
Inspiration
Imagine you want to watch Andrej Karpathy's latest three-hour lecture but you have twenty minutes. You paste the link into an AI summariser. What comes back is a polished video you can't trust — no sources, no way to fix one bad scene without restarting from scratch.
ExplainFlow came from that frustration.
What it does
ExplainFlow turns source material: text, PDFs, YouTube videos, images, audio into grounded visual explainers where every claim links back to the original source.
It has two modes:
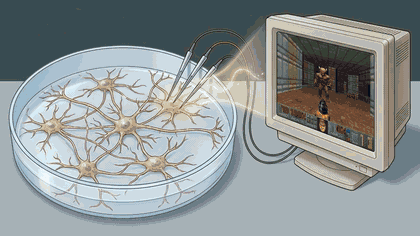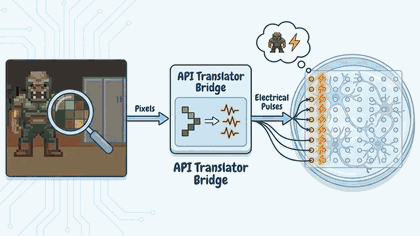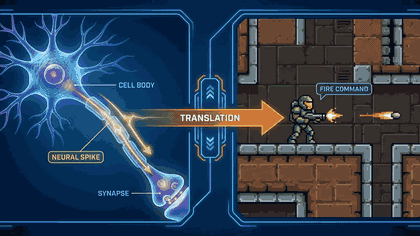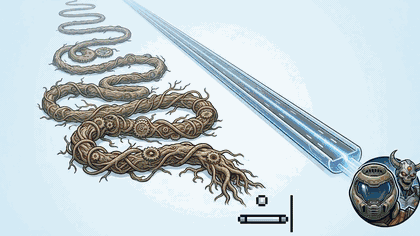
Advanced Studiois a directed production workflow. I pasted Mandelbrot's fractal coastlines paper and got a visual storyboard accessible to a curious teenager. ExplainFlow extracts a content signal (thesis, claims, evidence chains), locks a render profile (audience, visual style, density), builds a scene-by-scene script pack, then streams scenes with text, generated images, and audio — all in real time. Every scene is scored by an Auto QA gate. Scenes that fail are retried automatically before they ever reach the screen. After generation, I click any claim badge and the original source evidence opens. I can regenerate a single scene without touching the rest, upscale images, or export the whole production as a ZIP bundle or a cinematic MP4 with Ken Burns panning, crossfade transitions, and synchronised voiceover.Quickdoes all of that in one shot. I pasted a YouTube video about brain cells playing DOOM and got a proof-linked reel in seconds. I got an artifact with claim refs on every block. The Proof Reel lets me toggle between original source footage, generated images, or both — interleaved in a playlist. Export to MP4 and it's done.
Across both modes, proof survives the entire pipeline. That's the differentiator: users can inspect where the story came from instead of trusting a black box.
How I built it
I built ExplainFlow on Gemini through the Google GenAI SDK, with FastAPI on the backend and Next.js on the frontend, deployed on Google Cloud Run.
ExplainFlow is a staged, compound AI system:
- Intelligent Model Routing: I used gemini-3.1-pro-preview as the reasoning engine for extraction, planning, and QA validation, and routed visual generation to gemini-3-pro-image-preview for high-fidelity scene rendering.
- Backend Orchestration: The workflow is split into distinct extraction, planning, validation, streaming, and repair phases instead of one giant, fragile generation call.
- Stateful Frontend: Advanced Studio is organized as checkpointed workflow stages. I gave the user explicit control over the source, render profile, signal, Script Pack, and stream generation.
- Automated Quality Control: I engineered scene-level regeneration, planner QA, and stream-time QA retries to catch hallucinations before they reach the user.
Challenges I ran into
The hardest part was balancing speed with control. I wanted live-demo responsiveness, but I also needed source grounding, planner validation, scene-level retries, and proof-linked outputs. That meant tightening orchestration and reducing logic entanglement rather than making faster but less trustworthy calls.
Another challenge was the stateful Advanced Studio UI. Changing stage transitions, progress reporting, session notes, and regeneration behavior required understanding the real state graph and orchestration flow, not just pushing pixels.
Accomplishments that I'm proud of
- Every generated claim stays linked to its source evidence through the entire pipeline — from extraction through generation, review, and export.
- The planner criticises and repairs its own scene plan before spending tokens on image generation.
- Quick produces a grounded, proof-linked artifact in seconds. Then layers a Proof Reel and cinematic MP4 on top without re-planning.
- Benchmarked Gemini model paths live and split faster transcript normalization from more complete asset-backed recovery instead of guessing on speed/quality tradeoffs.
- Built and deployed the full system solo during the hackathon as live services on Google Cloud Run.
What I learned
- Source-grounded generation becomes much more usable when planning, validation, and generation are separated into explicit stages.
- Users need visible workflow state. Progress, checkpoints, notes, and recoverability matter as much as model quality in a complex agent workflow.
- Shared orchestration is valuable, but Quick and Advanced should reuse infrastructure without becoming the same experience.
What's next for ExplainFlow
I think of the following directions:
- Continuity-aware regeneration: When a user overrides one scene, downstream scenes should intelligently realign to match the new narrative state.
- Vertical-video export: Expanding beyond 16:9 to output source-backed reels—the format people actually share.
- Native Frame-Level Grounding: Moving beyond text transcripts to let Gemini visually "watch" the source video and extract specific charts or visual moments to intercut as raw B-roll.
- Embeddable Traceability: Exporting not just flat MP4s, but interactive web components where the end-viewer can click a scene to verify the underlying source PDF or YouTube clip.
Built With
- gemini
- gemini-api
- google-artifact-registry
- google-cloud
- google-cloud-run
- google-genai-sdk
- python
- typescript


Log in or sign up for Devpost to join the conversation.