Inspiration
As professionals from various department we've often encounter how hard and time consuming Service Delivery and request / incident analysis in various organizations can be. Amount of time necessary for the people working on support lines or in other departments to properly analyze the tickets and allocate resources to it is high, very hard to optimize (most users don't know how to describe their needs professionally) and requires a lot of experience.
There are ways to improve the process (like implementing diligent dynamic forms or help the user with self-service article on their Customer Portal), but no matter how we approach the issue the human factor is still crucial and most popular way the people are issuing their request.
Therefore, we've decided, rather than forcing users to use the tool and adjust them to the software, use the software and adjust it to the users! This way, organizations can still work in the same principle as before (from the end-users perspective) but our solution is going to properly analyze their request, decompose it into useful data and allow the agents solve forward the issue to the users in most efficient way possible with the fitting priority of the request itself.
What it does
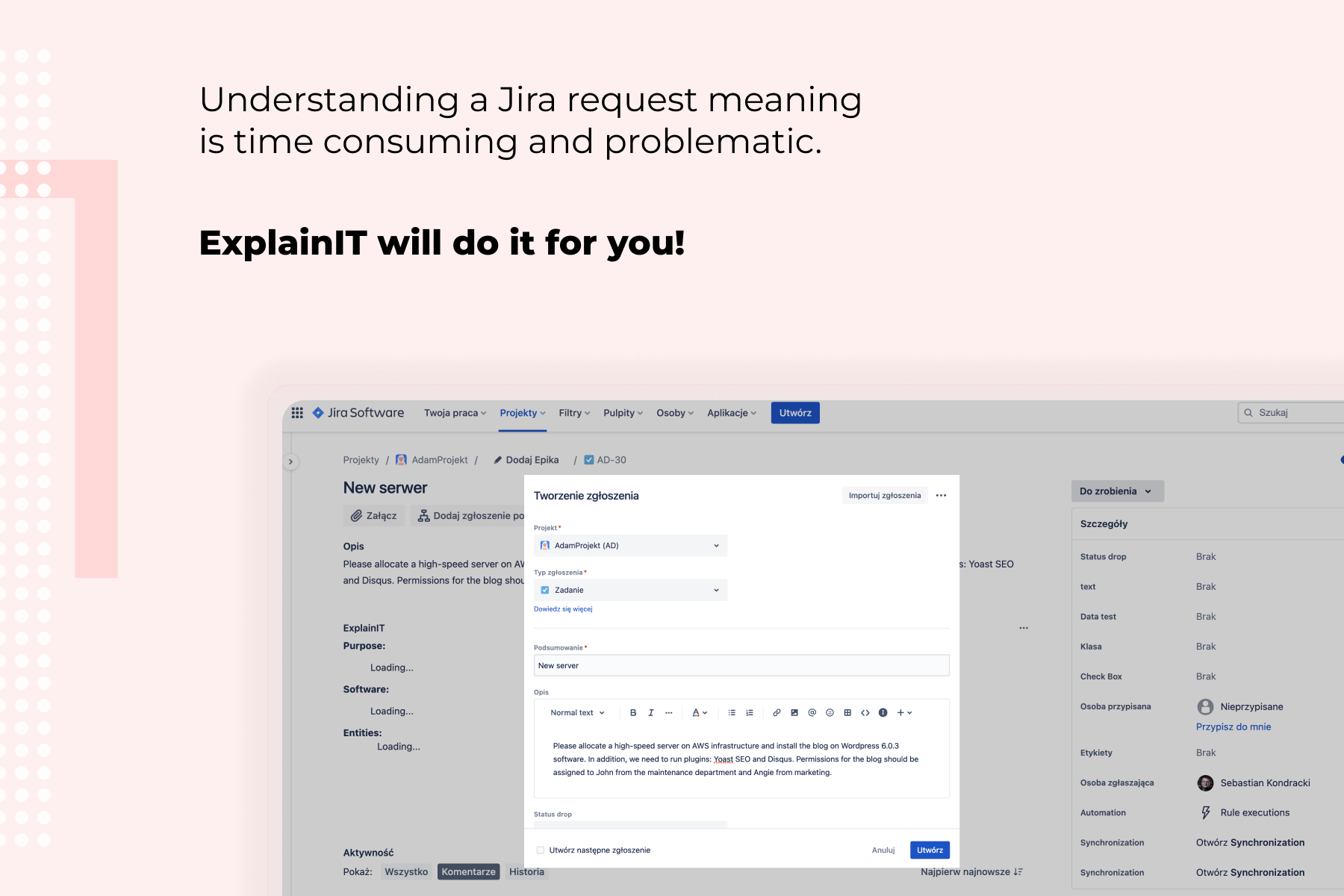
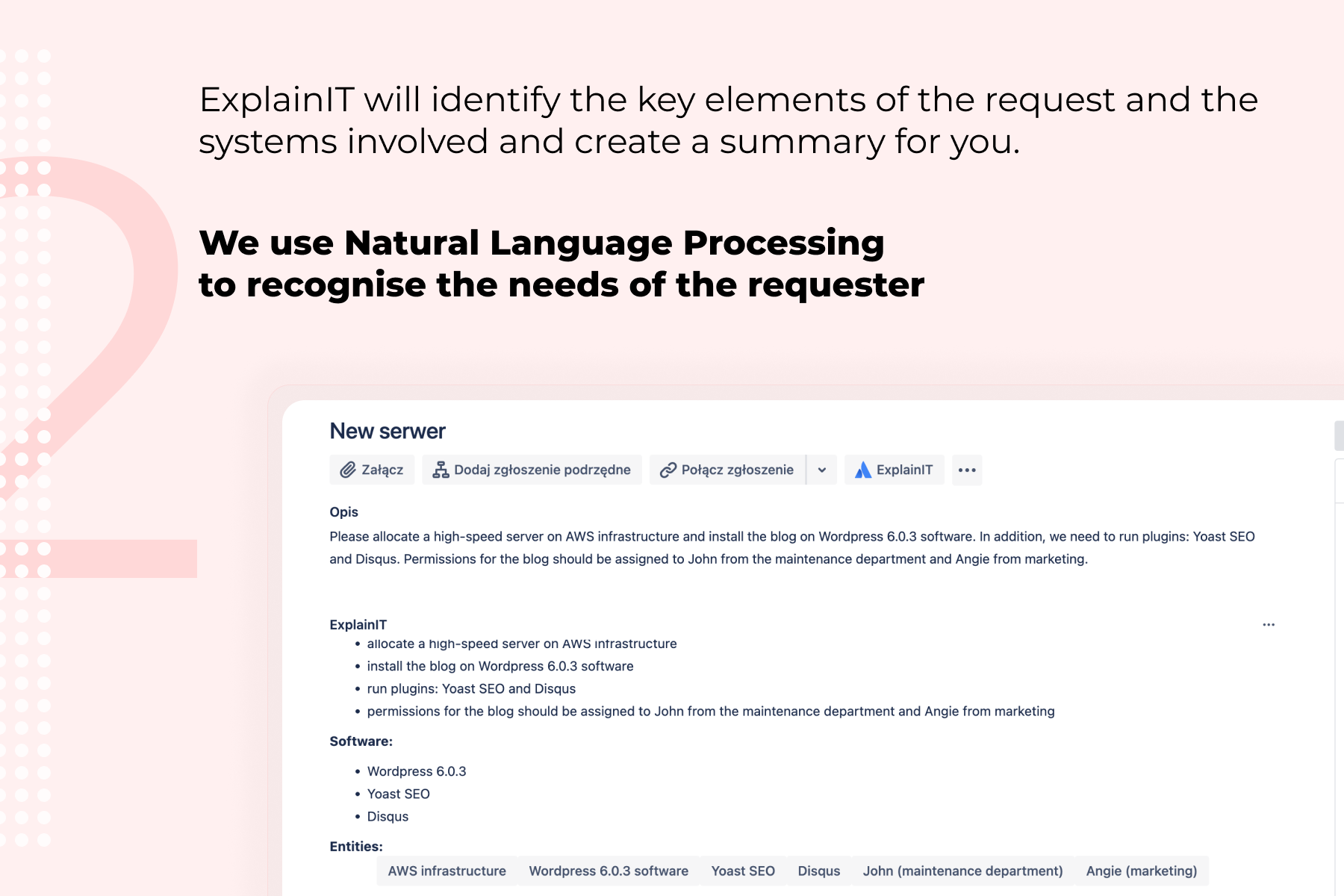
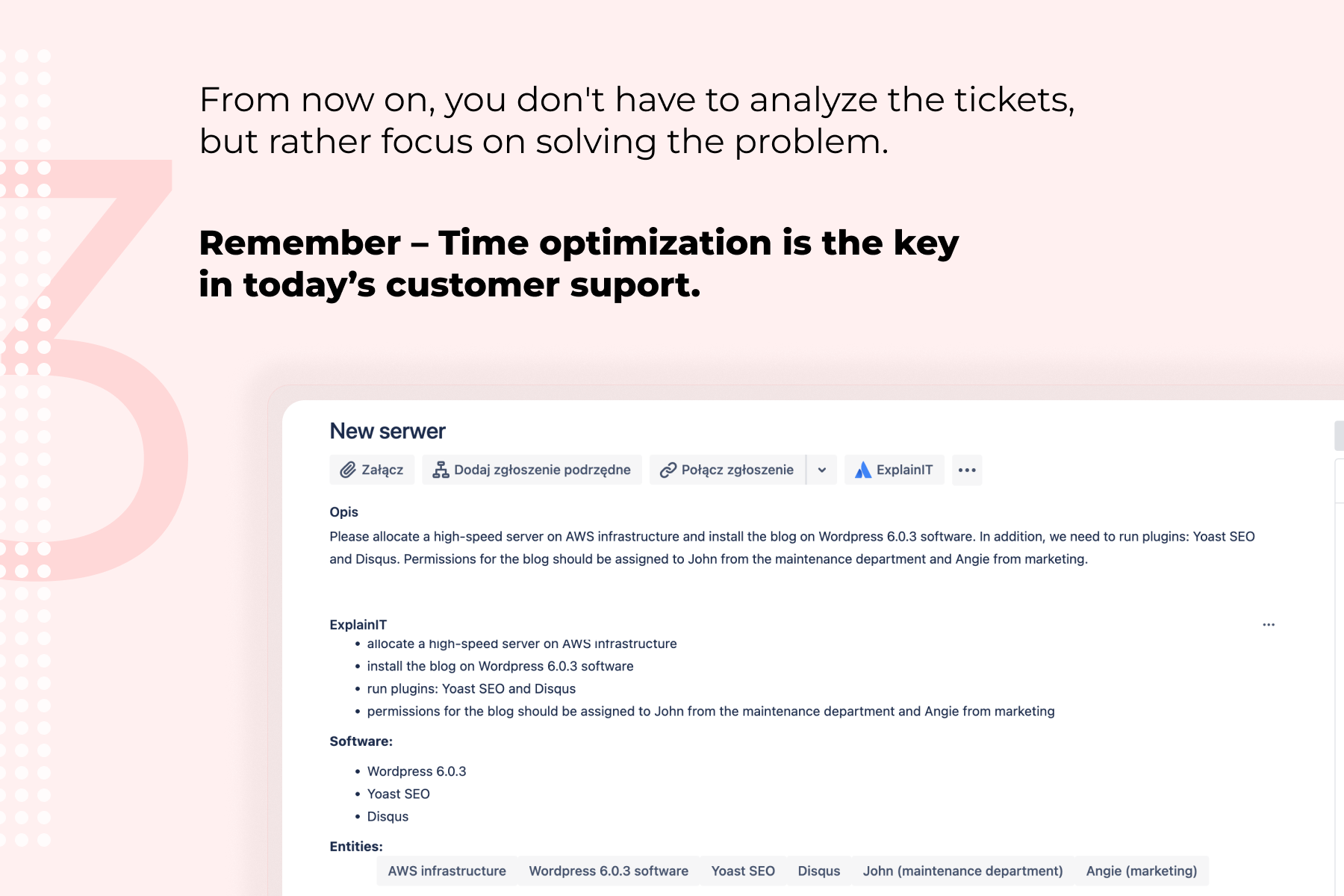
