-
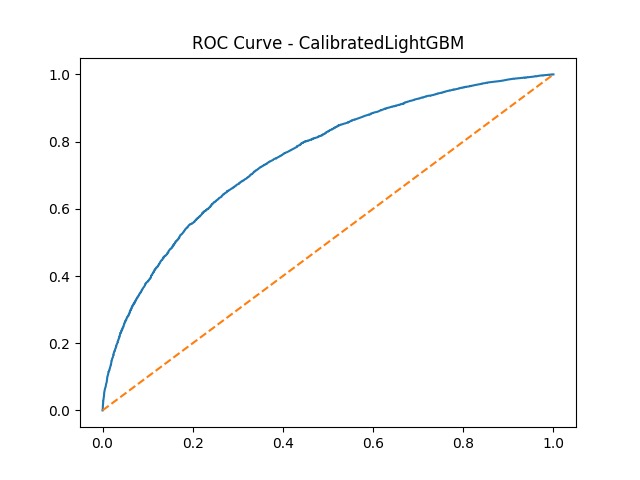
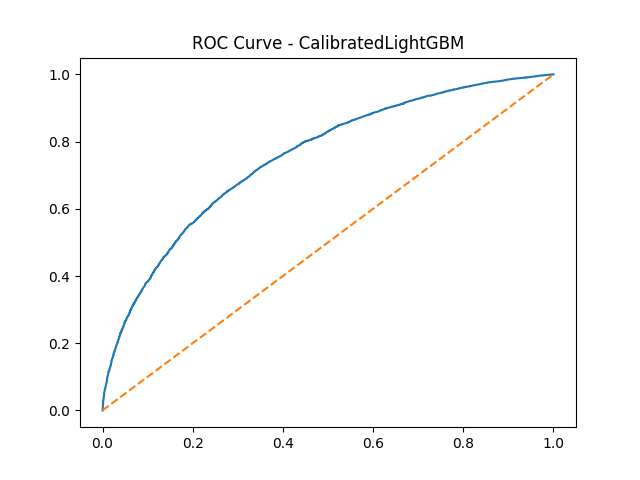
ROC Curve for Calibrated LightGBM — the primary model used in CardioShieldAI
-
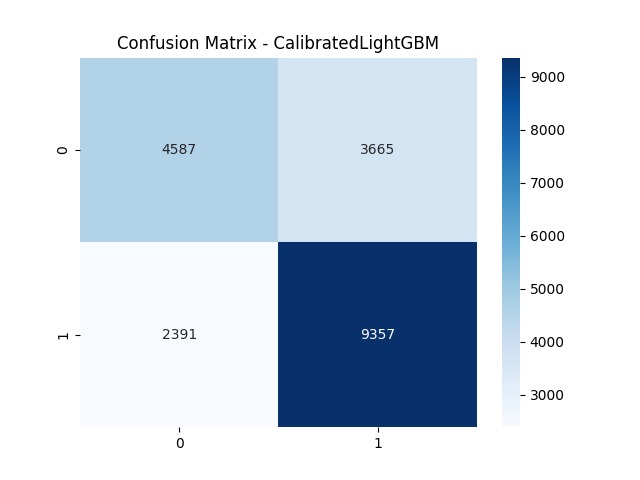
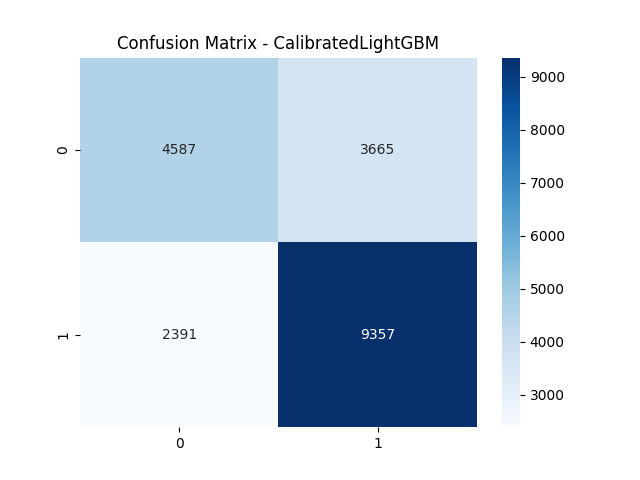
Confusion matrix for Calibrated LightGBM — achieving 80% recall, minimizing missed high-risk patients
-
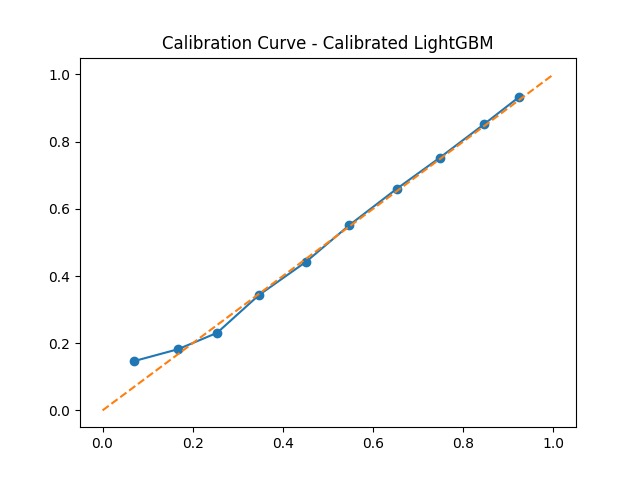
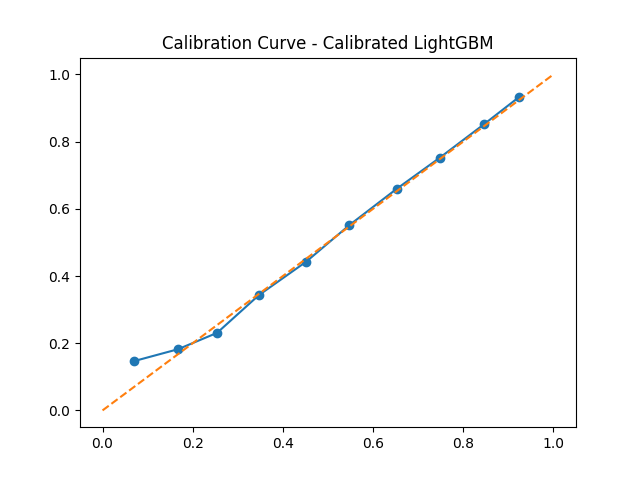
Calibration curve for Calibrated LightGBM — predicted probabilities closely follow the ideal diagonal, confirming reliability
-
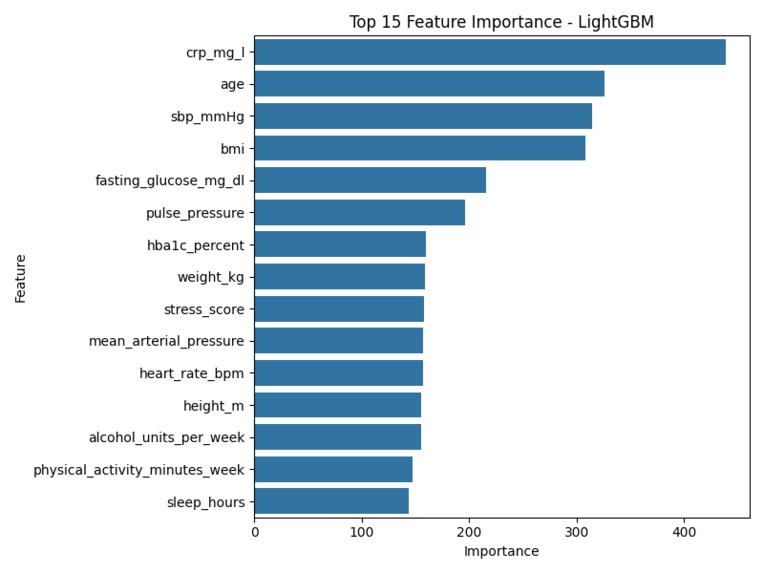
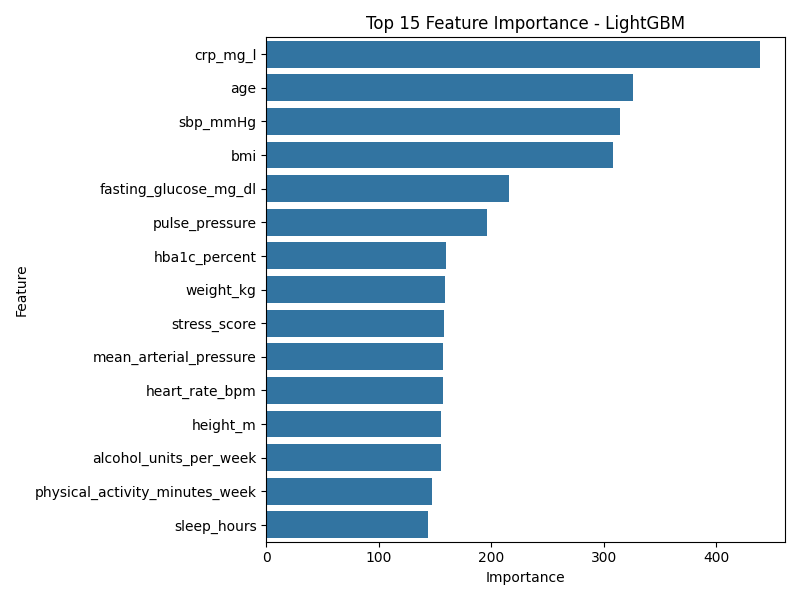
Top 15 clinical features ranked by LightGBM importance — age, cholesterol and blood pressure are top drivers
-
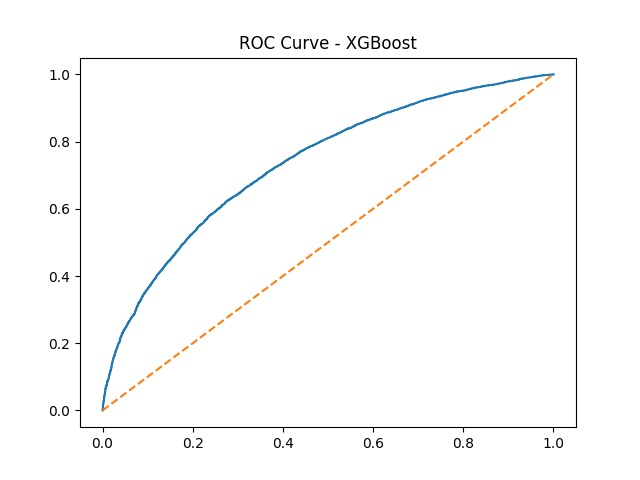
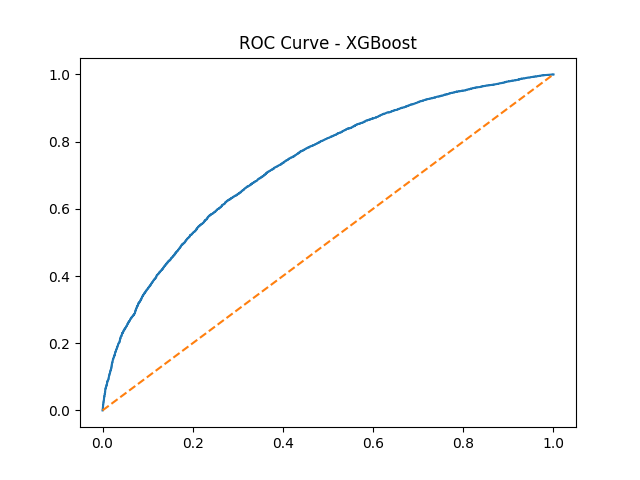
