-
-
AI Trading Copilot - 1
-
AI Trading Copilot - 2
-
predict-api-sequence-dig.png
-
architecture_diagram.png
Inspiration
Trading involves analyzing vast amounts of data, from price movements to news headlines. We were inspired to create a tool that leverages AI to process this information, predict potential stock trends, and present the findings in an accessible way. The core idea was to build an end-to-end system using publicly available data (stock prices and news) and modern cloud infrastructure, specifically focusing on a serverless architecture for cost-effectiveness and scalability. We also recognized the importance of explainability in AI-driven finance, aiming to provide insights into why the model makes certain predictions.
What it does
The AI Trading Copilot is a comprehensive system designed to assist traders:
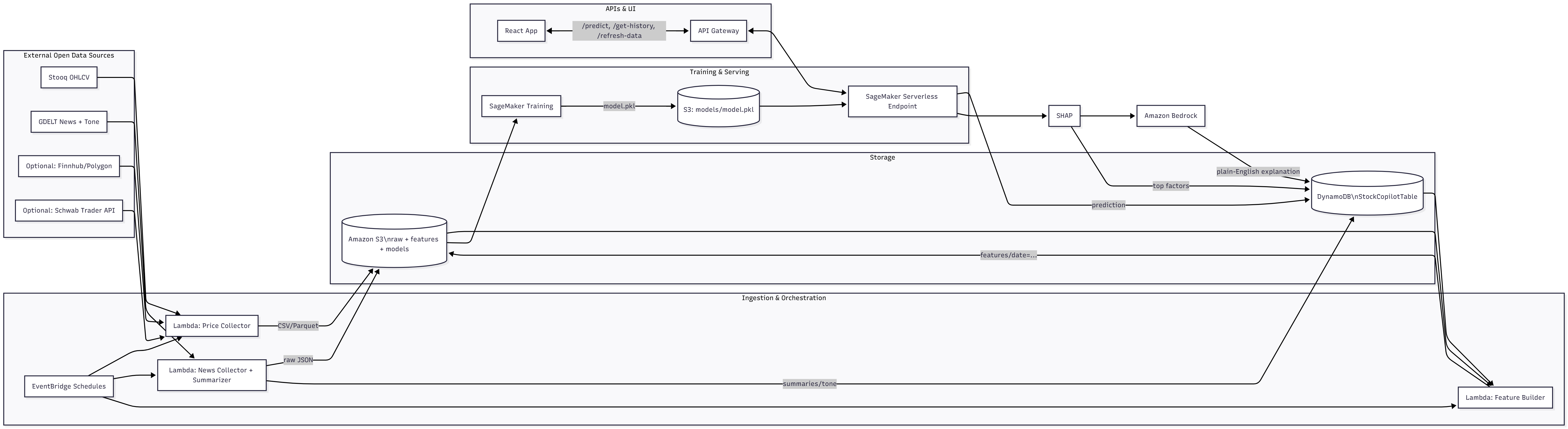
- Automated Data Collection: Regularly fetches daily stock price data (OHLCV) from Stooq and news articles mentioning specific stock tickers from the GDELT API, storing this raw data in an S3 bucket. It also logs news summaries to DynamoDB.
- Intelligent Feature Engineering: Processes raw price and news data to create meaningful features for the prediction model. This includes calculating technical indicators (RSI, moving averages, volatility, momentum) and incorporating news sentiment analysis (using AWS Comprehend) and rolling sentiment metrics. Features are stored daily in S3.
