Inspiration
Machine Learning
What it does
Learning based Article.
How we built it
Reading docs and stuffs.
Challenges we ran into
So Deep dive learning about topic. Its like an ocean (never ends)!
Accomplishments that we're proud of
Hands-on with Intermediate learning..
What we learned
Much more than written below :)
What's next for Explore Machine Learning
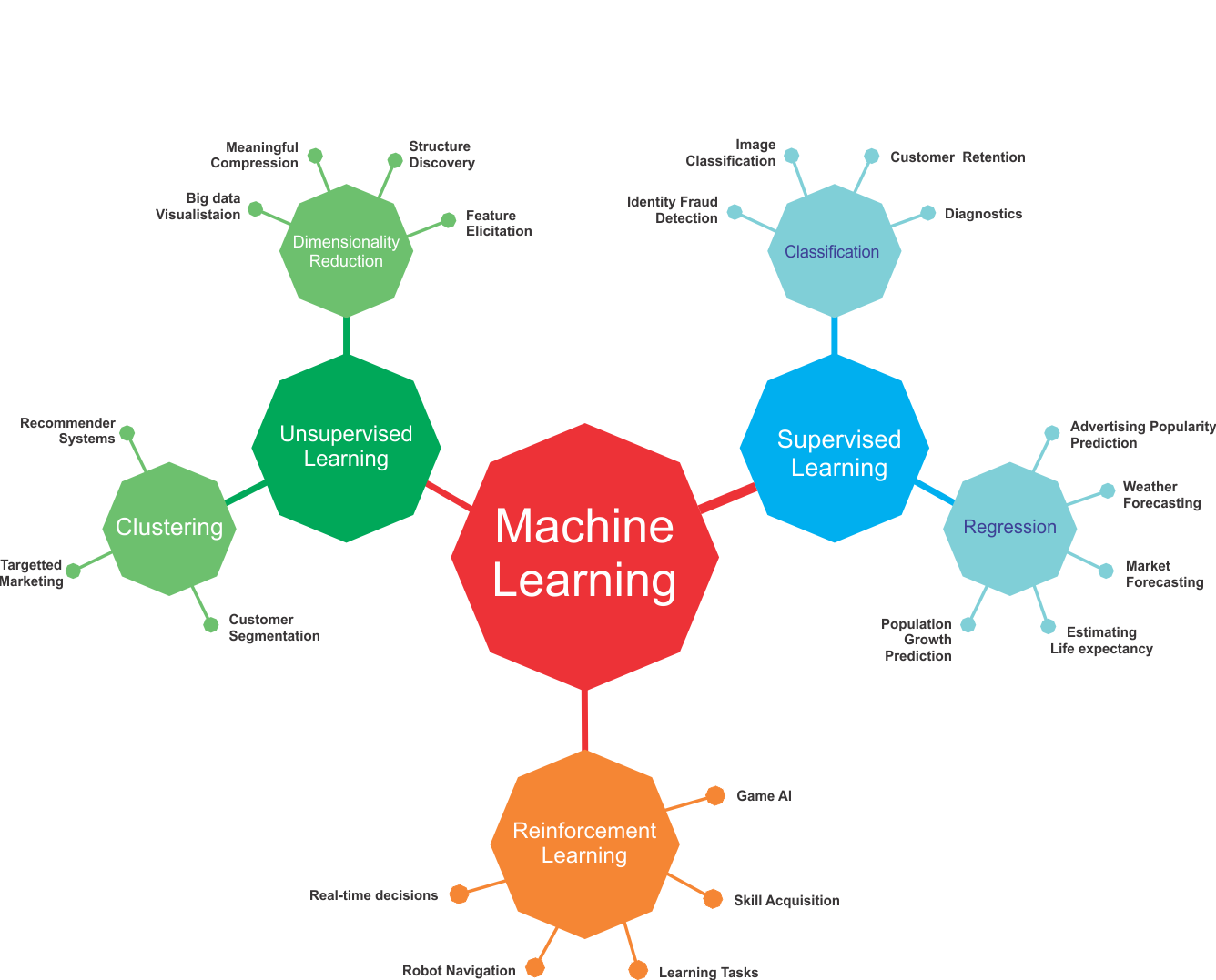
Machine Learning(ML), probably one of the most intriguing topics of this decade. Also known as ML, this field is considered one of the pillars of the 21st century. Everyone is talking about it, so there has to be a reason why! Machine Learning is a field of Computer Science. It tries to teach computers how to learn, so they can help humans solve difficult tasks. The nice thing is that computers should learn without being explicitly programmed to do that. Computers just see 0s and 1s, and nothing more. Lot of research For this reason, ML researchers had to struggle for many years, before being able to find a way to solve this problem.
WHAT IS MACHINE LEARNING?
