-
-
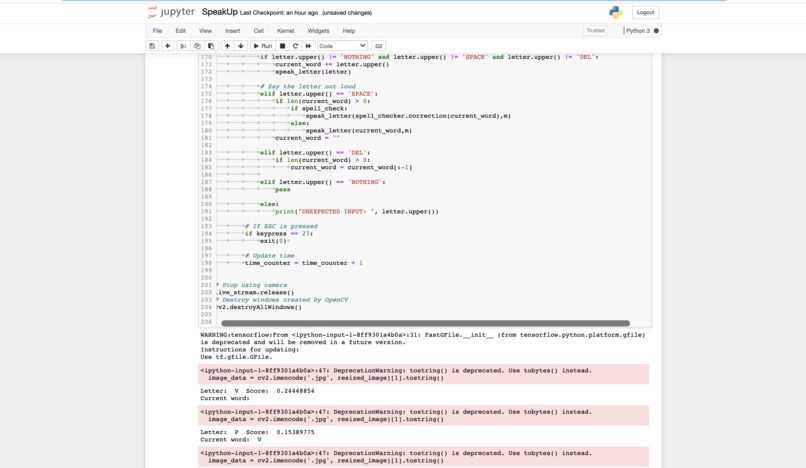
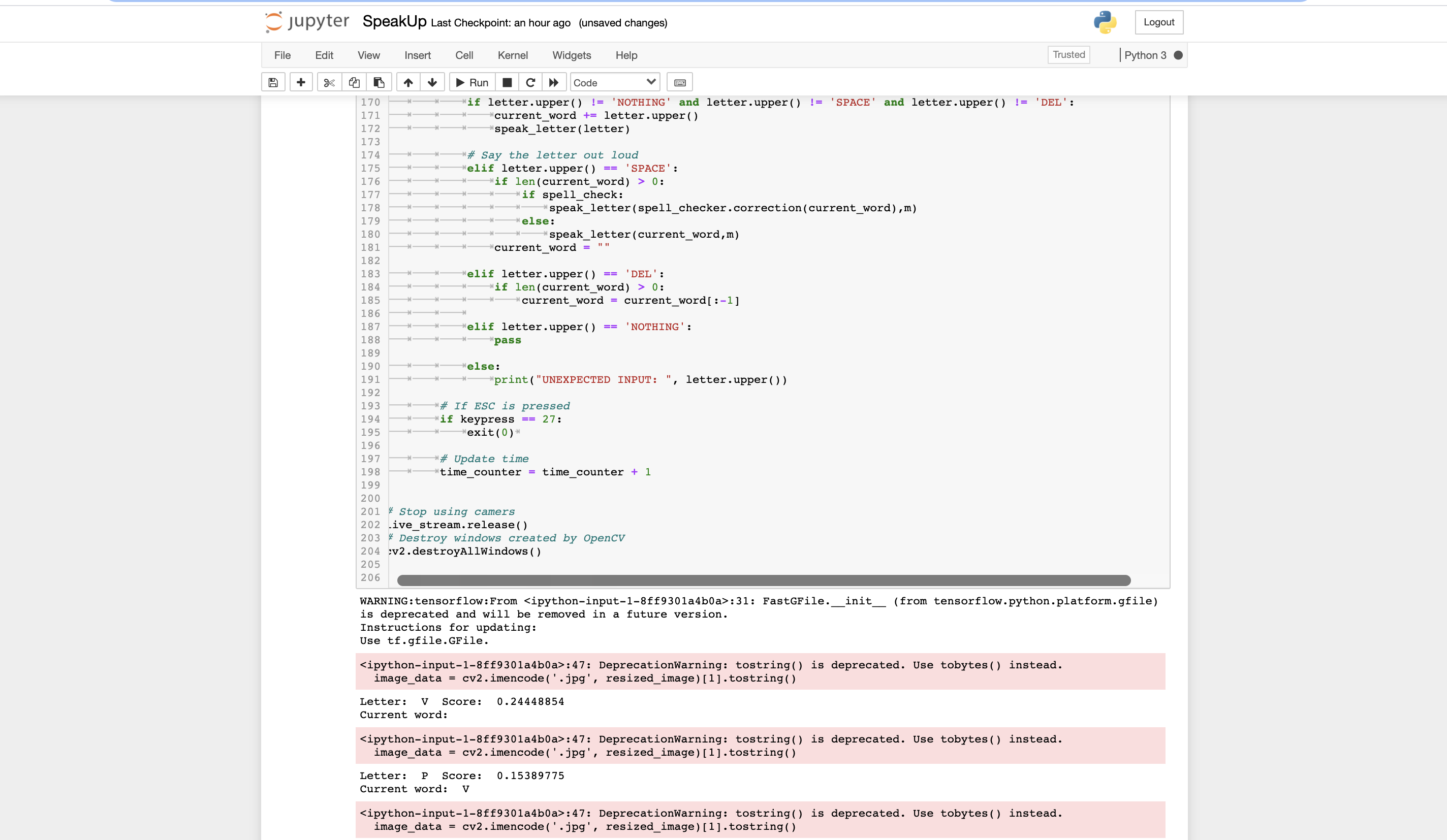
Code Screenshot
-

