-

Landing Page
-

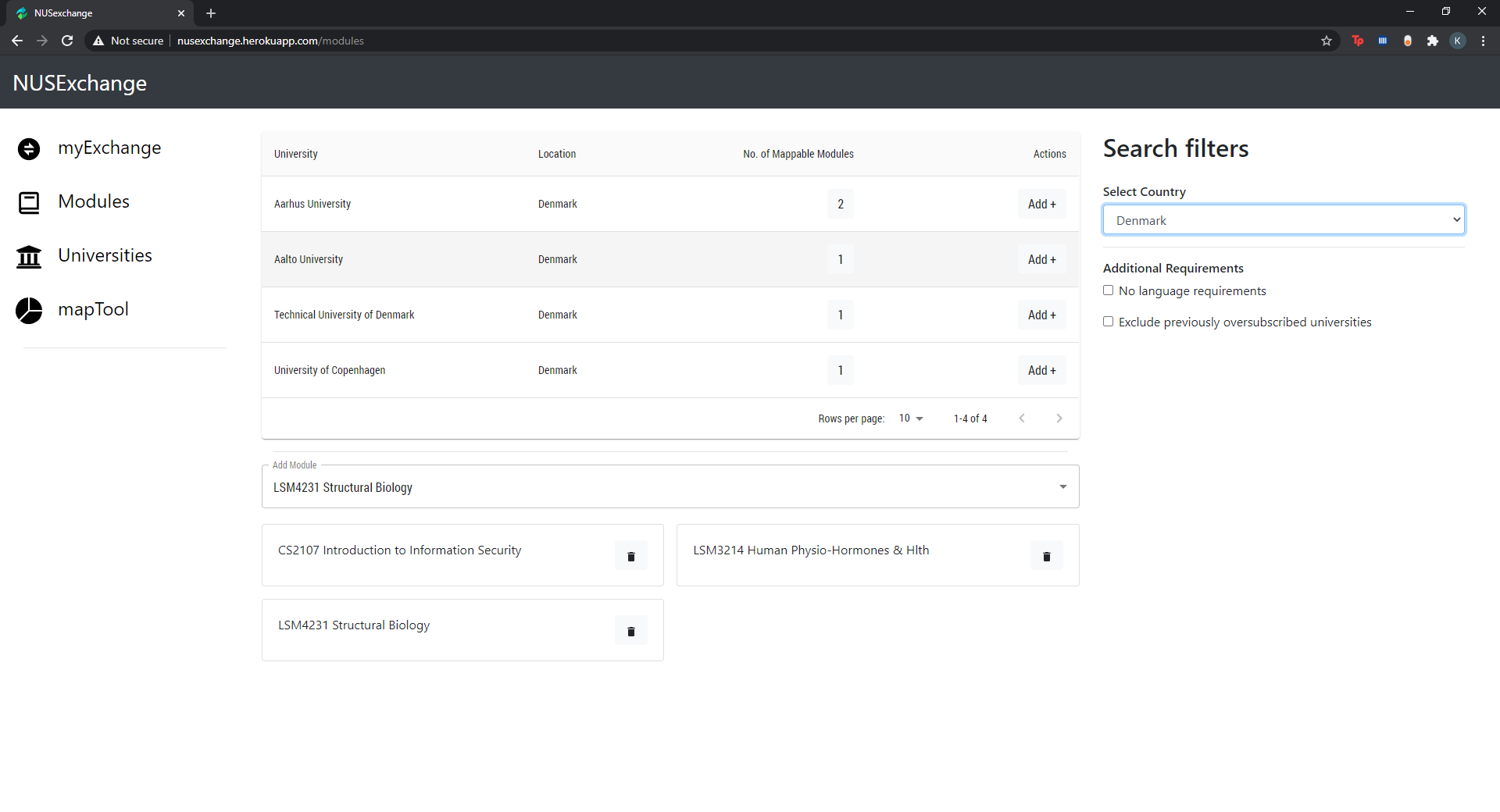
Module Selection
-

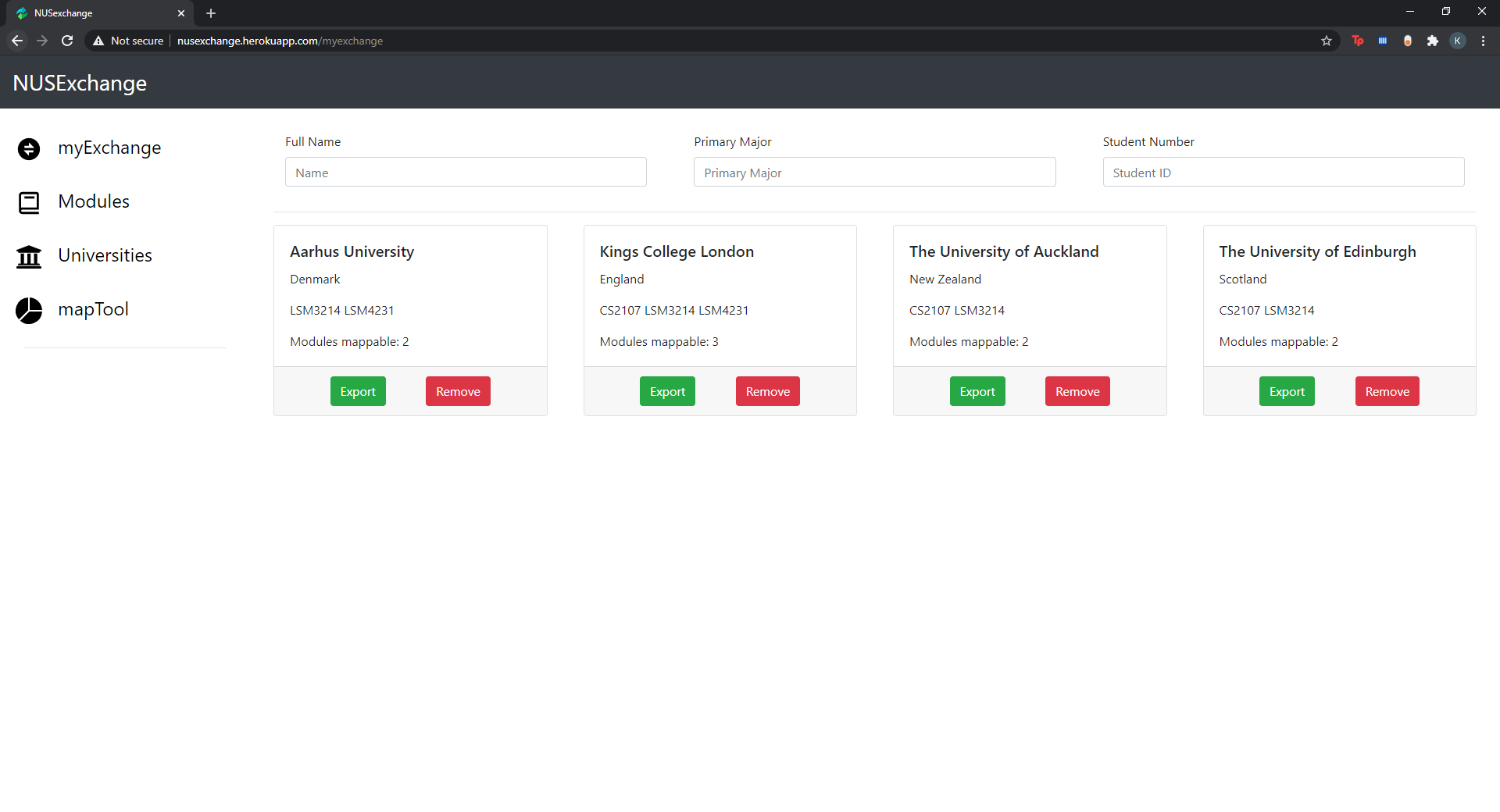
myExchange
-

mapTool


Inspiration
While we were applying for exchange, we realised that we spent hours just looking for information that could have been easily aggregated in the first place. Inefficient databases with horrible UI, a ton of modules that we might have missed out because they have not been previously mapped. The uncertainty of whether modules were mappable according to school requirements might jeopardise the plans and semester exchange that we worked hard for.
Furthermore, across different faculties, there are different procedures for submitting module mappings for exchange, we hope to be able to standardise and automate the module mapping process across faculties, giving it a more seamless experience to both the students and the staff handling mappings.
What it does
NUSexchange is a one-stop-shop for all your exchange application needs. Simply input the modules you wish to take on your semester exchange along with the destination you have in mind, and the web application will filter through all the possible partner universities offering those classes, ranking them for you according to the number of modules mappable for each partner university.
Our export tool automatically creates an initial study plan form with all the required details filled out. This saves the trouble of having to painstakingly cross-reference partner university modules with NUS modules.
For students wishing to map classes which have never been mapped before, the mapTool provides an estimation on the viability of the module being approved for mapping, using Natural Language Processing and Machine Learning. By vectorizing module descriptions of across various universities, we are then able to determine the topic of the module description in vector form. From there on, we calculate the distance between each module and determine the similarity of the your new module and the one available in the NUS.
