-
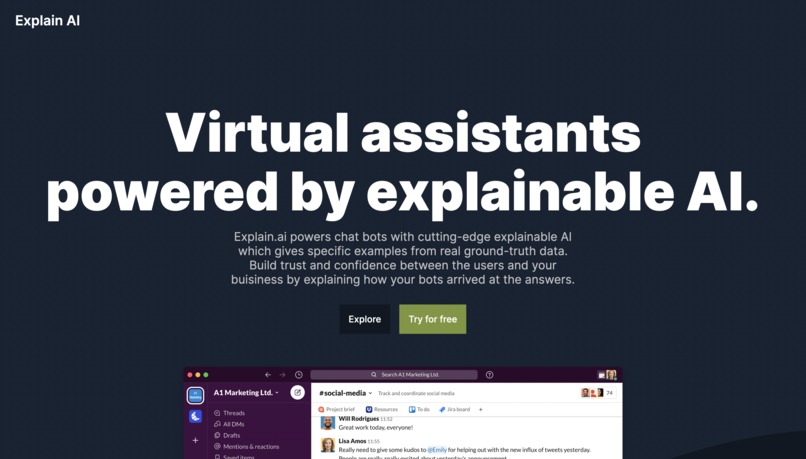
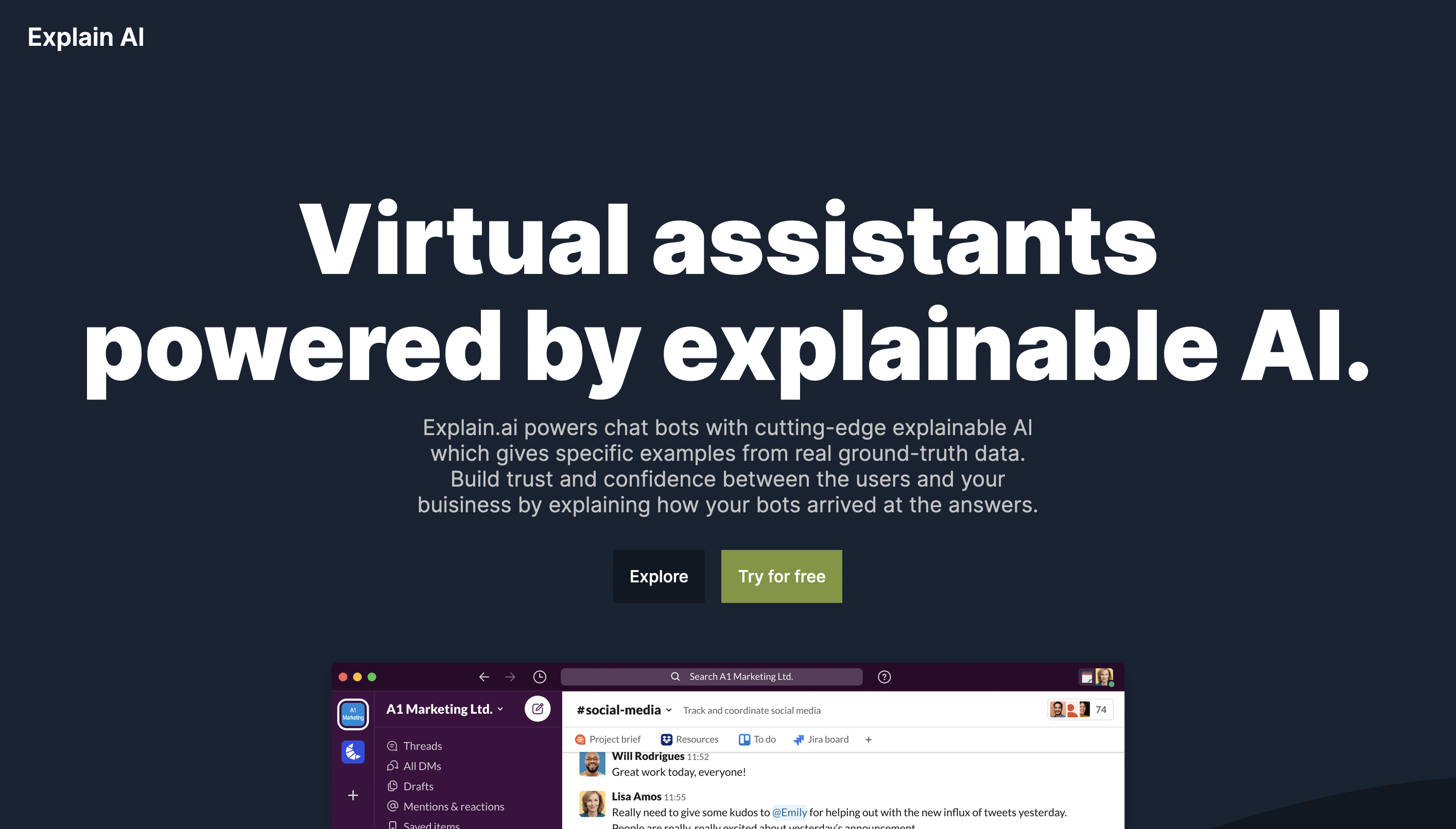
Landing Page
-
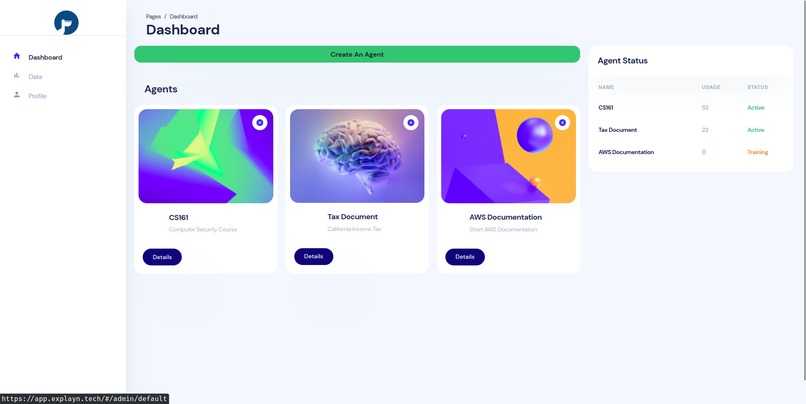
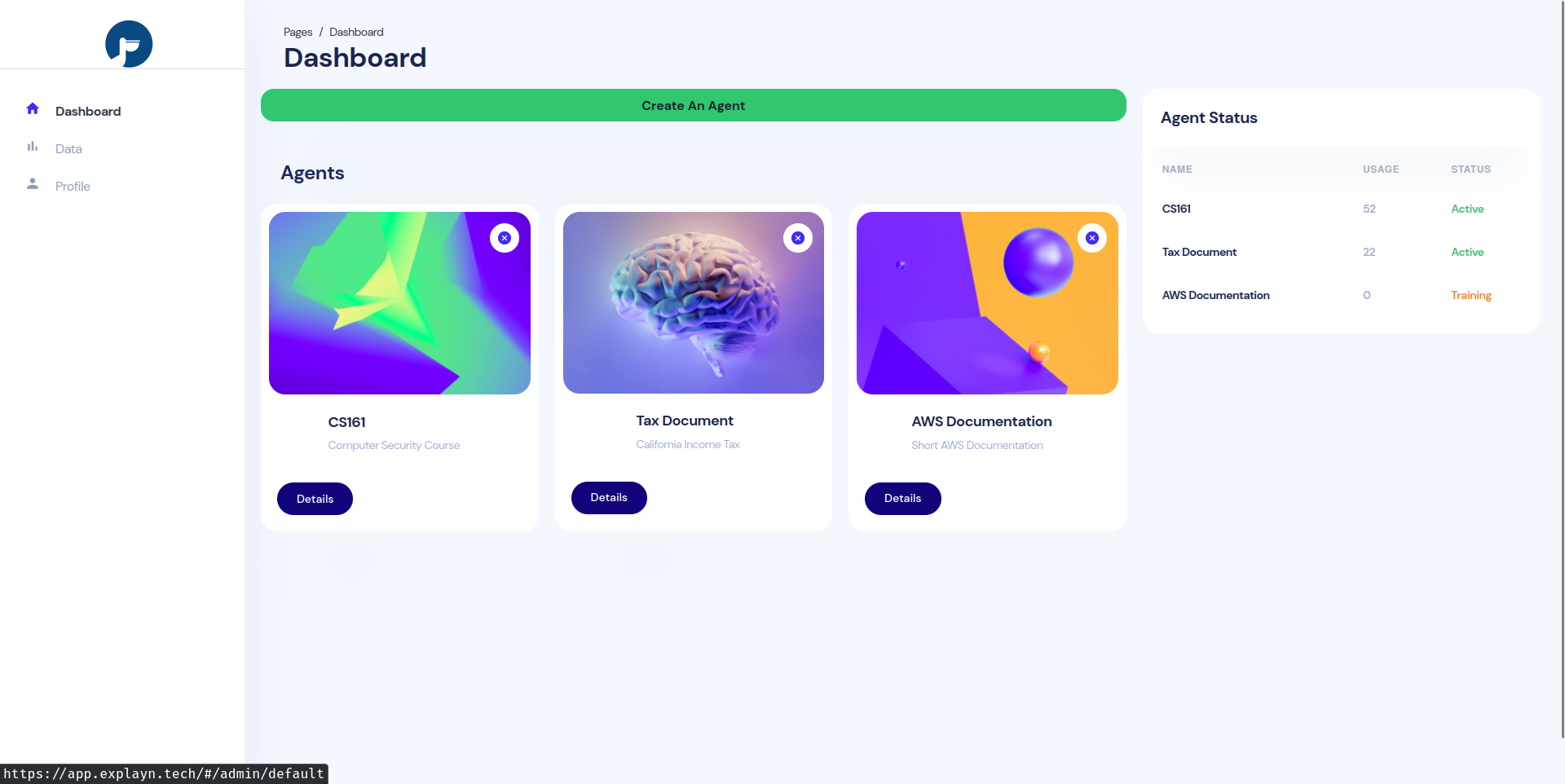
Dashboard
-
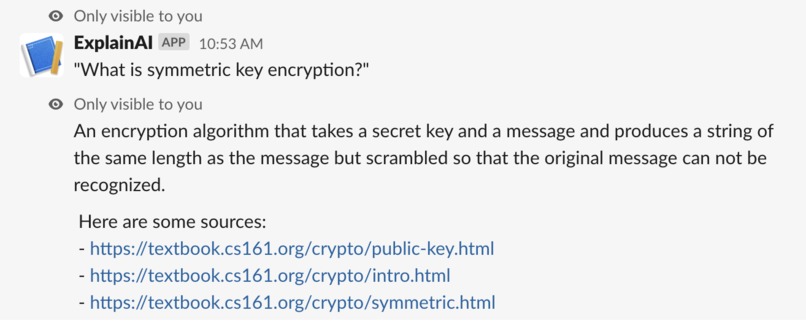
Slack integration
-

Logo


Inspiration
Several years ago, the first vision of a “know-it-all” language model came out. However, it is now several years later and we still do not see these large language models in production. As such, question answering is still largely an unsolved problem.
