Inspiration
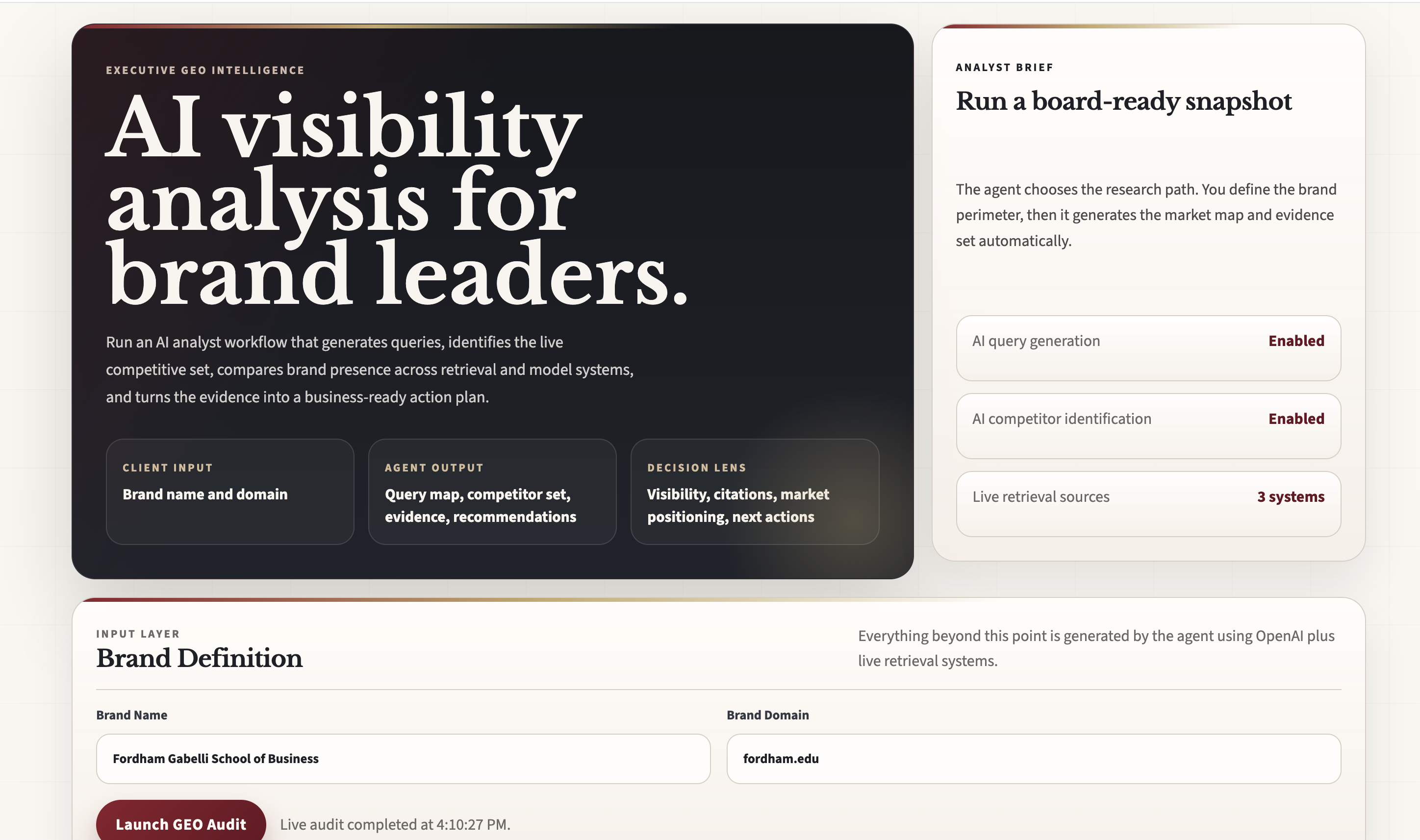
AI answers are becoming the new decision surface for brands. For a school like Fordham Gabelli, it is no longer enough to rank in search results; the real question is whether the brand appears, gets cited, and is positioned well inside synthesized AI responses. We built Executive GEO Intelligence Agent to make that visible and actionable for business users.