The tool itself, in its base value, is fairly straightforward. When the request is being sent and created in Jira (be it by the Customer Portal, email channel or other, external way (f.e integration with other software like Service Now)) then it's content is being decomposed into business entities. Those entities are taken from the description from the user, like "Office365", "Application name", exact Service name (f.e "On-boarding" and "Analytical Team") and being stored on the ticket itself.
Decomposed information contain the data about the purpose of the ticket (f.e allocating new memory to the server) what type of software is mentioned and needs attention from the agent or what type of entities are also stored in the description. It doesn't have to be only the service request; the tool itself can be adjusted and used for any type of the process that you can encounter in well-developed company.
Thanks to that decomposition, agent responsible for the ticket is going to know from the moment the ticket is created to what assets or his processes this ticket is assigned to, to what articles in Knowledge Base he should refer to or how to solve the ticket itself without the need to further communicate with the user itself. He or she doesn't have to waste time for basic analysis of the ticket and can start working on it as soon as he gets it or forward it to the designated team.
How we built it
We have created two apps: the Jira plugin, and the separate application that is responsible for processing data that comes from Jira. The Jira plugin passes over the issue description to the 'back-end' app and presents them in a separate custom panel on an issue when received responses.
Challenges we ran into
Presenting the summary of issues in a convenient and readable form. Transformer-type technology, which was developed several years ago, gives phenomenal results in text processing. However, all the control is implemented using natural language and a few coefficients of deep learning scope. So the biggest challenge was to implement special queries that give good results in data extraction. Completely different from, for example, using a given function for a given problem.
Accomplishments that we're proud of
Multilingualism, which very simply in the next versions can be developed and completely configured.
What we learned
How to use transformers, large language models and prompt engineering.
What's next for ExplainIT
Since the tool can be used in the Atlassian JSM ecosystem it's fair to say, that next features should revolve more around making it work with other modules such as "Automation" or "Insight", which would allow for further automation (f.e based on the decomposition, the ticket can be automatically assigned to the designated team by automation) or asset management (information about the request and it's lifecycle are going to be added automatically to the asset stored as an Insight Object.










Log in or sign up for Devpost to join the conversation.