How we built it
The web application can be split into client side and server side. The client side is build with ReactJS, HTML, CSS and Redux is used to facilitate the applications date-flow architecture. The client side communicates with the server side of our application that runs on NodeJS using the Express.js framework. To facilitate a speedy development, our client side relies on popular front-end frameworks like React-Bootstrap and Material UI. To keep the server side implementation light weight and to speed up development, instead of taking a more traditional approach of querying a database for information, we instead use a python script to query a JSON file that contains information about partner universities and the modules that they offer. The main engines of our Natural Language Processing mapTool and our PDF convertor live on the server side as well and are run with python scripts before the results are handed back to the client side.
For hosting, the server side is hosting on an AWS EC2 instance and our client side is hosted using Heroku.
Challenges we ran into
The data we needed to create the product was randomly placed across faculty websites and the data was not consistent across faculties. The availability and granularity of data varied across faculties so we had to figure out a way to aggregate the data in such a way that the information presented in the database was consistent.
State management of the front end application was tricky as well as we needed to ensure that information in the application was flowing properly and that components were being updated as necessary. Thankfully, Redux helped solve many of our problems.
Hosting remained our greatest challenge as we had very little experience with it. After multiple unsuccessful events, we finally managed to host our server side code on our AWS EC2 instance. We were unable to host our Client side on our AWS EC2 instance however and could only host the server side. In order to host our Client side code, we turned to Heroku. We