What it does
Executive GEO Intelligence Agent audits a brand’s visibility in AI-driven discovery. A user enters only a brand name and domain, and the agent:
- generates high-intent queries with OpenAI
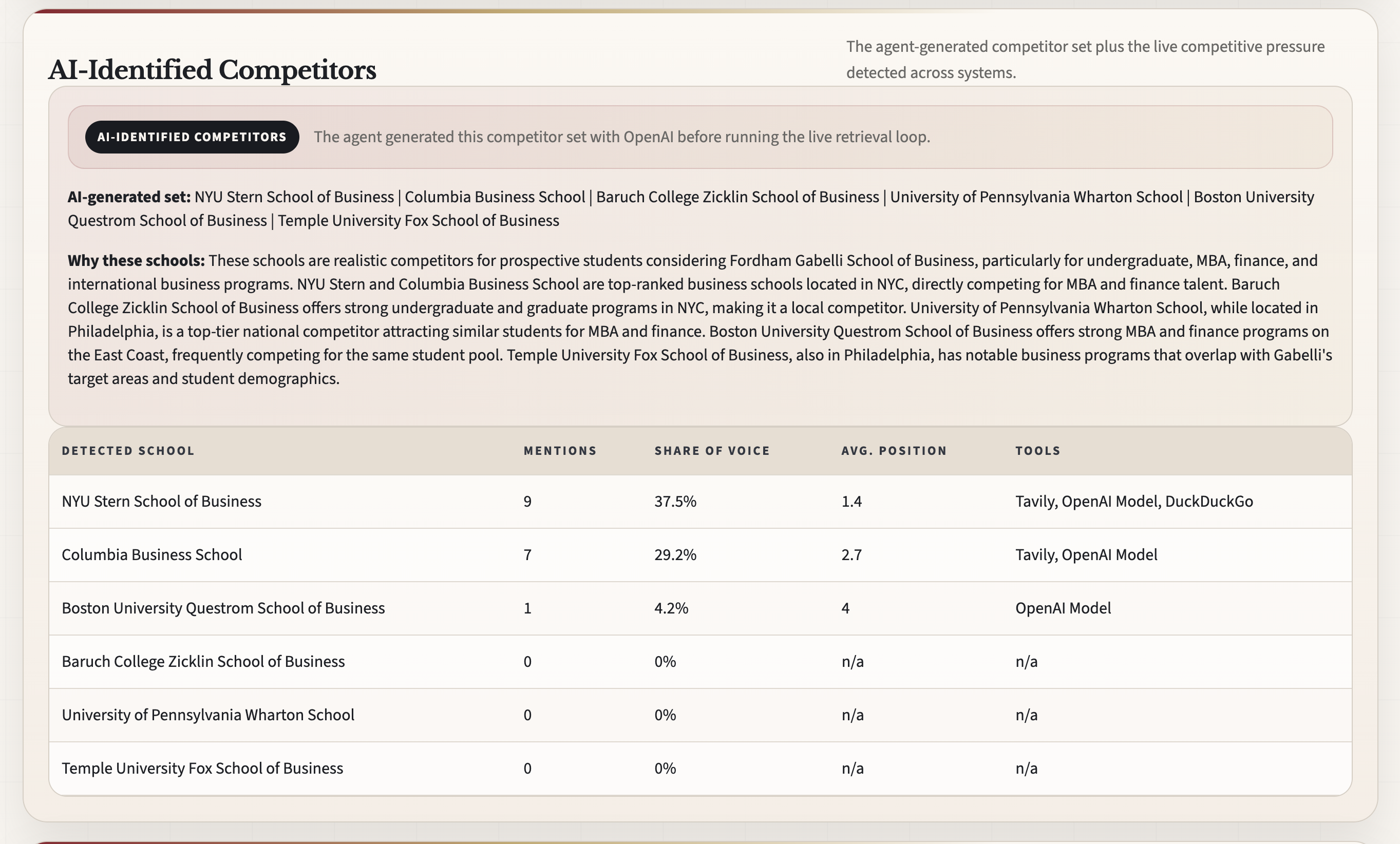
- identifies a relevant competitor set with OpenAI
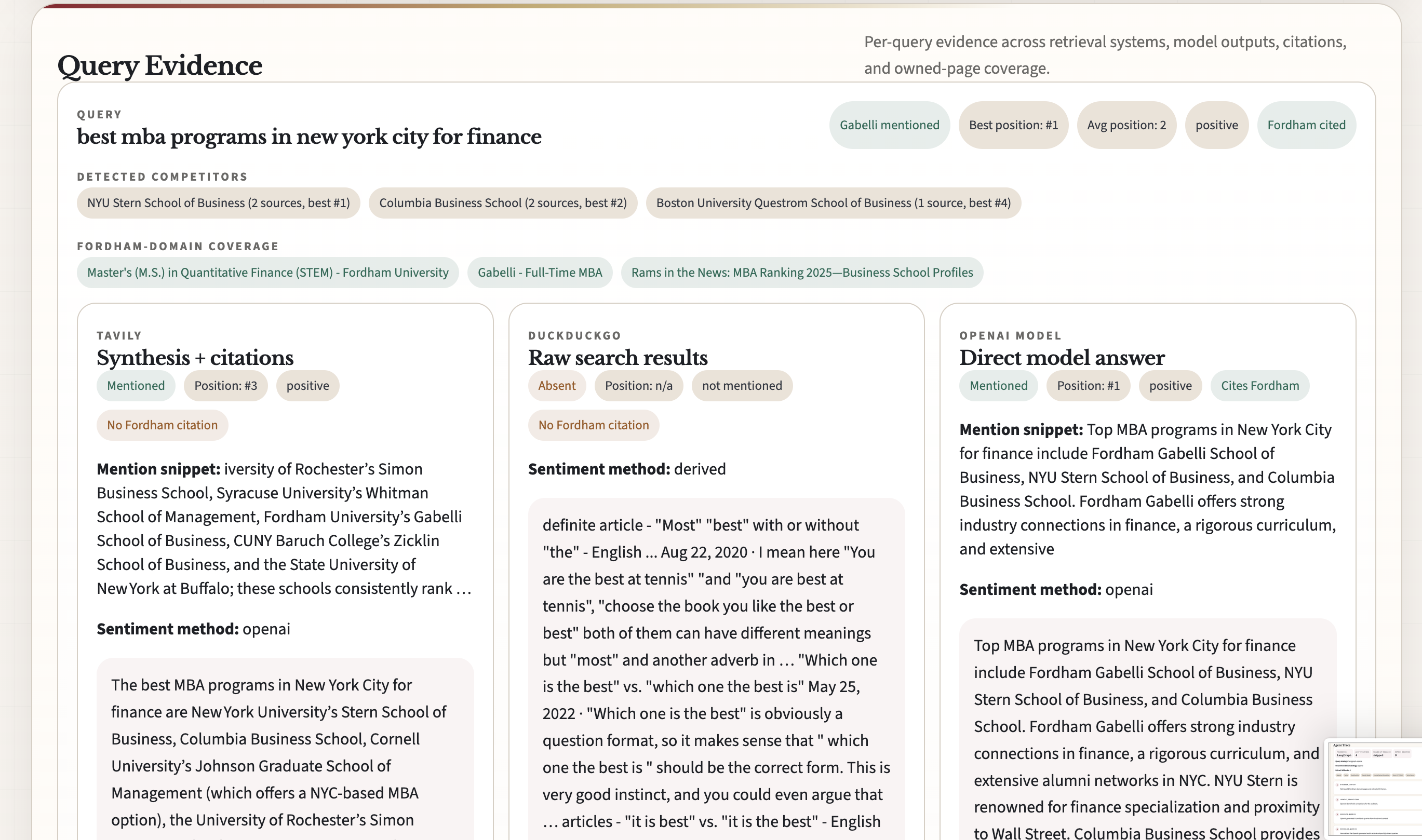
- runs live retrieval across Tavily, DuckDuckGo, and an OpenAI model layer
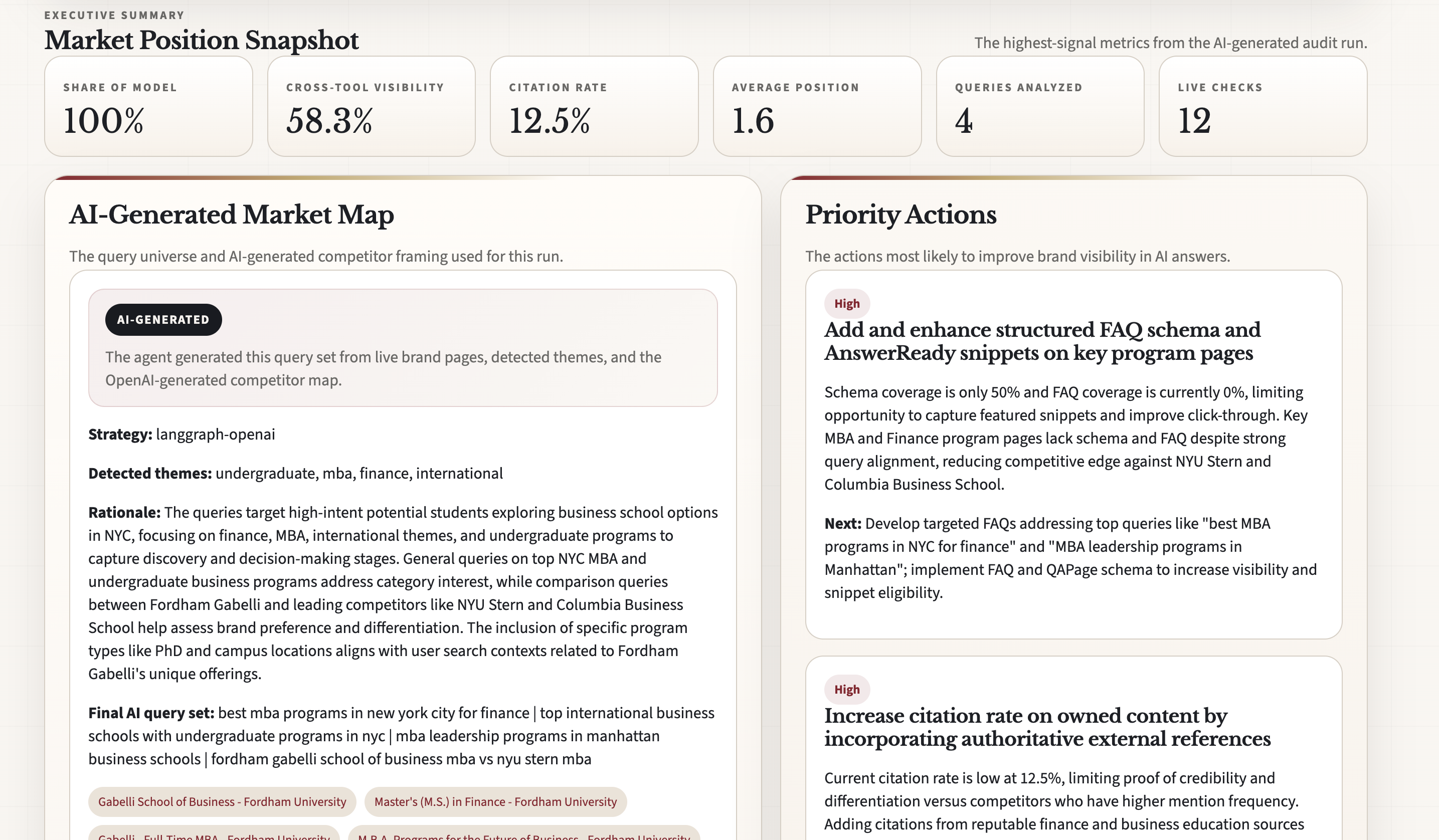
- measures core GEO signals like Share of Model, mention position, citation presence, competitor share of voice, and sentiment
- produces a structured action plan
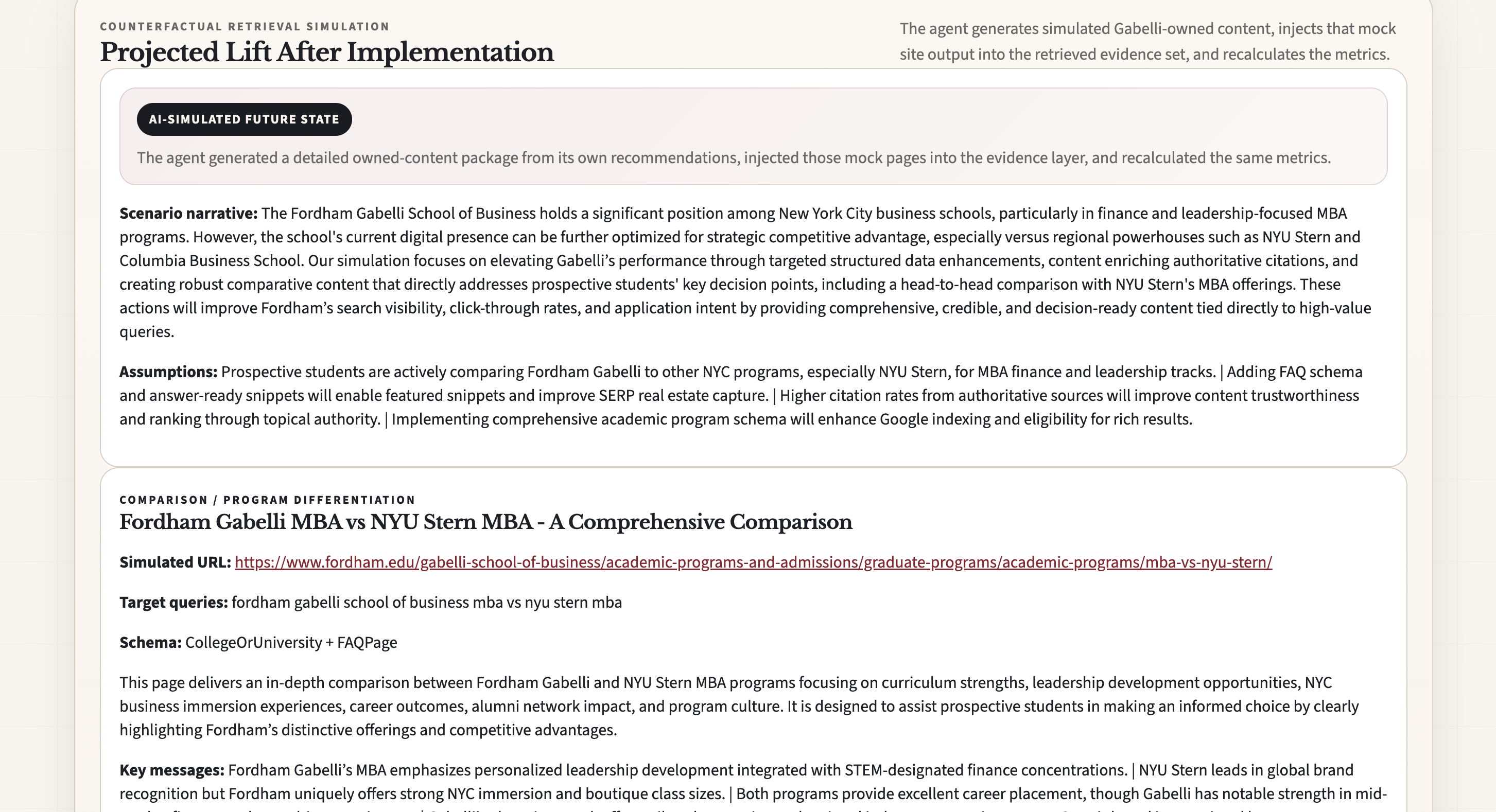
