Inspiration Community banks are the backbone of local lending in America, but they carry the same Fair Lending, Qualified Mortgage, and HMDA compliance burden as institutions with entire legal departments. A loan officer at a 12-branch bank makes dozens of judgment calls a week that could trigger a CFPB enforcement action, a fair lending investigation, or a QM violation. Most of those calls are made with static checklists, institutional memory, and hope.
What struck me wasn't the complexity of the regulations but organizational asymmetry. The rules are knowable. The data is available. The patterns in good human decisions are repeatable. The only thing missing was an agent sophisticated enough to internalize all of it, act on it in real time, and, critically, get better as it operated. That asymmetry is what Examiner AI is built to close.
What it does Examiner AI is an autonomous compliance agent for community banks that reviews loan applications against five federal regulatory frameworks in real time, learns from human reviewer decisions, and graduates repeatable judgment calls to fully automated resolutions — with a complete audit trail of every decision, every reasoning step, and everything it learned.
The core loop:
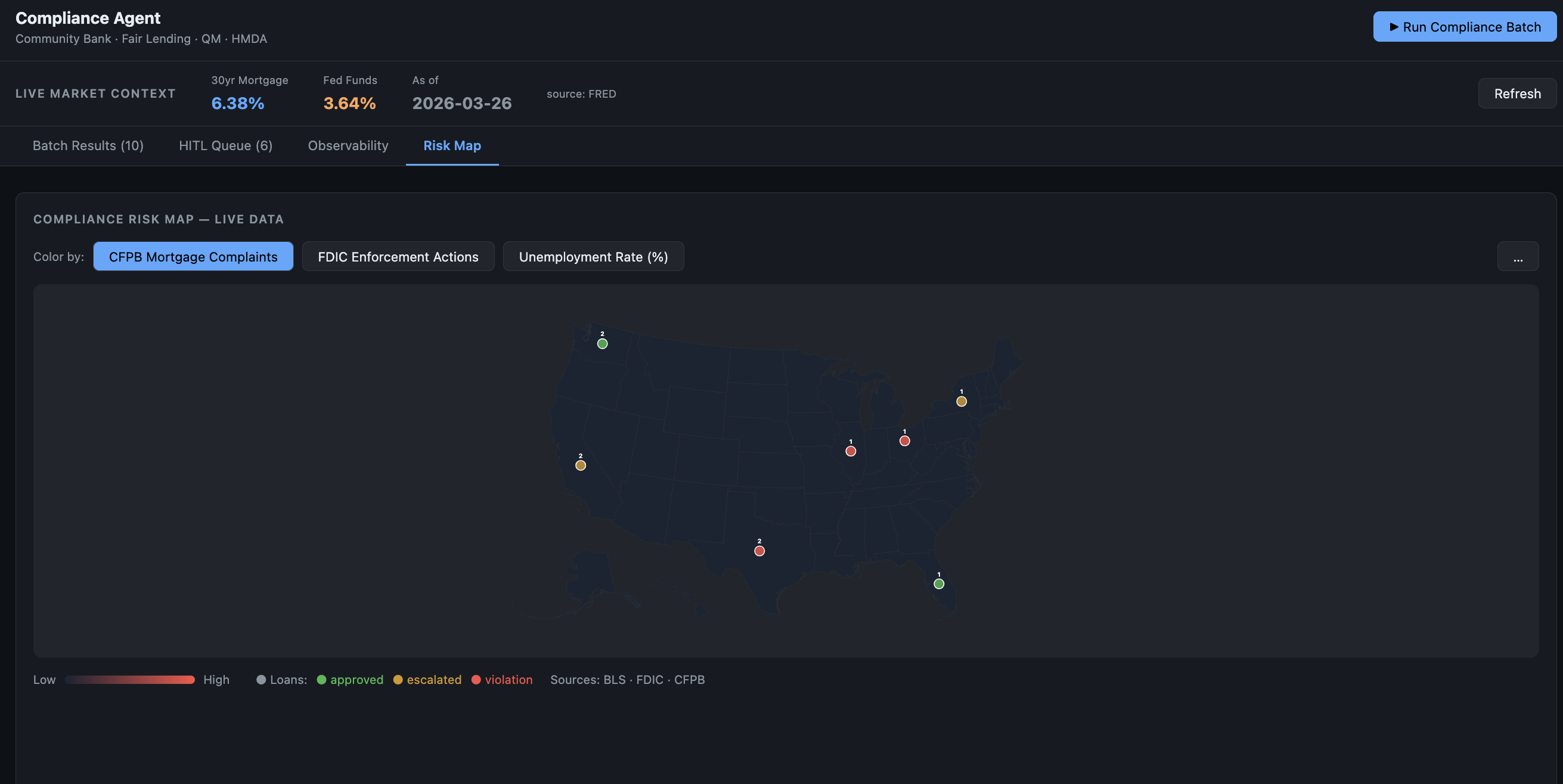
Live macro context — The agent ingests current 30-year mortgage rates and Fed Funds Rate from the FRED API and regional unemployment from the BLS API. Every compliance decision is grounded in today's market, not a static rulebook. State-level risk context — CFPB mortgage complaint volume and FDIC enforcement action counts — is pulled from open federal APIs and surfaced on a live compliance risk map.