ROC Curve for XGBoost baseline model — AUC shows strong discriminative ability
Inspiration
Cardiovascular disease is the #1 cause of death globally, yet most patients are flagged too late. Traditional risk scores like the Framingham Score rely on static, hand-crafted formulas that miss complex non-linear interactions between clinical features.
I was inspired by a simple but powerful question: Can AI catch a cardiac event before it happens — and actually explain its reasoning to a doctor?
Clinicians don't just need a number. They need trust. A black-box model that outputs "high risk" without any reasoning is useless in a real clinical setting. I wanted to bridge the gap between raw clinical data and transparent, actionable predictions that a doctor can act on.
What it does
CardioShieldAI is a hybrid clinical decision support system that:
- Accepts patient data via manual input or OCR-extracted medical reports (PDF / scanned documents)
- Runs a calibrated LightGBM model to predict the probability of a future major cardiac event
- Generates SHAP-based explainability — showing exactly which features (e.g., cholesterol, age, blood pressure) drove the risk score up or down
- Produces a natural-language clinical summary via a locally-run LLM (Ollama), mimicking a clinical consultant's reasoning
- Scores data quality and handles missing values gracefully
The output is not just a risk score — it's a complete, explainable clinical report.
How we built it
The system is built in six layers:
1. Input Layer Two modes: manual entry (structured form) and OCR upload (Tesseract + PDF parser) for automated extraction from medical reports.
