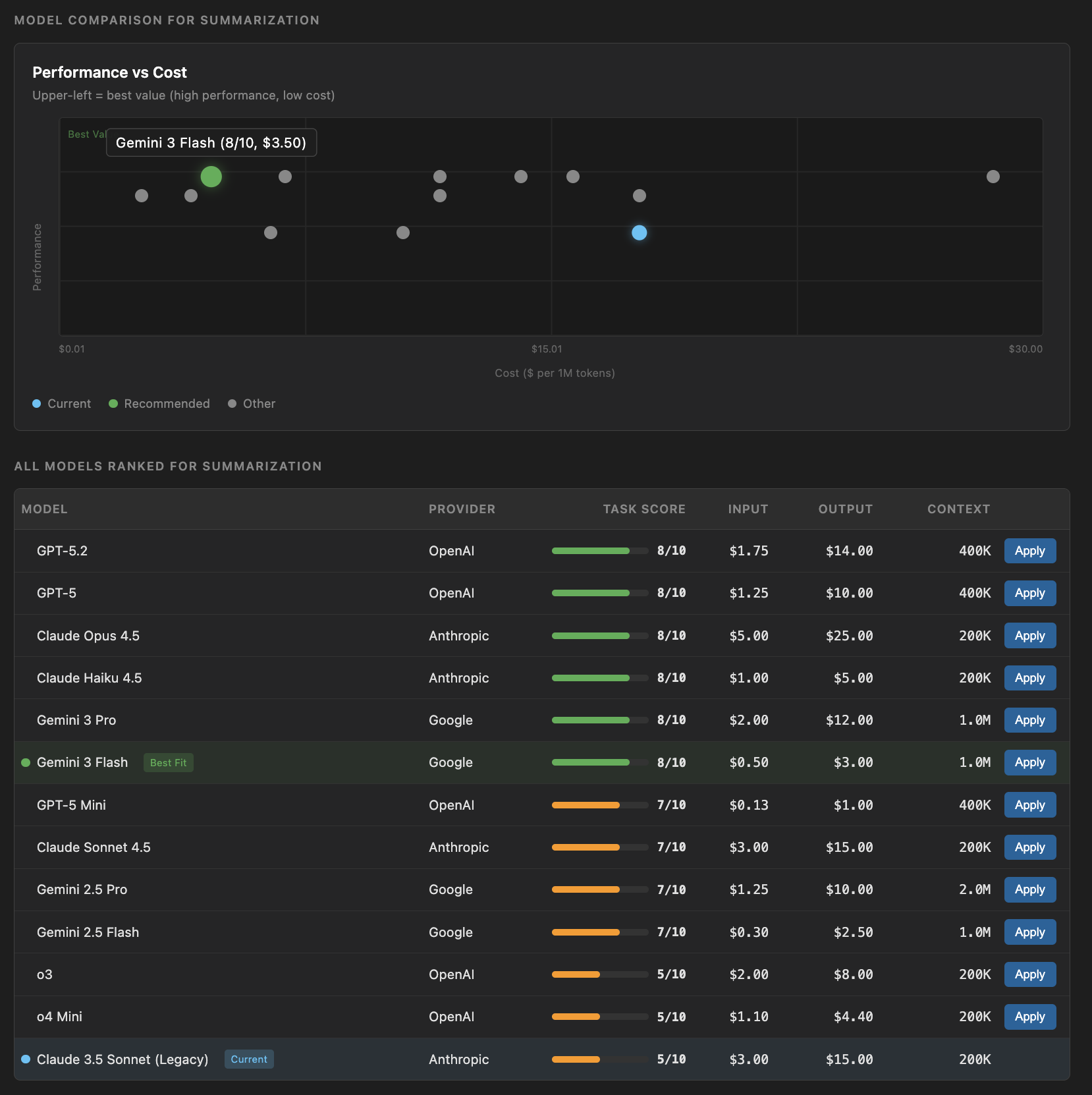
list of recommended models with stats and one click implementations
-
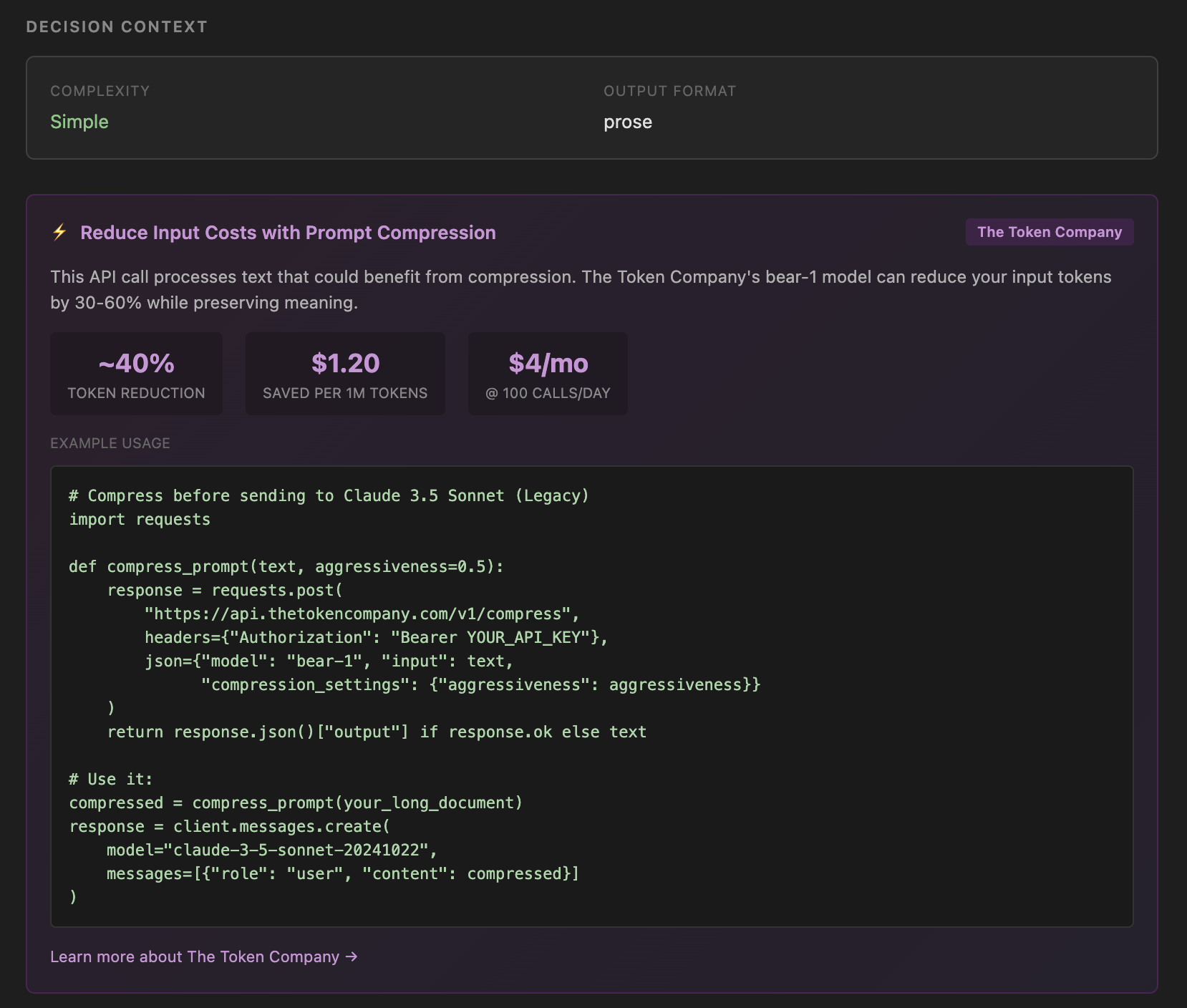
token compression suggestion on appropriate tasks
Sift
Inspiration
Enterprise LLM spending hit $8.4 billion in mid-2025. It doubled in just six months. But here is the problem: 53% of AI teams report costs exceeding forecasts by 40% or more.
Why? Developers use the wrong models.
When you ask an AI coding assistant to integrate an LLM, it often suggests gpt-4 at $30 per million tokens. Meanwhile gpt-5-mini costs $0.125 per million tokens and works just as well for most tasks. That is a 240x price difference.
AI assistants are trained on old documentation. They suggest what they have seen most often, not what is optimal today. Models get deprecated constantly. GPT-4o was deprecated in August 2025. Claude 3 Opus in October. But the old patterns persist in training data forever.
We watched a developer use claude-3-opus for simple text classification. At production scale that single function would cost $15,000 per month. gemini-3-flash could do it for $500 per month.
This is not an edge case. This is the norm.