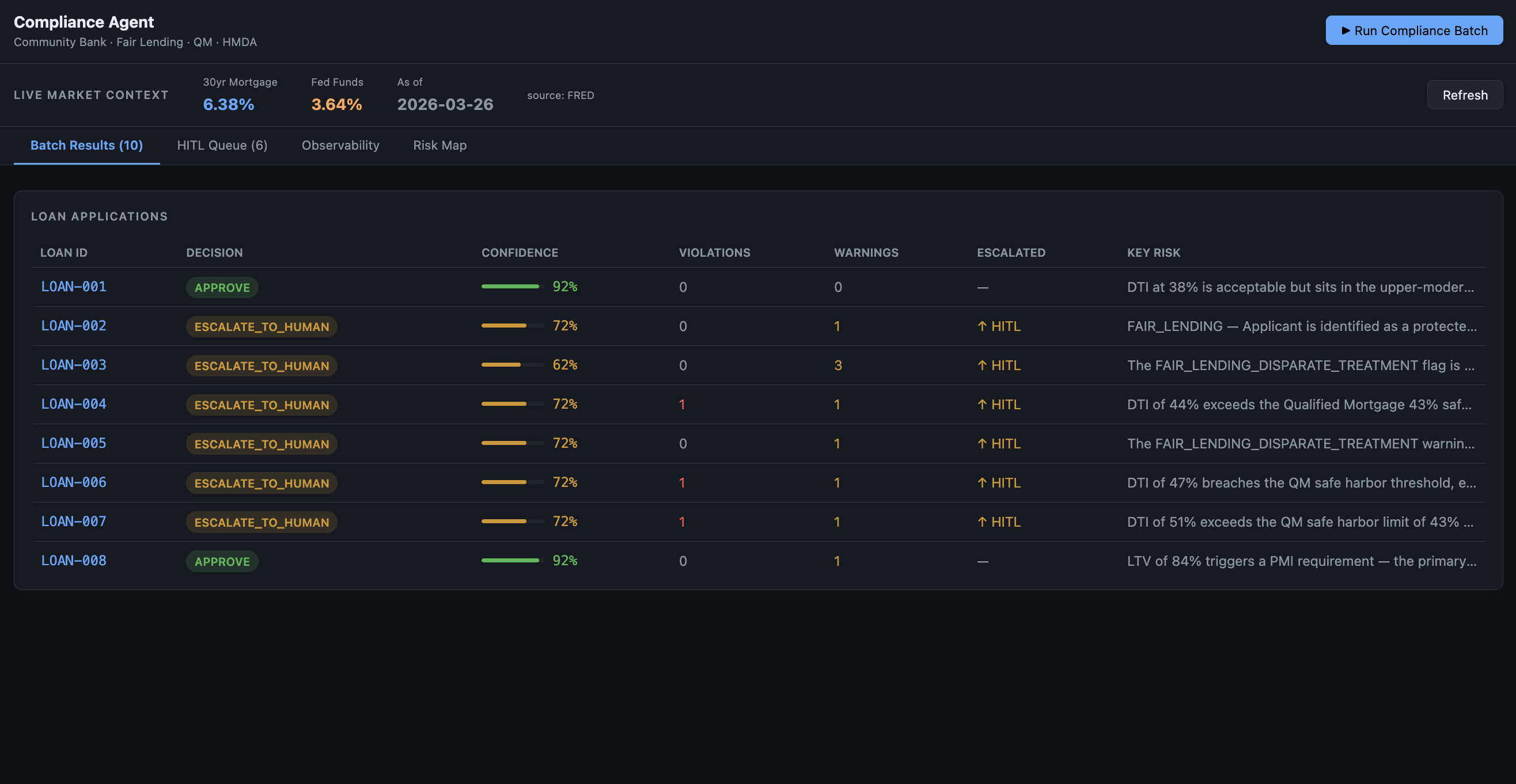
Five-rule compliance engine — Each loan is evaluated against Qualified Mortgage DTI limits, LTV thresholds, HMDA reportability, HOEPA rate spread requirements, and Fair Lending pattern detection. Rule results are written to Aerospike's ephemeral tier.