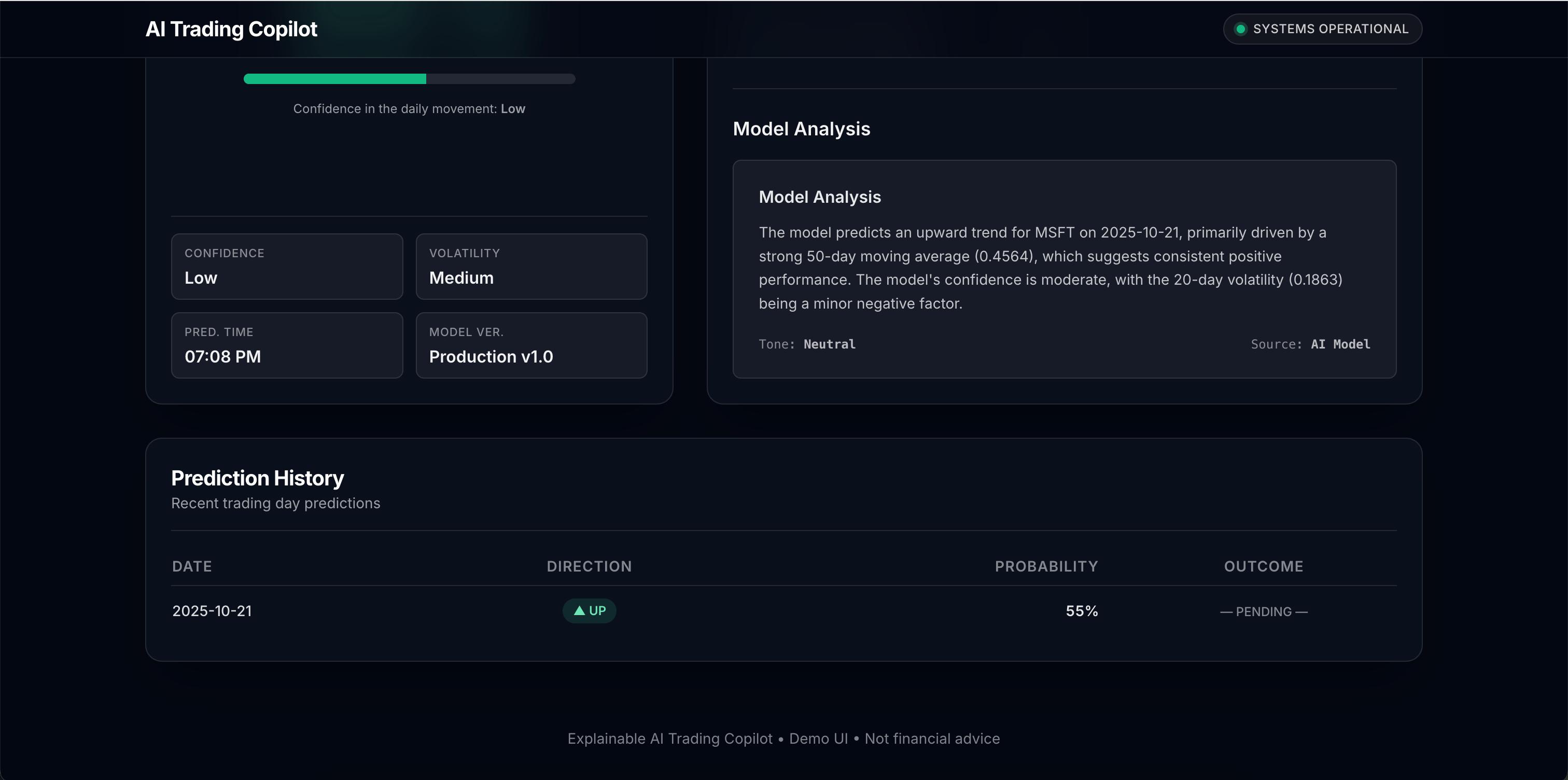
- Machine Learning Prediction: Employs a trained XGBoost model, hosted on AWS SageMaker Serverless Inference, to predict the next trading day's stock direction (Up or Down) and probability, based on the latest engineered features.
