-
-
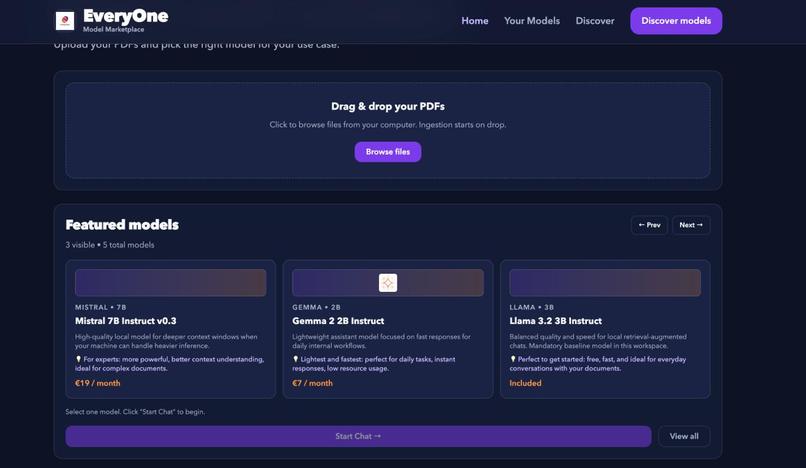
Old version
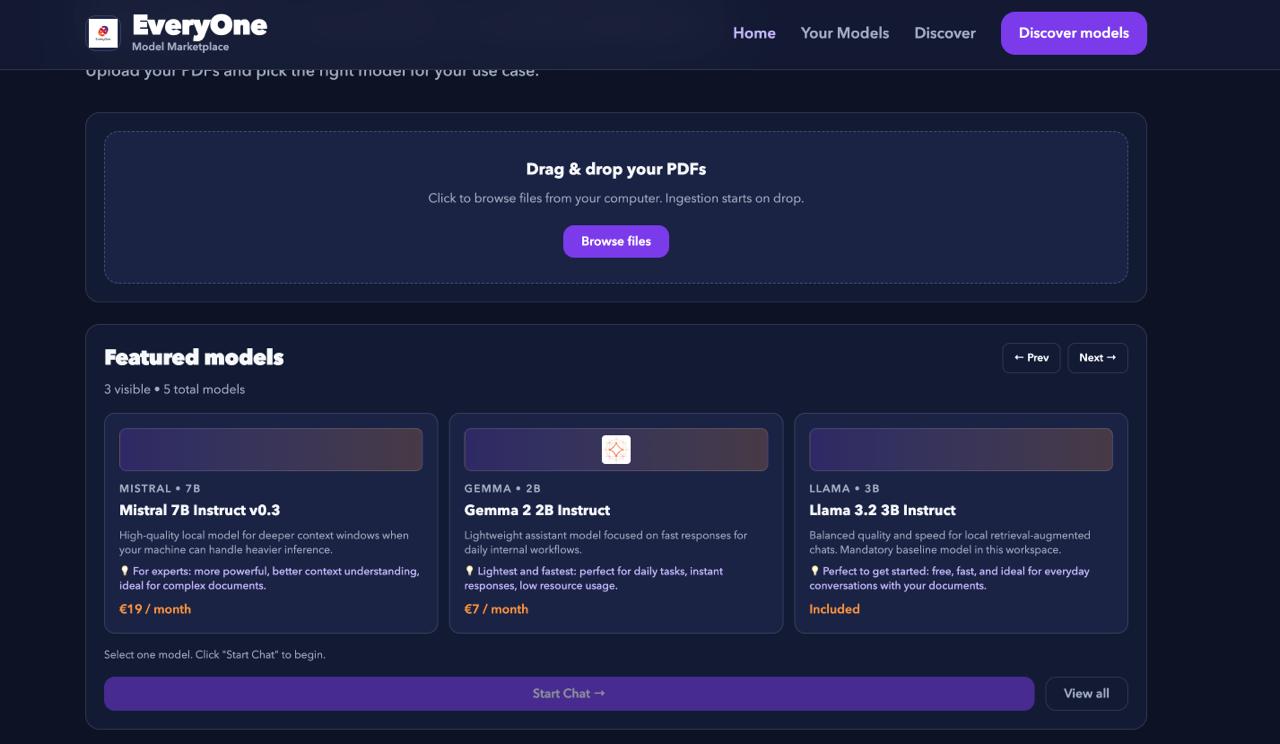
EveryOne — Local AI That Truly Belongs to You
Team: The Den — Hackeurope
Inspiration
We live in a world where most AI tools require sending your data to remote servers. For sensitive documents — legal contracts, medical records, research papers — this is a dealbreaker. We asked ourselves: what if you could have a fully capable AI assistant that never leaves your machine?
We believe the future of AI is not massive, power-hungry LLMs running in distant data centers. It’s not in the cloud.
It’s in your pocket.
That vision became EveryOne: a local-first RAG and fine-tuning platform that puts the power of language models entirely in the user's hands.
What We Built
EveryOne is a web application that lets you:
- Ingest PDF documents and store them in a local vector database
- Query your documents using RAG (Retrieval-Augmented Generation) with a locally running Small Language Model (SLM)
- Fine-tune a model on your own data, directly on your machine — no cloud, no API keys, no data leakage
The retrieval pipeline uses semantic search based on cosine similarity between embeddings:
$$\text{score}(q, c) = \frac{\vec{q} \cdot \vec{c}}{|\vec{q}| \cdot |\vec{c}|}$$
Where $$\vec{q}$$ is the query embedding and $$\vec{c}$$ is the chunk embedding.
The top-$$k$$ chunks are retrieved and injected into the model's context window before generation.
How We Built It
The stack is fully local and open-source:
- Frontend: React + Vite + Tailwind CSS
- Backend: FastAPI (Python)
- Embeddings:
sentence-transformers/all-MiniLM-L6-v2 - Vector storage: SQLite with raw
BLOBvectors - Inference:
llama.cppviallama-cpp-pythonfor GGUF model support - Fine-tuning: On-device training pipeline integrated into the UI
The RAG pipeline chunks each PDF page-by-page, embeds each chunk, stores them in SQLite, and retrieves the most semantically relevant passages at query time. The answer is then generated fully locally by the selected SLM.
Challenges We Faced
Getting page-level tracking right. Our initial chunking pipeline concatenated all pages before splitting, losing page number information entirely. We had to rearchitect ingest_pdf.py to chunk page-by-page and store the page number alongside each chunk in the database.
Dependency hell. Combining bleeding-edge versions of torch, sentence-transformers, llama-cpp-python, and FastAPI on macOS ARM created a web of conflicting dependencies that took significant time to untangle.
Performance on CPU. Running inference locally without a GPU means latency matters. We tuned chunk sizes, overlap, and top-$$k$$ retrieval to minimize the context passed to the model while maximizing answer quality.
On-device fine-tuning UX. Making fine-tuning feel accessible through a web interface — without exposing raw training complexity — required careful abstraction of the training pipeline behind simple UI controls.
What We Learned
- Local AI is more accessible than people think — you don't need a GPU farm to build something genuinely useful
- SQLite is surprisingly capable as a vector store at small-to-medium scale
- The gap between "it works in a notebook" and "it works as a product" is where most of the real engineering lives
What's Next
- Support for more document types (DOCX, Markdown, web pages)
- Quantization options to run even larger models on modest hardware
- A fine-tuning evaluation dashboard to measure model improvement
- Export/import of fine-tuned adapters (LoRA) for sharing between users

Log in or sign up for Devpost to join the conversation.