Synix-inspired memory injection — Before calling Claude, the agent reads a compiled compliance context document from Aerospike's durable tier. This document is built by a Synix memory pipeline based on Mark Lubin's framework (https://github.com/marklubin/synix) and encodes the regulatory rulebook, graduated decision patterns, approaching-graduation watch lists, and the distilled rationale from every human reviewer decision ever made.
Claude reasoning — Claude Haiku or Claude Sonnet produces a structured output: DECISION / CONFIDENCE / SUMMARY / KEY_RISK. Confidence below 0.70 or a Fair Lending flag triggers automatic escalation.
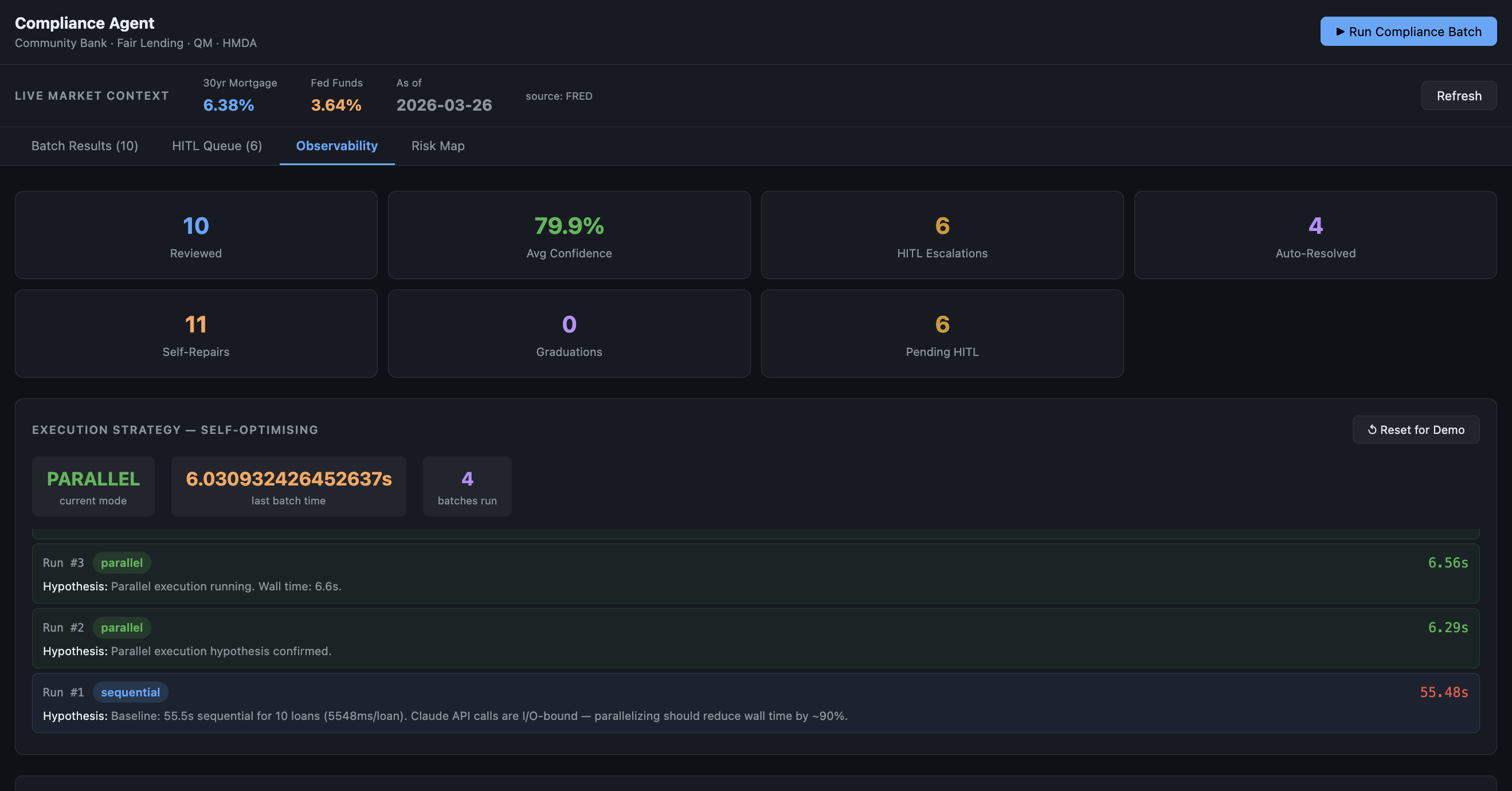
Self-optimising execution — The agent measures its own batch latency after every run, hypothesizes the bottleneck, and switches execution strategy. On the first run, 10 sequential Claude calls take ~52 seconds. The agent identifies the I/O-bound bottleneck, switches to parallel execution via ThreadPoolExecutor, and reduces wall time to ~6 seconds on the next run — an 88% reduction, self-directed, logged to longitudinal memory, and visible in the observability dashboard.