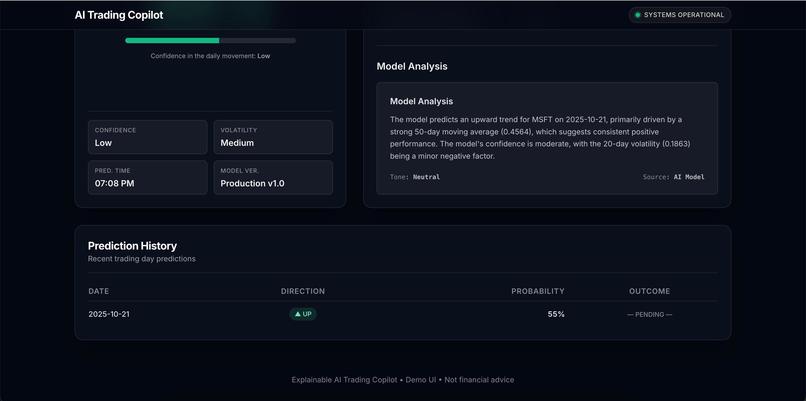
- Explainable Insights: Generates explanations for its predictions. It uses the SHAP library to identify the key features influencing the outcome and leverages Amazon Bedrock (specifically models like amazon.nova-lite-v1:0) to translate these technical factors into a plain-language summary.
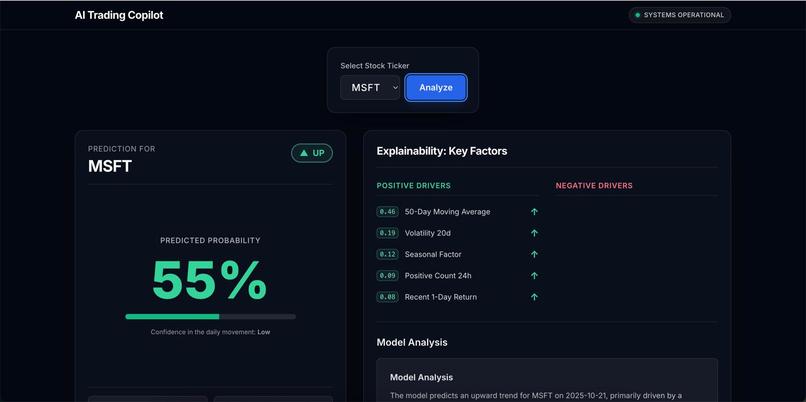
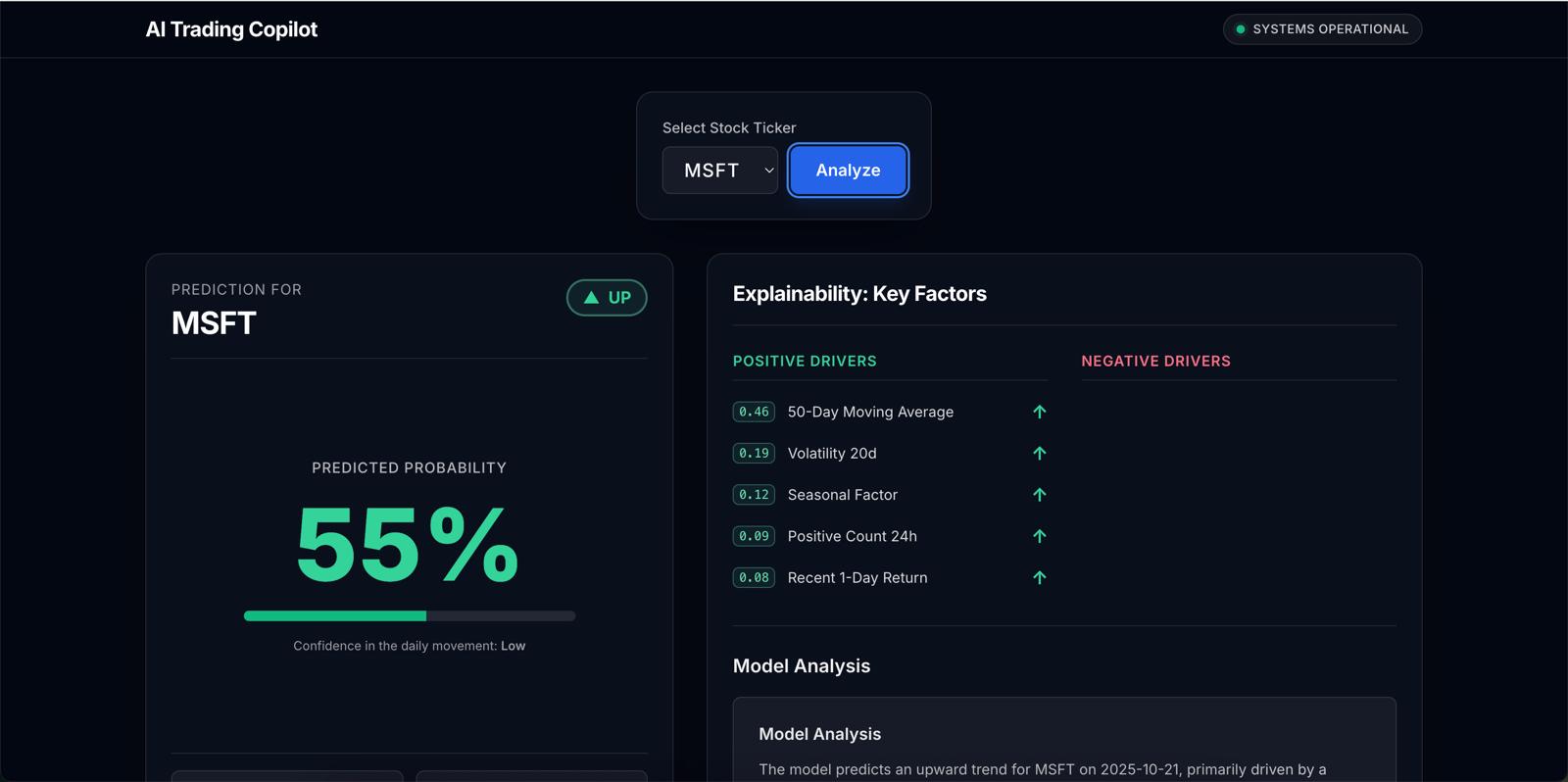
- User Interface: Provides a web application built with React where users can select a stock ticker, view the latest prediction, understand the driving factors (positive/negative), read the AI-generated explanation, and browse historical prediction performance.
How we built it
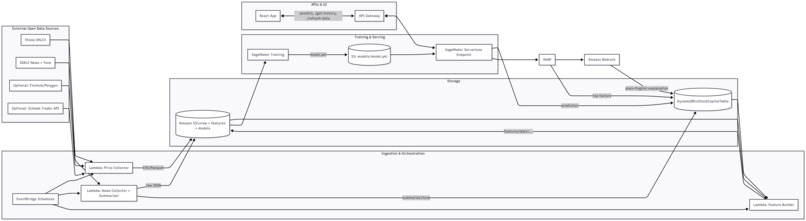
We designed an event-driven, serverless architecture primarily on AWS:
Data Layer:
- S3: Stores raw price (.csv) and news (.json) data, partitioned by date, as well as curated feature files (.csv) and model artifacts (.tar.gz containing .pkl or xgboost-model)
- DynamoDB: Stores structured summaries of daily news, prediction results, SHAP values, and Bedrock explanations, keyed by ticker_date and sorted by datatype.
Processing & ML Layer:
- Lambda (data_collector): Scheduled by EventBridge, fetches raw data using Python requests and uploads to S3/DynamoDB using boto3.
- SageMaker Processing (news_processor.py): Uses AWS Comprehend via boto3 to analyze sentiment in news titles stored in S3.
- Lambda (daily-feature-engineer.py): Triggered by S3 price uploads, uses Pandas/NumPy to read price history (S3) and news metrics (DynamoDB) to compute features, saving the result to curated S3.
- SageMaker Training (model.ipynb, final_model.py): Uses SageMaker SDK (XGBoost, HyperparameterTuner) to train and tune an XGBoost model on features from S3.
- SageMaker Serverless Inference (sagemaker-serverless.ipynb, inference.py): Deploys the trained model artifact from S3 to a serverless endpoint. The inference.py script defines how to load the model and process prediction requests.