then ran into our next problem where our Server side logic was only available at a http:// endpoint and so our browsers would block http calls from our Client side (https://) to our Server side. We were unable to get a https:// endpoint on AWS without a custom domain and hence opted to only use the http:// version of the Client side application.
Accomplishments that we're proud of
The team managed to learn incredibly fast even thought most did not have Web Development experience. Despite of the challenges we faced while trying to host, we rallied together and managed to find a solution to our problems and successfully deployed the application.
mapTool has a high accuracy across modules, we are fairly confident that with our tool created during Hack & Roll, it can be safely used for most, if not all, new module mappings.
What we learned
How we can use Redux for managing Client side data flow architecture.
Security features of browsers that prevent https:// endpoints from downloading data from http:// endpoints and preventing Cross Origin Resource Sharing as well.
Use of Python's nltk package to preprocess descriptions and compare modules across different universities.
What's next for NUSexchange
Work with NUS as a partner to automate retrieval of up-to-date information on partner universities' modules to keep the NUSexchange relevant year on year. Additionally, we would like to look into reviewing the university's manual module mapping approval process by automating and improving it. With Natural Language Processing, we hope to be able to approve modules mappings in large volumes based on topic modelling of the course content or descriptions. We would also like to be able to test the accuracy of our model on a larger scale by obtaining module mappings from a larger range of students across different faculties. We would likely need to work with NUS on this for insights into their current module mapping process in order to better tailor this.









Log in or sign up for Devpost to join the conversation.