-
-

Our logo
-

Welcome Screen
-
Call Screen
-
Dark Mode
-
Light Mode
-
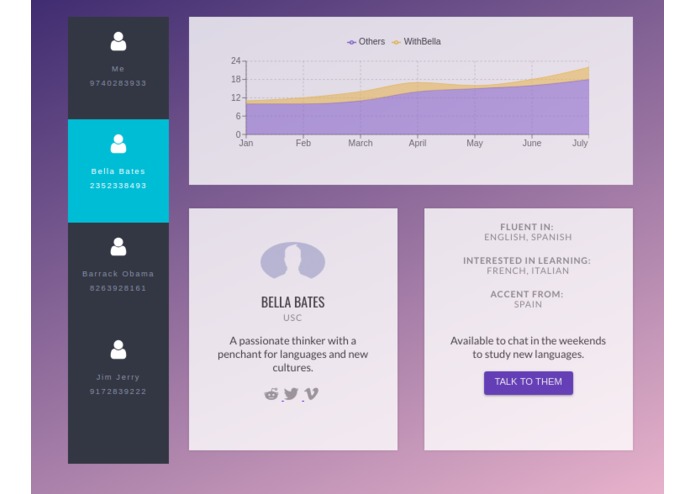
Contact Section
-
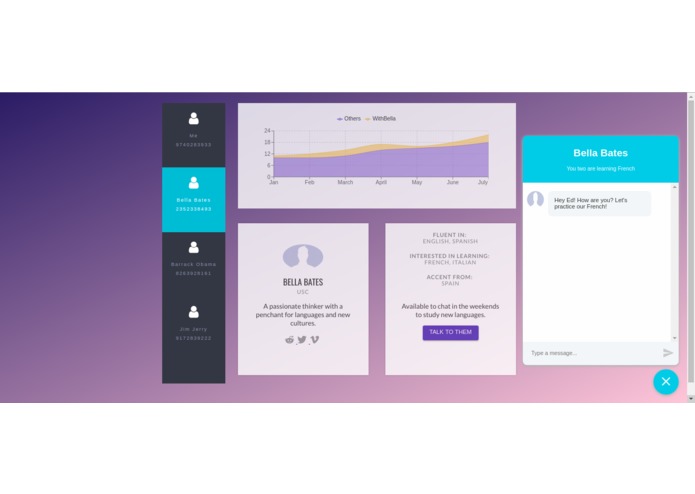
Complete Contact Page with the analytics and chat features