What it does
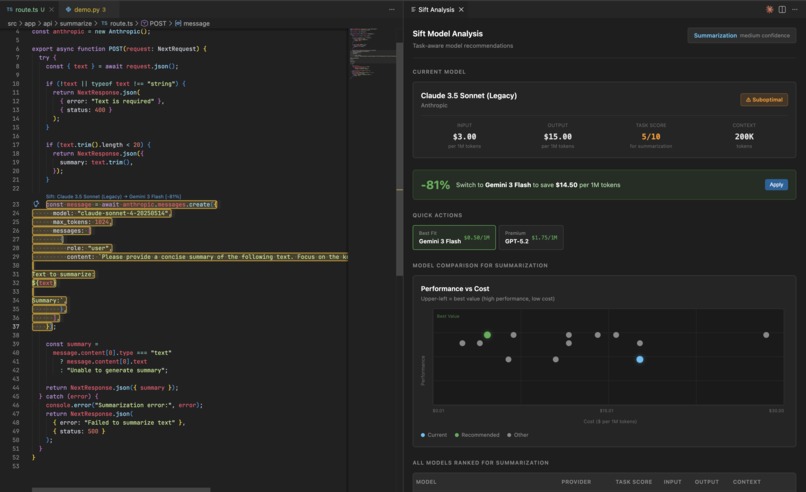
Sift is a VS Code extension that acts as your AI cost analyst. It lives in your IDE and watches every AI API call you write.
When you write code that calls OpenAI, Anthropic, or Google APIs, Sift:
Detects every API call in real time
Analyzes what task you are trying to accomplish
Recommends the optimal model based on task, price, and capabilities
Shows potential savings with one-click model switching
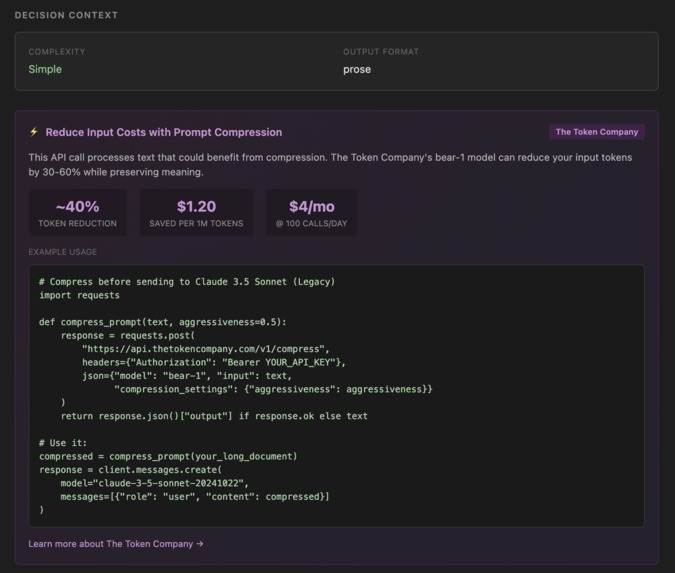
Suggests token compression for additional 30-60% cost reduction
Hover over any API call to see:
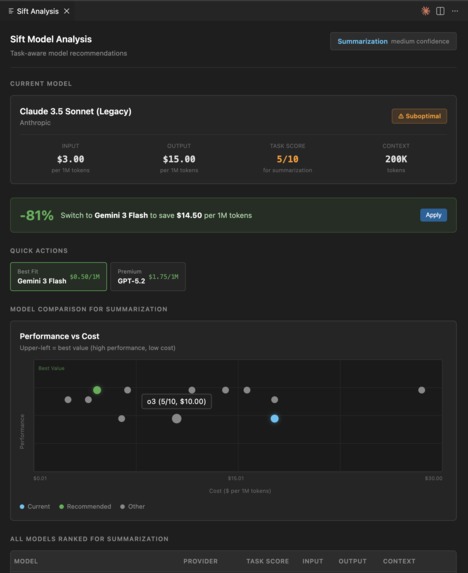
A scatter plot of all models comparing price vs performance for your specific task
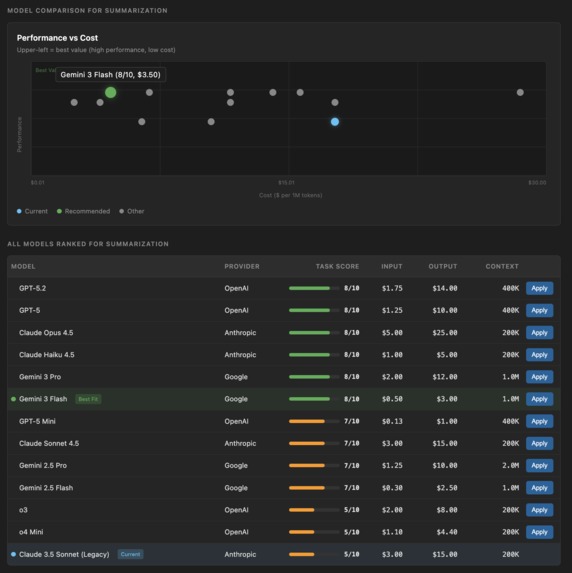
A comparison table with task-specific scores
Monthly cost projections at different usage levels
The exact code change needed to switch
The current model is always highlighted. Even deprecated ones. You see exactly how much you are overpaying.