Running code screenshot

Inspiration
With the pandemic setting in, most of the communication in the workplace, schools and university is taking place via online video conferencing platforms. As a result, people who have hearing and speaking impairments are left behind in these video meetings as they are not able to actively participate. Further, they have to heavily rely on basic text-based chat which is not a very ideal channel of communication as many a time people tend to miss chat messages. We saw this hackathon as an opportunity to build a web application that converts images consisting of American Sign Language(ASL) used by people having hearing and speaking impairments and translating it in real time to speech. To achieve this goal we made use of a combination of pre-trained CNNs, transfer learning and the state of the art Microsoft Cognitive Science AI API. We are determined to build a solution which is more inclusive and helps people with hearing and speaking impairments communicate naturally in video meetings regardless of whether their colleagues know the sign language.
What it does
We are building a web application which takes as input a series of image frames comprising gestures made by a person in the sign language and converting this into speech data. We used the pre-trained CNNs alongwith transfer learning to convert the sign gestures made by a person in a video to text data. Further, we used the Microsoft Cognitive Science AI API to convert the text data to speech.
How we built it
We used the CNNs to convert the signs made by a person in a video to text data. Further, we used the Microsoft Cognitive Science AI API to convert the text data to speech. We have built and deployed our model on the Microsoft Azure Platform. This CNN model is trained on a series of continuous image frames where a person is signing the American Sign Language(ASL). The ASL data-set used to train the model is linked here. Our data consists of 29 folders with 3000 pictures in each, for each of the 26 letters of the ASL alphabet. The 3 extra folders are space, delete and nothing. We have split our data in a manner such that 80% of the photos are in the training set , and 20% are in the validation set.
Challenges we ran into
Working with image data was no feat and was an added complexity. Further, it was difficult to understand the different layers of the CNN remove the final layer and then fine-tune the model to suit our needs
Accomplishments that we're proud of
We were able to successfully recognize hand gestures in ASL alphabets and convert them to english text data. Further, by using the Microsoft Cognitive Science API we were able to convert this text data to speech
What we learned
We learnt how to build an end to end web application using technologies blob services, HTTP request-response protocols and Machine Learning Libraries like Tensor Flow and Keras. Further, we learnt how to effectively utilize the Microsoft Azure Platform to deploy our model. Additionally, we also learnt how to use the Microsoft Cognitive Sci API to convert the text based data into speech.Apart from this, we developed a good understanding of the challenges faced by people with hearing and speaking impairments and they can effectively communicate using ASL.
What's next for SpeakUp - An Inclusive Video Conferencing application
Currently, we have trained our model only using ASL data. An immediate next goal would be to expand the scope to include the three most commonly used sign languages for English i.e. - British Sign Language (BSL) and Australian Sign Language (Auslan). An extended goal would be to build a more generalizable model to include the 300 different types of sign languages used across the globe. Further, we also want to explore the possibility of our model being able to recognise the various gestures used to communicate via sign languages.
Built With
- azure
- azure-iot-suite
- blob
- keras
- microsoft
- python
- tensorflow


Log in or sign up for Devpost to join the conversation.