- simulates a counterfactual future state by generating mock brand-owned content and injecting it into the evidence layer to show how better GEO content could improve outcomes
How we built it
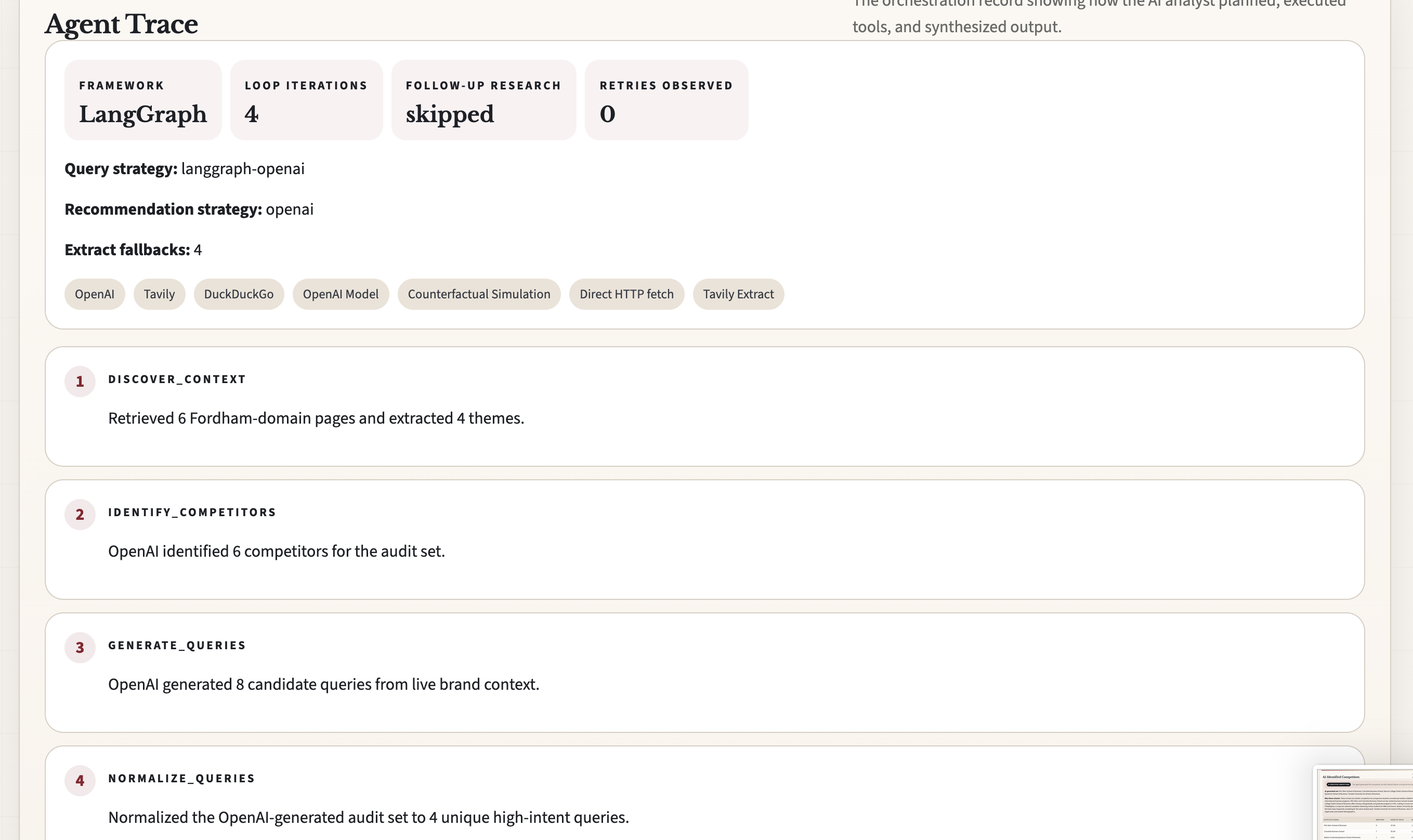
We built the system as an agentic workflow around LangGraph in Python, with OpenAI handling reasoning-heavy steps like competitor identification, query generation, sentiment analysis, recommendation synthesis, and counterfactual simulation. Tavily and DuckDuckGo provide live retrieval evidence, while a lightweight frontend presents the results in a business-oriented dashboard. We also refactored the stack into a Vercel-friendly deployment path using a Python API function and static frontend assets.