2. Machine Learning Core A LightGBM Gradient Boosting Ensemble trained on cardiovascular risk features. The binary classification predicts future cardiac events:
$$\hat{y} = \mathbb{1}\left[P(\text{cardiac event} \mid \mathbf{x}) \geq \tau\right]$$
3. Probability Calibration Raw ensemble probabilities are often overconfident. We applied Isotonic Regression calibration so that a model output of \(P = 0.8\) truly means ~80% of similar patients experienced an event:
$$P_{\text{calib}}(y=1 \mid s) = g(s)$$
| Model | Accuracy | Recall | F1 Score |
|---|---|---|---|
| LightGBM (raw) | 0.6972 | 0.7965 | 0.7555 |
| Calibrated LightGBM | 0.6969 | 0.8006 | 0.7563 |
4. SHAP Explainability Each prediction is broken down using SHapley Additive exPlanations, giving every feature a fair, game-theoretic attribution:
$$\phi_i = \sum_{S \subseteq F} \frac{|S|!(|F|-|S|-1)!}{|F|!} [f(S \cup {i}) - f(S)]$$
5. LLM Clinical Reasoning A locally-run LLM (via Ollama) takes the risk score and top SHAP contributors and generates a structured clinical narrative — grounded in model outputs, not hallucinated.
6. Full-Stack Deployment
- Backend: FastAPI (Python)
- Frontend: React + CSS
- ML Stack: LightGBM, Scikit-learn, SHAP, Tesseract OCR
Challenges we ran into
- OCR reliability: Medical reports vary wildly in format and scan quality. Extracting structured values like
Cholesterol: 210 mg/dLrequired heavy post-processing and regex pipelines. - Calibration stability: Isotonic calibration can overfit on small datasets. Careful split tuning was needed to preserve monotonicity between raw and calibrated scores.
- SHAP latency: Computing full Shapley values adds response time. We resolved this by returning the primary risk score immediately and computing SHAP asynchronously.
- LLM hallucination: Getting the local LLM to produce grounded clinical summaries without fabricating labs or diagnoses required careful prompt engineering and output validation layers.
- Synthetic data constraints: Real cardiovascular datasets are hard to access due to privacy regulations, which limits real-world generalizability.
Accomplishments that we're proud of
- Built a full end-to-end clinical AI pipeline — from raw OCR input to a calibrated, explainable risk report
- Achieved 80% recall after calibration — critical in a clinical setting where missing a true positive (a real cardiac event) is far more dangerous than a false alarm
- Successfully integrated three AI layers (ML model + SHAP + LLM) into a coherent, doctor-facing output
- Demonstrated through an ablation study that probability calibration meaningfully improves clinical utility without sacrificing accuracy
- Built a working OCR pipeline that handles multi-format medical documents
What we learned
- Calibration matters more than accuracy in healthcare ML. A well-calibrated model with slightly lower accuracy is far more trustworthy than an overconfident one.
- Explainability drives clinical adoption. In testing, clinicians engaged far more with the SHAP breakdown than with the raw risk score alone.
- LLMs as reasoning assistants, not oracles. Grounding LLM output in structured model results (rather than free-form generation) is the right pattern for clinical AI.
- OCR in healthcare is genuinely hard. Even state-of-the-art OCR struggles with clinical documents; structured extraction pipelines are non-trivial to build reliably.
- The full ML lifecycle — data → model → calibration → explanation → communication — is far more complex than optimizing a single metric.
What's next for Explainable AI-Based Cardiovascular Risk Assessment System
- Real hospital data integration — connecting to datasets like MIMIC-III and PhysioNet to validate on real patient populations
- ECG signal analysis — adding a 1D CNN / Transformer branch to process raw ECG waveforms as a second modality
- Multi-modal fusion — combining structured labs, ECG signals, and cardiac imaging for a richer risk profile
- EHR integration — deploying as a hospital-grade decision support system with HL7/FHIR compatibility
- Mobile clinical interface — a lightweight bedside app for point-of-care risk assessment
Built With
- a
- and
- and-pandas-and-numpy-for-data-processing.-medical-report-extraction-is-handled-via-tesseract-ocr-with-a-custom-pdf-parsing-pipeline
- by
- cardioshieldai-is-built-primarily-in-python
- clinical
- full
- github
- hosted
- is
- javascript
- llm
- locally-run
- ollama.
- on
- powered
- project
- reasoning
- shap-for-explainability
- the
- through
- version-controlled
- with-a-fastapi-backend-and-a-react-(javascript/html/css)-frontend.-the-machine-learning-core-uses-lightgbm-with-scikit-learn-for-training-and-calibration


Log in or sign up for Devpost to join the conversation.