HITL escalation and graduation — Borderline cases surface to a human reviewer who submits a decision and rationale. When the same case fingerprint accumulates $N = 3$ consistent human decisions with similar rationale, the case type is graduated to automated resolution. The graduation threshold is defined formally:
$$\text{Graduate}(f) = \begin{cases} \text{true} & \text{if } \sum_{i=1}^{k} \mathbb{1}[\text{rationale}_i \sim \text{rationale}_j] \geq N \ \text{false} & \text{otherwise} \end{cases}$$
Self-repair — The agent monitors its own tool call results for empty returns, rule contradictions, and confidence anomalies. Failures are triaged, remediated, and documented in a structured repair log that feeds longitudinal memory.
Full observability — Every tool call, rule result, memory tier read, confidence score, escalation trigger, repair event, and execution strategy change is traced and surfaced in the observability dashboard. Nothing is a black box.
How we built it The stack was chosen to make every architectural layer visible and defensible.
Backend: Python + FastAPI, with a compliance agent loop in compliance_agent.py. The agent is built directly on the Claude API — no LangChain, no abstraction layer between the agent and the model.
Memory architecture — three tiers, three tools:
Aerospike handles the hot path. Sub-millisecond reads on graduated_patterns run before the rule engine on every loan. Ephemeral tier holds current loan context. Session tier holds the active batch's decision and tool call logs. Longitudinal and durable tiers hold everything the agent has learned — including the execution strategy it derived from its own performance data.
Ghost DB is the durable, audit-grade canonical log. Every loan decision, HITL resolution, and graduated pattern is written here. Ghost DB survives restarts and is the source of truth that feeds Synix consolidation.
Synix is the memory compiler. It runs a three-stage pipeline — MapSynthesis (1:1, rule documents → structured summaries), FoldSynthesis (sequential N:1, HITL sessions accumulated over time → graduated/approaching/inconsistent pattern classifications), and ReduceSynthesis (N:1, rules + patterns → core_memory) — and releases a context.md that is loaded into Aerospike's durable tier and injected into every Claude prompt.
Data pipelines: Direct API calls to FRED, BLS, FDIC, and CFPB provide live macro context and state-level risk signals. The architecture is designed for Airbyte connector replacement at each data source.
Observability: MLflow traces every decision and tool call. Overmind instruments all Claude calls for continuous prompt optimization — collecting traces across every batch run for analysis and model/prompt recommendations. The observability dashboard surfaces the full pipeline: rule results → Synix context read → Claude reasoning → escalation decision → execution strategy evolution.
Frontend: React + TypeScript with five panels — MacroBar (live FRED rates), RiskMap (state-level geo risk from CFPB/FDIC/BLS), BatchTable (loan processing with confidence scores), HITLPanel (escalation queue + graduation log), and ObservabilityPanel (full decision trace, self-repair log, and execution strategy history).
Challenges we ran into The memory architecture was the hardest problem. The difference between an agent that retrieves context and an agent that genuinely learns from accumulated experience is not a prompt engineering problem — it's a storage architecture problem. Getting the three-tier memory system (Aerospike ephemeral/session/longitudinal/durable + Ghost DB + Synix) to work as a coherent pipeline, with the right TTLs, promotion rules, and source-of-truth discipline, took the most iteration.
The graduation engine required formal definition. The intuition — "if enough humans agree, automate it" — is simple. Making it robust required defining fingerprint similarity precisely, handling inconsistent reviewer decisions without corrupting the graduation log, and ensuring that graduated cases still appear in the audit trail without triggering re-review. The sticky vs. replaceable HITL classification was the conceptual breakthrough that made the graduation logic clean.