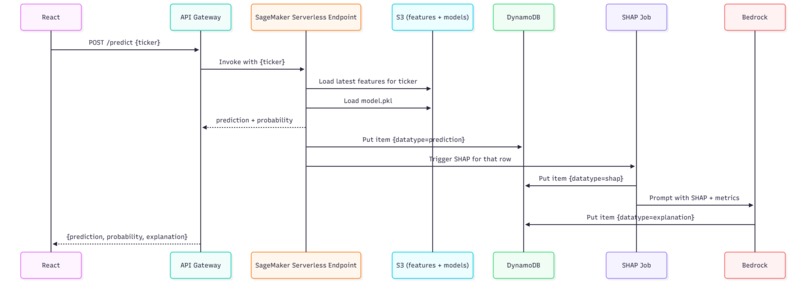
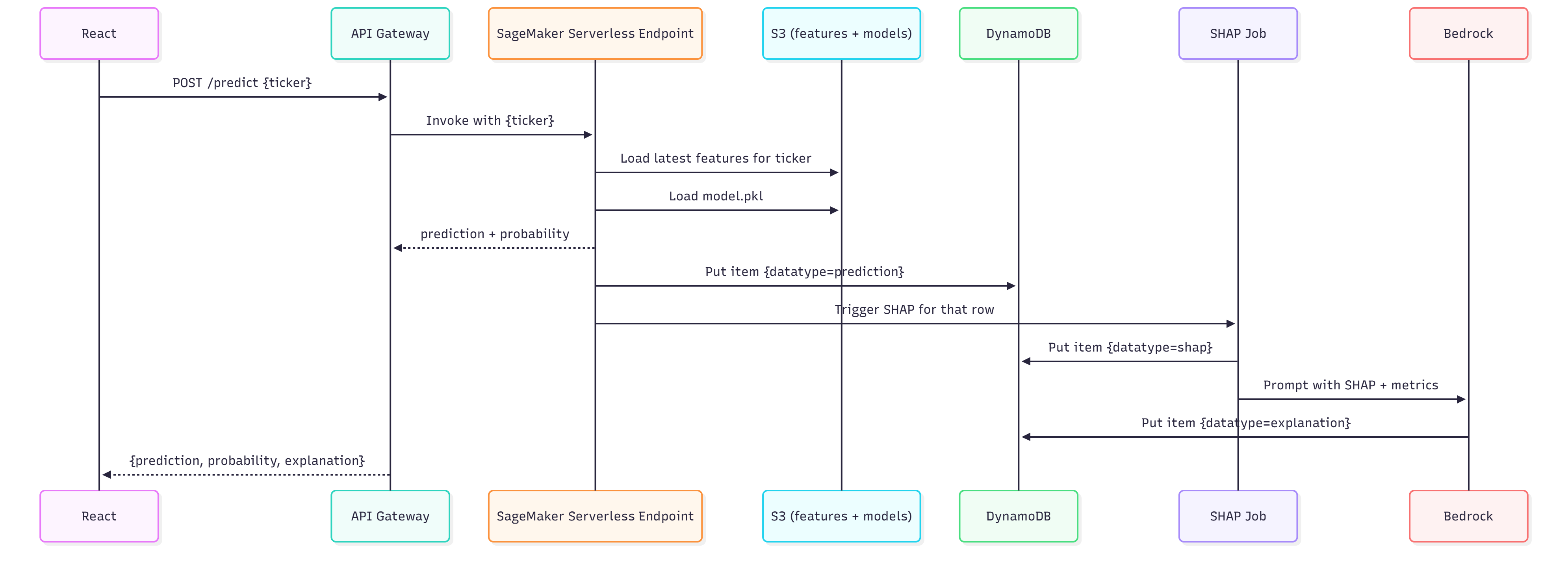
- Lambda (shap_explainer): Packaged using Docker. Triggered by DynamoDB streams (on 'prediction' item creation), it loads the model and feature data to compute SHAP values and saves them back to DynamoDB with datatype='shap'.
- Lambda (explain-with-bedrock): Triggered by DynamoDB streams (on 'shap' item creation), it fetches the corresponding prediction metrics, builds a prompt combining SHAP results and metrics, invokes Amazon Bedrock (using amazon.nova-lite-v1:0 or amazon.titan-text-premier-v1:0) via boto3, and saves the generated explanation text to DynamoDB with datatype='explanation'.
API & Frontend Layer:
- API Gateway: Exposes REST endpoints (/predict/{ticker}, /get-history/{ticker}).