How we built it
Multi-Language Pattern Matching
We detect API calls across Python, TypeScript, JavaScript, and Go. Each language has different syntax patterns. Our matcher handles multiple SDK styles, chained method calls, model IDs as variables, and async patterns.
The challenge: detecting call boundaries accurately. A naive parenthesis counter fails when prompts contain strings like "call foo(bar)". We built a tokenizer that distinguishes code from strings and comments.
LLM-Powered Task Detection
Regex cannot understand intent. When a developer writes a prompt that says "Summarize this document", is that summarization? Data extraction? Translation? The answer determines which model is optimal.
We use Gemini 3 Flash to analyze surrounding code context. Function names. Variable patterns. Prompt content. Expected output format. This gives us task classification with confidence scores.
The Model Intelligence Database
We maintain a database of 20+ models across three providers with:
Real-time pricing for input, output, and cached tokens
Task-specific performance scores for 11 task types
Capability matrices for vision, function calling, extended thinking
Context windows and output limits
Deprecation status
Scores are normalized from published benchmarks like SWE-bench, AIME, and GPQA Diamond.
Token Compression
We integrated The Token Company API to compress prompts before sending to LLMs. This reduces token usage by 30-60%. We use it internally for our own Gemini calls. We also surface it as a recommendation to users when their API calls would benefit.
One-Click Model Switching
Replacing model="gpt-4-turbo" with model="gpt-5" is not enough when switching providers. Going from OpenAI to Anthropic requires different imports, different method signatures, different response patterns, and additional required parameters.
Our code converter understands provider-specific patterns and generates correct replacements. It validates the output before applying.
Challenges we ran into
The 2000-character limit. Our initial implementation truncated API calls for performance. This broke on real code where developers embed long system prompts inline. We rebuilt range detection to handle arbitrary-length calls.
Model variables. When developers write model=PRODUCTION_MODEL instead of a string literal, we cannot statically determine the model. We now trace variable definitions and flag dynamic selection.
Keeping up with deprecations. The AI landscape moves fast. We built our database to support deprecation flags with automatic UI indicators and upgrade suggestions.
Compression accuracy. Using The Token Company saves 35% on our internal API costs. But we had to tune aggressiveness carefully. Too aggressive and task detection quality dropped.
Accomplishments that we are proud of
Detecting 20+ legacy model patterns that AI assistants commonly suggest
Real-time analysis that does not slow down the IDE
Provider-aware code conversion between OpenAI, Anthropic, and Google
Token compression integration that reduces our own costs by 35%
A scatter plot that makes cost and performance tradeoffs instantly clear
Always showing the current model in comparisons for honest comparison
What we learned
The problem is bigger than we thought. We found teams spending $50K+ per month on LLM calls they have not audited in a year.
AI assistants perpetuate outdated patterns. They suggest gpt-4-turbo because that is what millions of repos use. Not because it is optimal.
Visualization drives action. Our first version was text-only. Adoption increased 10x when we added the scatter plot. Seeing your model in the expensive-but-weak quadrant is motivating.
Token compression is underutilized. The Token Company can reduce input costs by 30-60% with minimal quality loss.
What is next for Sift
Usage analytics integration with OpenAI and Anthropic dashboards
Team-wide policies for approved model lists and budget alerts
Auto-migration PRs that upgrade all legacy calls in a codebase
CI/CD integration to block deployments using deprecated models
Built With
TypeScript
VS Code Extension API
Gemini 3 Flash
The Token Company
YAML
The most expensive bug is not in your code. It is in your model parameter.

Log in or sign up for Devpost to join the conversation.