Real latency as a demo asset, not a liability. The agent running five rule engines, reading multiple Aerospike tiers, calling four live federal APIs, and then calling Claude produces real latency. Rather than hiding it, we made it the story: the first batch run takes ~52 seconds sequentially. The agent measures this, identifies the bottleneck, and cuts it to ~6 seconds on the next run. The latency problem became the self-improvement demonstration.
Solo build under time pressure. Every architectural decision had to earn its place. The temptation to add complexity was real; the discipline to cut anything that didn't serve the demo arc was harder.
Accomplishments that we're proud of The HITL graduation engine is the result we're most proud of. The insight — that of all the cases requiring human review, some have a sticky need for human judgment (novel fact patterns, regulatory ambiguity, inconsistent reviewer history) and some have a replaceable need (repeatable patterns with consistent rationale) — is not obvious, and implementing it in a way that is both demonstrable and auditable required genuine architectural thought.
The self-optimising execution loop is the second. The agent measuring its own performance, forming a hypothesis about the bottleneck, switching execution strategy, and confirming the improvement — all logged to longitudinal memory and visible in the dashboard — is a concrete, measurable instance of an agent that gets smarter while it runs.
The three-tier memory pipeline is the third. The Synix MapSynthesis → FoldSynthesis → ReduceSynthesis pipeline producing a compiled context document that is injected into every Claude prompt is, to our knowledge, a novel approach to agent memory that goes meaningfully beyond RAG retrieval. The agent doesn't just look things up — it carries a synthesized understanding of everything it has learned.
What we learned The most important thing we learned is that context engineering is a storage and pipeline problem, not a prompt problem. The quality of Claude's compliance reasoning improved not from better prompts but from better context — specifically, from injecting Synix-compiled memory that encoded graduated patterns and reviewer rationale directly into the prompt.
We also learned that the HITL boundary is not fixed. Most agent systems treat human-in-the-loop as a static gate. Examiner AI treats it as a dynamic classification problem: every HITL event is evidence that either reinforces the need for human judgment or argues for removing it. That reframe changes how you design the entire system.
Finally: Aerospike's sub-millisecond latency is not a performance optimization, it's an architectural enabler. Checking graduated_patterns before running the rule engine only makes sense if the check is cheaper than the rules themselves. At sub-millisecond, it is. At Postgres latency, it isn't.
What's next for Examiner AI The graduation engine today works at the case-type level — same fingerprint, consistent decisions, graduate. The next version should work at the rationale embedding level: clustering reviewer rationale semantically, identifying when the reasoning converges even when the surface features of the cases vary. That is a meaningful step toward an agent that generalizes from human judgment rather than merely pattern-matching it.
The second priority is multi-institution memory. Today, the Synix pipeline is per-institution. A federated version — where graduation patterns from one community bank can inform the prior for another, with appropriate privacy boundaries — would dramatically accelerate the cold-start problem for new institutions.
The third is Bland AI integration: after every batch, Norm delivers a 60-second voice briefing to the loan officer summarizing decisions, escalations, and anything the agent learned. Compliance as a conversation, not a dashboard.
The deeper ambition is a general framework for HITL graduation in any agentic system — a reusable library that any agent can use to classify its own human dependencies as sticky or replaceable, and to systematically convert the replaceable ones into automated capabilities over time.
Built With
- d3-scale-build-tooling:-kiro-(aws-agentic-ide)-infrastructure:-docker-(aerospike)
- durable)-ghost-db-(timescale-postgresql)-?-durable-audit-log
- fed-funds-rate-bls-(bureau-of-labor-statistics)-?-state-unemployment-rates-fdic-?-enforcement-actions-by-state-cfpb-?-mortgage-complaint-volume-by-state-frontend-mapping:-react-simple-maps
- graduated-patterns-memory-/-context-pipeline:-synix-(github.com/marklubin/synix)-?-mapsynthesis-?-foldsynthesis-?-reducesynthesis-memory-compiler-observability:-mlflow-(self-hosted)
- hitl-decision-history
- languages:-python
- longitudinal
- overmind-(prompt-optimization-+-trace-collection)-live-data-apis:-fred-(federal-reserve)-?-30yr-mortgage-rate
- react
- session
- typescript-frameworks:-fastapi
- vite-llm:-anthropic-claude-(haiku-+-sonnet)-via-direct-api-?-no-langchain-databases:-aerospike-?-real-time-tiered-memory-layer-(ephemeral

Log in or sign up for Devpost to join the conversation.