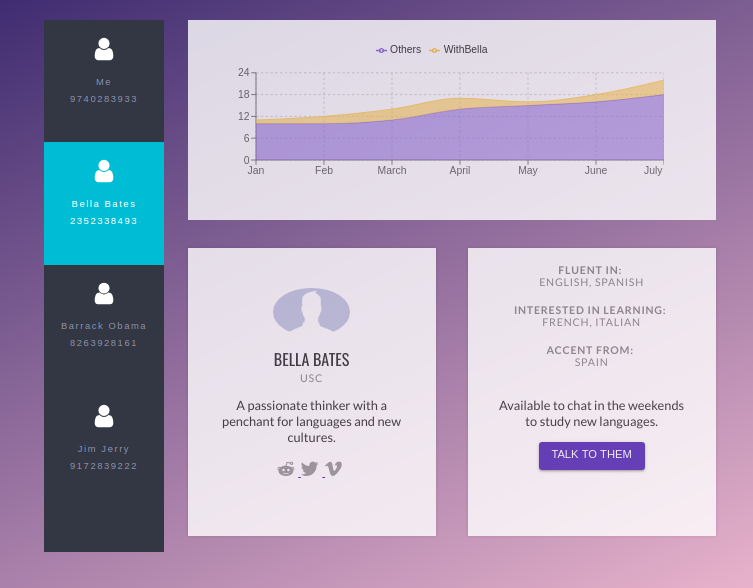
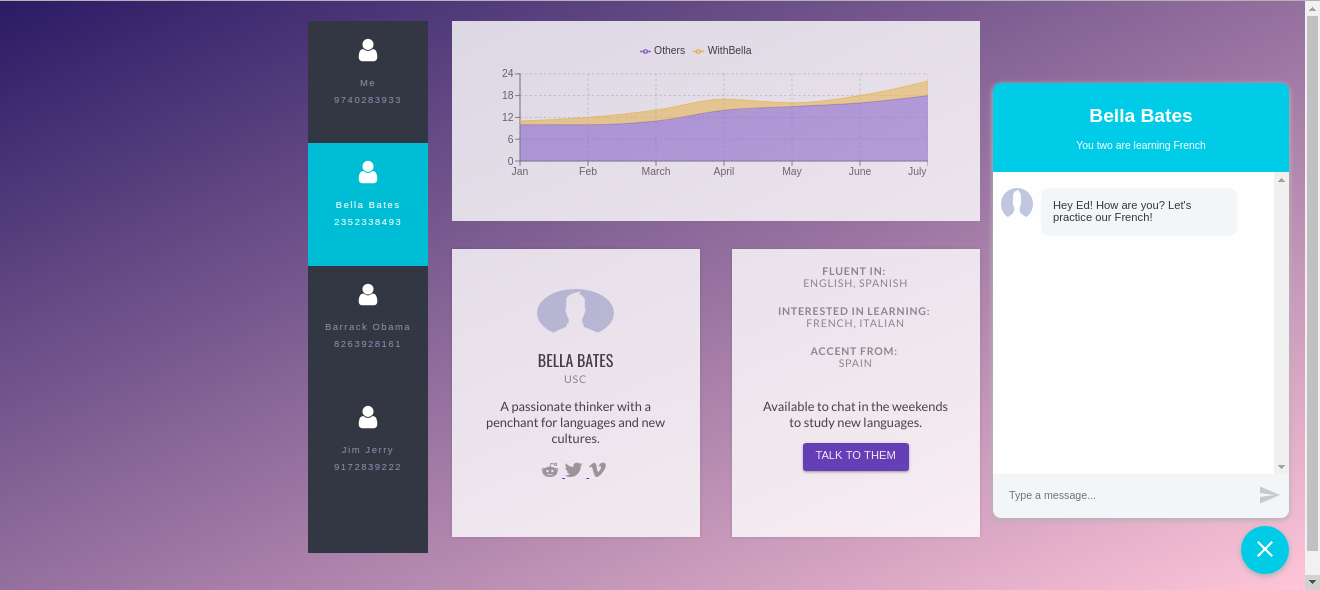
Inspiration
It's surprising see many different versions of a single language. The Americans, the English,the British, the Chinese, the Australians, etc have their accent. We all have faced difficulty in understanding the foreign versions of English which limits our capability to socialize and interact effectively with people of different cultures and backgrounds than us. We, especially being International students have faced this problem in our day-to-day life and it can get both embarrassing and frustrating.
We want to bridge this gap by eliminating this barrier altogether so that we can understand others and express ourselves better. With "To-may-to To-mah-to" we hope to solve this problem make us more confident and comfortable.
This applications' title was inspired by this classic song.
What it does
Our application takes an accented audio as input, runs our accent-conversion algorithm and produces the desired accent as output so that we can understand the other person better. Our product currently supports Voice and Video Calls.
How we built it
Front End:
We used ReactJS for the front end.The dashboard was designed with with p5.js and JQuery was used to make the animations.We deployed the website using AWS Amplify. Real-time communication was established using Pusher Channels.
Back End:
We used Google's Speech to Text and Text to Speech API to map accents. We used LSTM to do perform Speech to Speech mapping. Google Speech APIs provided us with information about the timestamp for each word in the audio. This helped us to determine the duration and the location of pauses in speech, and the speaking rate to generate a Speech Synthesis Markup Language(SSML) file. The SSML file was converted to the target accented speech.
We then synced the target audio and the video and sent it back to be displayed.
Challenges we ran into
We had a difficult time converting vanilla javascipt to react native.Retaining the same voice when we do the accent transformation is one of our biggest challenges. We currently use a different voice which does not provide the same experience as replicating the users voice. To solve this problem we would need to train our model on the user's voice. We could also prompt the users to create a vocal avatar using Lyrebird api.
We also had to make sure that we rendered the video so that it matches the accented voice.
Accomplishments that we're proud of
Despite the presence of so many challenges, we were able to create a working prototype of the application which successfully converts the accent into the desired accent and encourages people to have more inter-cultural interactions by removing one of the biggest barriers in communication.
What we learned
We learned a lot in terms of both technical and behavioral aspects.We started with learning how to use GCP's API to how to host our product on AWS. We then explored how to use ANN, MFCCs, and CNN to build a model for Automatic Speech to Speech Translation. Besides, learning a lot of technical stuff, we also learned a lot of other more important things like patience and never giving up.
What's next for To-may-to To-mah-to
We really want to enhance all the features of "To-may-to To-mah-to" to make it more accurate, user-friendly and easier to use.
We would love to give it the real-life touch so that the user feels comfortable using our product. We plan to do this by generating the target accent in the voice of the user, instead of any random voice.We could prompt the users to create a vocal avatar using Lyrebird api that could solve the issue of using a different voice when mapping the source speech to the target speech.
We also plan to render the video, especially the lip movements so that they are in perfect sync with the target audio file. Accent to accent translation should be made as close to real time as possible so that our users can use it with absolutely no problems. .









Log in or sign up for Devpost to join the conversation.