At a very high level, machine learning is the process of teaching a computer system how to make accurate predictions when fed data. Those predictions could be answering whether a piece of fruit in a photo is a banana or an apple, spotting people crossing the road in front of a self-driving car, whether the use of the word book in a sentence relates to a paperback or a hotel reservation, whether an email is spam, or recognizing speech accurately enough to generate captions for a YouTube video. The key difference from traditional computer software is that a human developer hasn't written code that instructs the system how to tell the difference between the banana and the apple. Instead a machine-learning model has been taught how to reliably discriminate between the fruits by being trained on a large amount of data, in this instance likely a huge number of images labelled as containing a banana or an apple. Machine learning is a field of study that looks at using computational algorithms to turn empirical data into usable models. The machine learning field grew out of traditional statistics and artificial intelligences communities. From the efforts of mega corporations such as Google, Microsoft, Facebook, Amazon, and so on, machine learning has become one of the hottest computational science topics in the last decade. Through their business processes immense amounts of data have been and will be collected. This has provided an opportunity to re-invigorate the statistical and computational approaches to autogenerate useful models from data. Machine learning algorithms can be used to (a) gather understanding of the cyber phenomenon that produced the data under study, (b) abstract the understanding of underlying phenomena in the form of a model, (c) predict future values of a phenomena using the above-generated model, and (d) detect anomalous behavior exhibited by a phenomenon under observation. There are several open-source implementations of machine learning algorithms that can be used with either application programming interface (API) calls or nonprogrammatic applications. Examples of such implementations include Weka, Orange, and Rapid Miner. The results of such algorithms can be fed to visual analytic tools such as Tableau and Spotfire to produce dashboards and actionable pipelines.
HOW DO YOU EVALUATE MACHINE-LEARNING MODELS?
Once training of the model is complete, the model is evaluated using the remaining data that wasn't used during training, helping to gauge its real-world performance. When training a machine-learning model, typically about 60% of a dataset is used for training. A further 20% of the data is used to validate the predictions made by the model and adjust additional parameters that optimize the model's output. This fine tuning is designed to boost the accuracy of the model's prediction when presented with new data. For example, one of those parameters whose value is adjusted during this validation process might be related to a process called regularization. Regularization adjusts the output of the model so the relative importance of the training data in deciding the model's output is reduced. Doing so helps reduce overfitting, a problem that can arise when training a model. Overfitting occurs when the model produces highly accurate predictions when fed its original training data but is unable to get close to that level of accuracy when presented with new data, limiting its real-world use. This problem is due to the model having been trained to make predictions that are too closely tied to patterns in the original training data, limiting the model's ability to generalize its predictions to new data. A converse problem is underfitting, where the machine-learning model fails to adequately capture patterns found within the training data, limiting its accuracy in general. The final 20% of the dataset is then used to test the output of the trained and tuned model, to check the model's predictions remain accurate when presented with new data.
WHY IS DOMAIN KNOWLEDGE IMPORTANT?
Another important decision when training a machine-learning model is which data to train the model on. For example, if you were trying to build a model to predict whether a piece of fruit was rotten you would need more information than simply how long it had been since the fruit was picked. You'd also benefit from knowing data related to changes in the color of that fruit as it rots and the temperature the fruit had been stored at. Knowing which data is important to making accurate predictions is crucial. That's why domain experts are often used when gathering training data, as these experts will understand the type of data needed to make sound predictions.
WHAT ARE NEURAL NETWORKS AND HOW ARE THEY TRAINED?
A very important group of algorithms for both supervised and unsupervised machine learning are neural networks. These underlie much of machine learning, and while simple models like linear regression used can be used to make predictions based on a small number of data features, as in the Google example with beer and wine, neural networks are useful when dealing with large sets of data with many features. Neural networks, whose structure is loosely inspired by that of the brain, are interconnected layers of algorithms, called neurons, which feed data into each other, with the output of the preceding layer being the input of the subsequent layer. Each layer can be thought of as recognizing different features of the overall data. For instance, consider the example of using machine learning to recognize handwritten numbers between 0 and 9. The first layer in the neural network might measure the intensity of the individual pixels in the image, the second layer could spot shapes, such as lines and curves, and the final layer might classify that handwritten figure as a number between 0 and 9.
IS MACHINE LEARNING CARRIED OUT SOLELY USING NEURAL NETWORKS?
Not at all. There are array of mathematical models that can be used to train a system to make predictions. A simple model is logistic regression, which despite the name is typically used to classify data, for example spam vs not spam. Logistic regression is straightforward to implement and train when carrying out simple binary classification, and can be extended to label more than two classes. Another common model type are Support Vector Machines (SVMs), which are widely used to classify data and make predictions via regression. SVMs can separate data into classes, even if the plotted data is jumbled together in such a way that it appears difficult to pull apart into distinct classes. To achieve this, SVMs perform a mathematical operation called the kernel trick, which maps data points to new values, such that they can be cleanly separated into classes. The choice of which machine-learning model to use is typically based on many factors, such as the size and the number of features in the dataset, with each model having pros and cons.