- Lambda (inference-caller.py): Handles /predict requests. Fetches features, calls SageMaker, saves the prediction (triggering SHAP and Bedrock Lambdas via DDB stream), waits briefly, queries DDB for SHAP/explanation, and returns the combined response.
- Lambda (get-history): Handles /get-history requests by querying DynamoDB for past 'prediction' items.
- React Frontend: Built using Vite, TypeScript, Tailwind CSS. Uses custom hooks and fetch to interact with API Gateway, manage state, and display data/explanations. Tested with Vitest/React Testing Library. Deployed via AWS Amplify.
Challenges we ran into
- Lambda Packaging: Managing large Python dependencies (SHAP, XGBoost, Pandas, NumPy) required using Docker container images for Lambdas like the shap_explainer, exceeding the standard zip limits. Ensuring specific versions (e.g., numpy==1.26.4) was necessary for compatibility.
- Model Loading: The inference code needed flexibility to load models saved either by SageMaker Training (xgboost-model in tar.gz) or potentially via joblib/pickle (.pkl).
- Asynchronous Coordination: The end-to-end process (prediction -> SHAP -> Bedrock explanation) relies on DynamoDB Streams. To present the full result via the initial API call, the inference-caller Lambda implements a wait-and-poll strategy, pausing briefly before querying DynamoDB for the downstream results. Handling potential delays or failures in this chain required retry logic.
- Data Handling: Robustly handling various data formats (CSV from Stooq, JSON from GDELT, potential list format in news files), missing data, and type conversions (especially Decimal from DynamoDB for Bedrock prompt) required careful data processing logic.
- Grounded Explanations: Delivering grounded, non-hallucinated explanations from Bedrock required careful prompting. Our approach involved using structured SHAP/metrics JSON as the sole context, implementing a strict system prompt forbidding financial advice, setting low temperature and token limits, and utilizing the Nova Converse model. Safeguards include a deterministic SHAP-only fallback, numeric sanitization, and DDB-audited inputs/outputs.
Accomplishments that we're proud of
- Building a fully serverless architecture integrating data ingestion, processing, ML inference, and explanation generation on AWS.
- Successfully implementing and orchestrating multiple AWS AI/ML services: SageMaker, Comprehend, and Bedrock.
- Integrating SHAP for model explainability within a serverless Lambda (using Docker).
- Utilizing Amazon Bedrock to generate user-friendly, natural language explanations from SHAP outputs.
- Creating a responsive React frontend with clear data presentation and state management.
- Leveraging publicly available datasets (Stooq, GDELT) for a cost-effective solution.
What we learned
- Building event-driven workflows using AWS Lambda, S3 Events, EventBridge, and DynamoDB Streams.
- Managing dependencies and deployment complexities for Python ML libraries in AWS Lambda via Docker.
- Integrating and prompting Amazon Bedrock models (amazon.nova-lite, amazon.titan-text-premier) for specific text generation tasks.
- Training, tuning, deploying, and invoking SageMaker models, especially using Serverless Inference.
- Combining technical indicators and news sentiment for feature engineering in a financial context.
- Practical implementation of SHAP for explaining XGBoost model predictions.
- Developing and testing React applications with TypeScript, Vite, and associated tooling.
What's next for Explainable AI Trading Copilot
- Infrastructure as Code (IaC): Formalize the AWS setup using CDK or Terraform.
- CI/CD: Implement automated testing and deployment pipelines (e.g., GitHub Actions).
- Model Monitoring & Retraining: Add automated drift detection and retraining triggers.
- Enhanced Frontend: Incorporate charting, user settings, and potentially real-time features.
- Optimize History Query: Implement a GSI in DynamoDB for more efficient history retrieval.
- Explore More Bedrock Models/Features: Experiment with different Bedrock models or features like Agents for more complex interactions.
Built With
- amplify
- api
- boto3
- comprehend
- css
- docker
- dynamodb
- eventbridge
- gateway
- gdelt
- iam
- inference
- lambda
- library
- nova
- numpy
- pandas
- processing
- python
- react
- s3
- sagemaker
- scikit-learn
- serverless
- shap
- stooq
- tailwind
- testing
- training
- typescript
- vite
- vitest
- xgboost



Log in or sign up for Devpost to join the conversation.