The two predominant paradigms in question answering are one, searching based on keywords, and two, a language model (AI) that responds to a user-defined input.
The former is ubiquitous and influential; just think of your favorite search engine. However, a search engine does not answer questions - it simply finds related documents. This mandates the patience to comb through massive amounts of data.
The latter has seen monumental developments in recent years. Models such as GPT-3, T5, and CLIP have each produced results that are eerily accurate. What they lack is the ability to point to the sources that influenced their answers. They are still just blackboxes in the end that cannot be easily interpreted or explained.
That’s where we come in, Explayn.AI operates between the two paradigms. It generates actual answers, while also citing the sources which directly influenced its outputs.
Additionally, we wanted to address two social issues with using large language models. First is minimizing the risk which arises when the model gives wrong answers. Second is that the language model becomes outdated the second we are done collecting data for it. Both of these cases are partially addressed in our solution because we provide the data which explains the results, and it can be analyzed for discrepancies and recency.
What it does
Takes a set of documents and trains a language model. Then you can ask a question, and the model gives you an answer along with the sources.
The other part of the project is an attempt to turn this into a marketable product. In essence, users send us documents/data to train a model on our infrastructure. We will provide them with an API endpoint to invoke their models.
Here, we’ve trained a model on Berkeley’s Computer Security course to demonstrate AI teaching assistants. Slack was used as an interface for this use case.
YOU can use it. Go to CalHacks 9.0 Slack Channel and type /explayn followed by your question about Computer Security https://textbook.cs161.org
Several other use cases we thought of:
- Developer documentation. Working with a new code base is never an easy endeavor. Allowing new recruits to query relevant parts of the documentation without prior knowledge would increase development velocity.
- Legal/Government documentations are notoriously verbose. Being able to reference specific subsections of the document makes life much easier.
- Educational tools such as virtual tutors and course chat bots.
How we built it
Core ML: Cohere's Embed, Finetune & Generate API Frontend: Next.js, React.js, ChakraUI Backend: Python, FastAPI, Slack (chatbot) Infra: Vercel (frontend), GCP (backend), CockroachDB serverless
Client (Frontend) has two operations:
- POST Create a new agent (ML model)
- GET List of agents created with credentials to invoke them (API endpoints & token)
Backend:
- Create: Call Cohere Finetune -> Call Cohere Embed -> Generate invocation details -> Notify client
- Get list of agents: Query CockroachDB -> Return response to client.
Challenges we ran into
Embedding a corpus of text with Cohere's API was expensive. When training our first few iterations of the model, we blew through the 75$ of free credits quickly. On our second account, we were wiser and more cognizant of how we're spending our credits, reusing embeddings once it's generated and limiting our dataset.
GCP only exposed one port, preventing us from deploying our code the way we intended to. To bypass that issue, we set up an NGINX reverse proxy and had it forward traffic to the GCP instance.
Our slack integration was having trouble with timeouts. Slack expects a response from an API it calls within a shorter time frame than our server was responding. Thankfully, FastAPI allows us to turn a function into a background process, enabling our server to respond to clients immediately while computation is happening behind the scenes.
Apart from that, CSS is always annoying, and, like everyone else, we had issues with the flaky WiFI and the lack of power chords.
Accomplishments that we're proud of
UI is okay this time. We stuck to our plan this plan & did not pivot this time.
What we learned
Taras: Learned how to set up domains. Vercel & Next.js are awesome.
Val: Making large language models respond with “good” sentences is challenging!
Ryan: Learned to use ChakraUI and that no CSS solution will ever make CSS less annoying.
What's next for Explayn AI
A more sophisticated language model that could generate more descriptive replies and better accuracy with its citation/references. Next would be to polish our fronted so that it can interact with customers. Then, launch it to the public while optimizing the backend to reduce operational costs & latency.
Built With
- chakraui
- cockroachdb
- cohere
- fastapi
- gcp
- javascript
- next.js
- python
- vercel




Log in or sign up for Devpost to join the conversation.