WHY IS MACHINE LEARNING SO SUCCESSFUL?
While machine learning is not a new technique, interest in the field has exploded in recent years.
This resurgence follows a series of breakthroughs, with deep learning setting new records for accuracy in areas such as speech and language recognition, and computer vision.
What's made these successes possible are primarily two factors; one is the vast quantities of images, speech, video and text available to train machine-learning systems.
But even more important has been the advent of vast amounts of parallel-processing power, courtesy of modern graphics processing units (GPUs), which can be clustered together to form machine-learning powerhouses.
Today anyone with an internet connection can use these clusters to train machine-learning models, via cloud services provided by firms like Amazon, Google and Microsoft.
As the use of machine learning has taken off, so companies are now creating specialized hardware tailored to running and training machine-learning models. An example of one of these custom chips is Google's Tensor Processing Unit (TPU), which accelerates the rate at which machine-learning models built using Google's TensorFlow software library can infer information from data, as well as the rate at which these models can be trained.
These chips are not just used to train models for Google DeepMind and Google Brain, but also the models that underpin Google Translate and the image recognition in Google Photo, as well as services that allow the public to build machine learning models using Google's TensorFlow Research Cloud. The third generation of these chips was unveiled at Google's I/O conference in May 2018, and have since been packaged into machine-learning powerhouses called pods that can carry out more than one hundred thousand trillion floating-point operations per second (100 petaflops).
In 2020, Google said its fourth-generation TPUs were 2.7 times faster than previous gen TPUs in MLPerf, a benchmark which measures how fast a system can carry out inference using a trained ML model. These ongoing TPU upgrades have allowed Google to improve its services built on top of machine-learning models, for instance halving the time taken to train models used in Google Translate.
As hardware becomes increasingly specialized and machine-learning software frameworks are refined, it's becoming increasingly common for ML tasks to be carried out on consumer-grade phones and computers, rather than in cloud datacentres. In the summer of 2018, Google took a step towards offering the same quality of automated translation on phones that are offline as is available online, by rolling out local neural machine translation for 59 languages to the Google Translate app for iOS and Android.
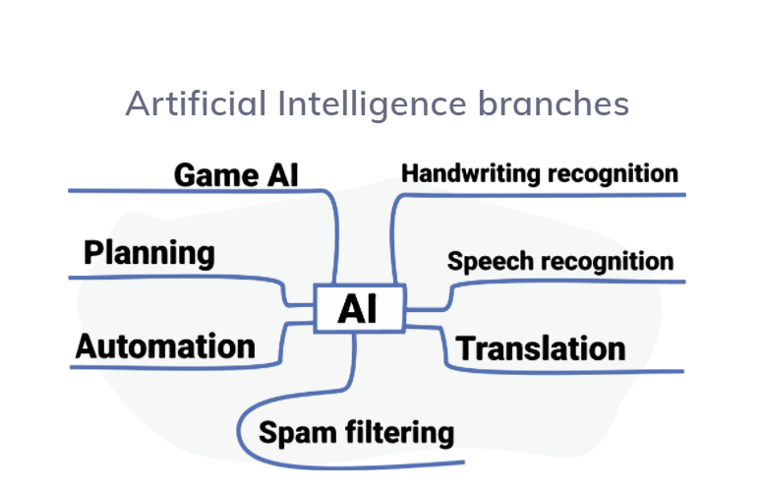
To give you an example, following are some of the branches that AI is composed of:
• Handwriting recognition
• Speech recognition
• Translation
Handwriting recognition Where a machine tries to understand handwriting and its properties
Speech recognition Similar to handwriting recognition, but with the intent of understanding meaning and sentiment of sentences
Translation Allowing machines to create a bridge between two different languages
Spam filtering Used mostly with emails (but extendable to other domains), where something unwanted is filtered.
Automation Reducing the tasks where a human is needed, in order to allow him to concentrate on other aspects of his work.
Game AI To be used for non playable characters in games, in order to show more intelligent behaviour or better performance.
Planning To be used for non playable characters in games, in order to show more intelligent behaviour than simple rule-based scripts.
Where is Machine Learning? Machine Learning can be seen as the part of AI that allow computers to take as input some data and makes decisions by learning from it. Every time there is something to learn from data, ML comes to the rescue! It can be something easy like deciding if it’s raining based on the humidity outside. Or it can be something difficult, like telling if a review on a website is positive or negative. How can we teach them? The answer is with numbers. Machine Learning can be seen as an elegant way of formulating real world problems into their mathematical equivalent. In this way a computer, relying only on numbers, can be used to solve those mathematical problems.
Sentiment analysis For example, consider the task of saying whether someone is happy based on what he says. Sure, this is a particularly difficult problem, but trust me, scientists found a way of converting it to just numbers. And allowing a computer to try and predict it. ***********************************************************************
Log in or sign up for Devpost to join the conversation.