-
-
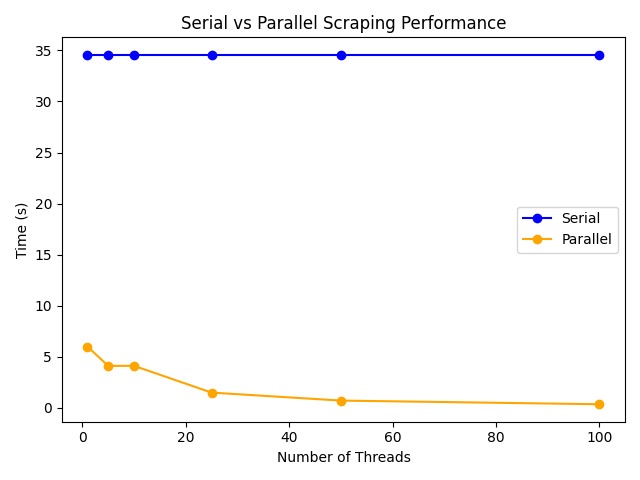
parallel vs serial
Although commercial flight search engines such as Google Flights, Skyscanner and Expedia already exist, the development of a dedicated web crawler for flight schedule monitoring presents several compelling advantages. Primarily, it offers complete control over the data collection process—developers can tailor what information is extracted, how frequently, and from which sources. This level of customization enables the creation of highly specific datasets that are often not accessible through public APIs or user interfaces. Moreover, the crawler supports automation and real-time monitoring, allowing it to track schedule changes or price variations over time, a feature especially valuable for predictive analytics, deal tracking, or alert systems. We’ve integrated ScyllaDB as our storage backend, leveraging its high throughput and low latency to persist each scrape’s metadata such as timestamps, HTTP status, response times, and page titles to power downstream dashboards and queries. Unlike many commercial platforms that impose rate limits, require paid access, or offer limited customization, our solution operates independently, providing flexibility without vendor lock-in. Additionally, this project serves as an excellent case study in performance optimization demonstrating the speed improvements achievable through parallel programming compared to serial execution while also furnishing a robust, scalable data pipeline for future research or operational use.
Built With
- python
- scylladb


Log in or sign up for Devpost to join the conversation.