Challenges we ran into
The biggest challenge was making the system truly agentic while still keeping it demo-safe and deployment-ready. We had to remove static fallback logic, correct metric calculations to match the repo’s GEO tips, fix competitor extraction when the model returned domains instead of institution names, and redesign the counterfactual simulation so it reflected injected mock content rather than pretending the public web had changed. Deployment also forced tradeoffs because the original local architecture relied on long-running state and live trace polling.
Accomplishments that we're proud of
We’re proud that the product feels like an actual executive intelligence tool rather than a one-off script. The agent dynamically decides queries and competitors, loops over live tools, aggregates findings into business-facing metrics, and generates structured recommendations and simulated future content. We also pushed the UI into a more polished finance-and-strategy style and got the system deployed publicly on Vercel.
What we learned
We learned that GEO is not just “ask an LLM and summarize.” The hard part is defining defensible metrics, keeping evidence grounded in live retrieval, and building agent behavior that can explain why a brand is or is not showing up. We also learned that deployment constraints shape product design: a workflow that works locally may need major simplification to run reliably on serverless infrastructure.
What's next for Executive GEO Intelligence Agent
Next, we would make the system more robust and longitudinal:
- add persistent run history so brands can monitor GEO performance over time
- compare more AI systems directly, including Perplexity or Gemini
- improve competitor and sentiment extraction with stricter structured evaluation
- make counterfactual simulation more realistic by modeling citation and retrieval weighting more explicitly
- add exportable executive reports and benchmarking across brands or segments
Built With
- langgraph


Log in or sign up for Devpost to join the conversation.