-
-

Logo
-
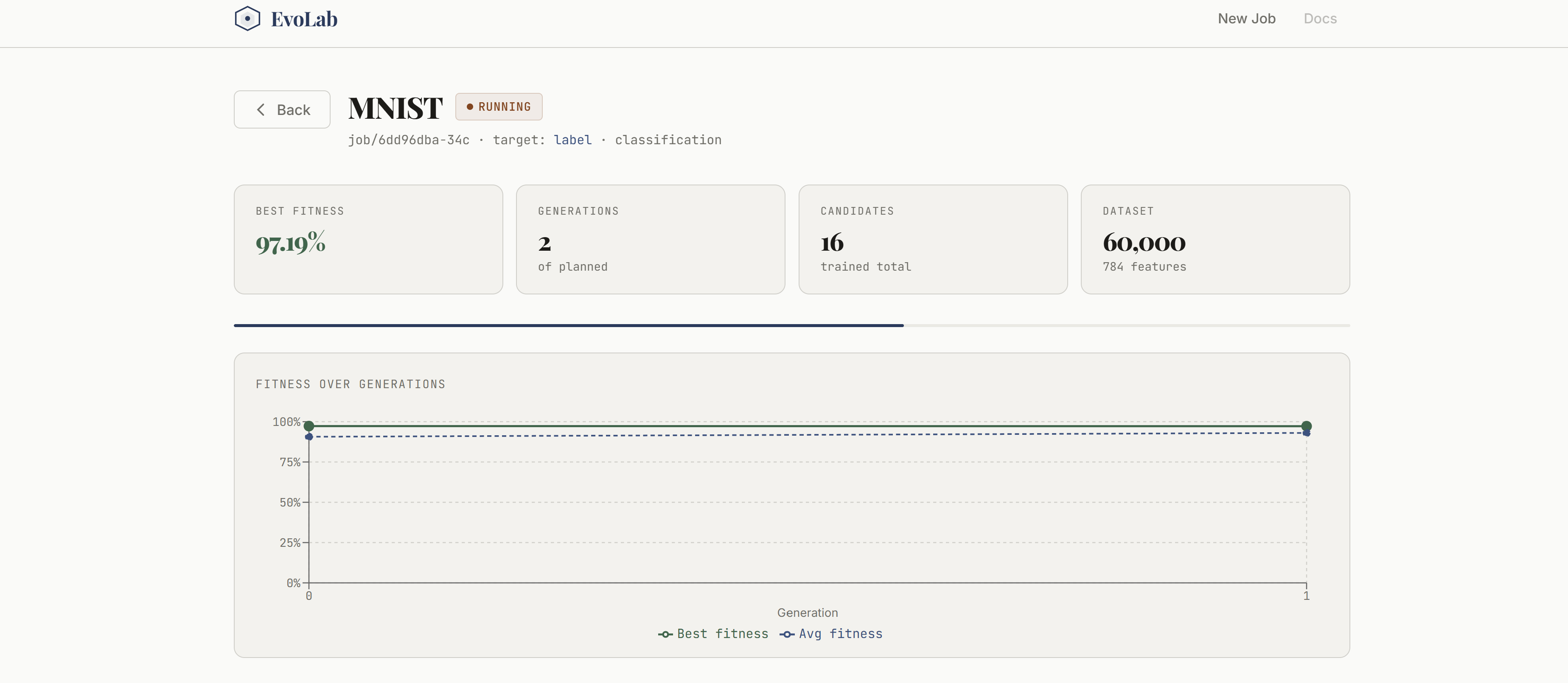
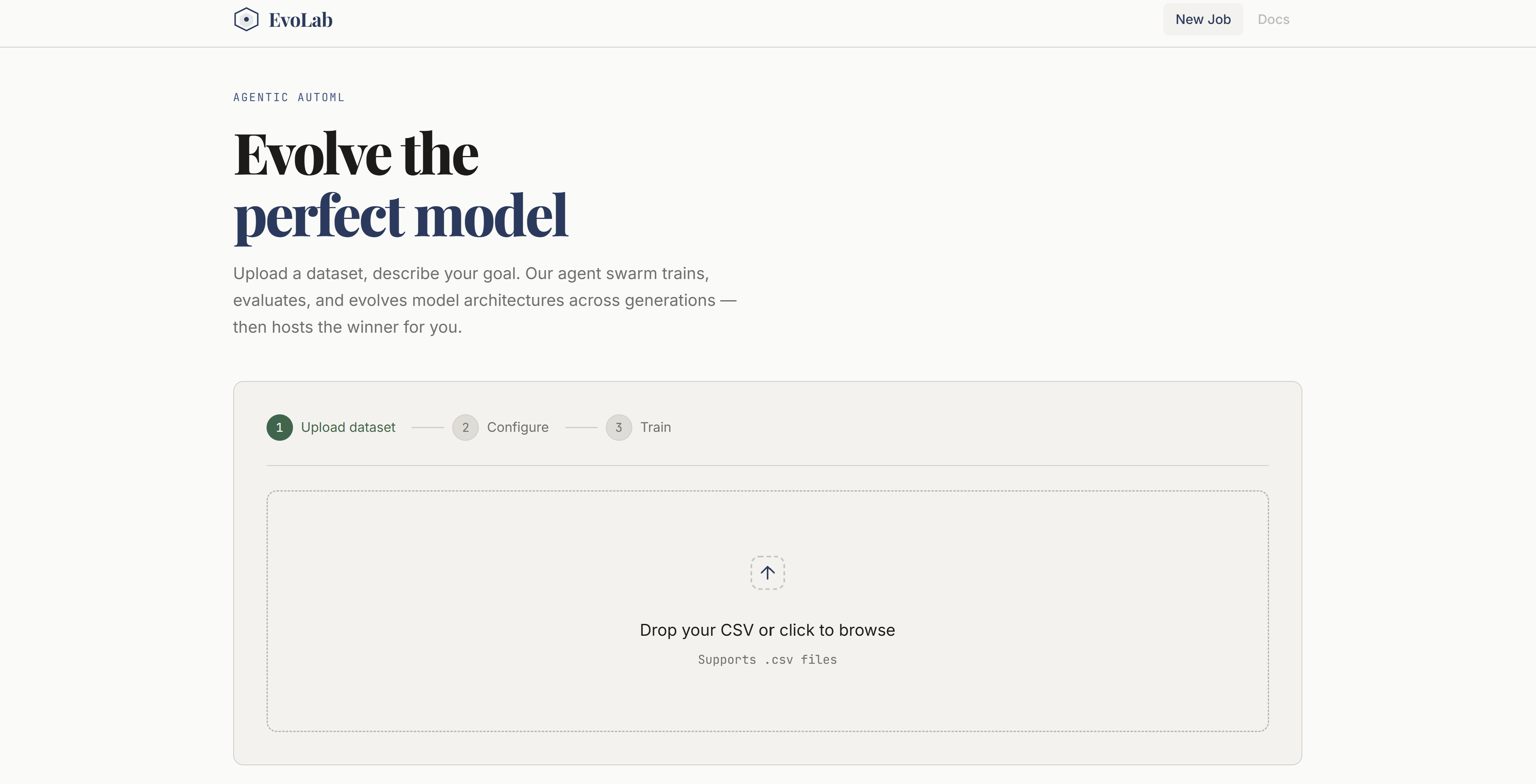
Dashboard
-
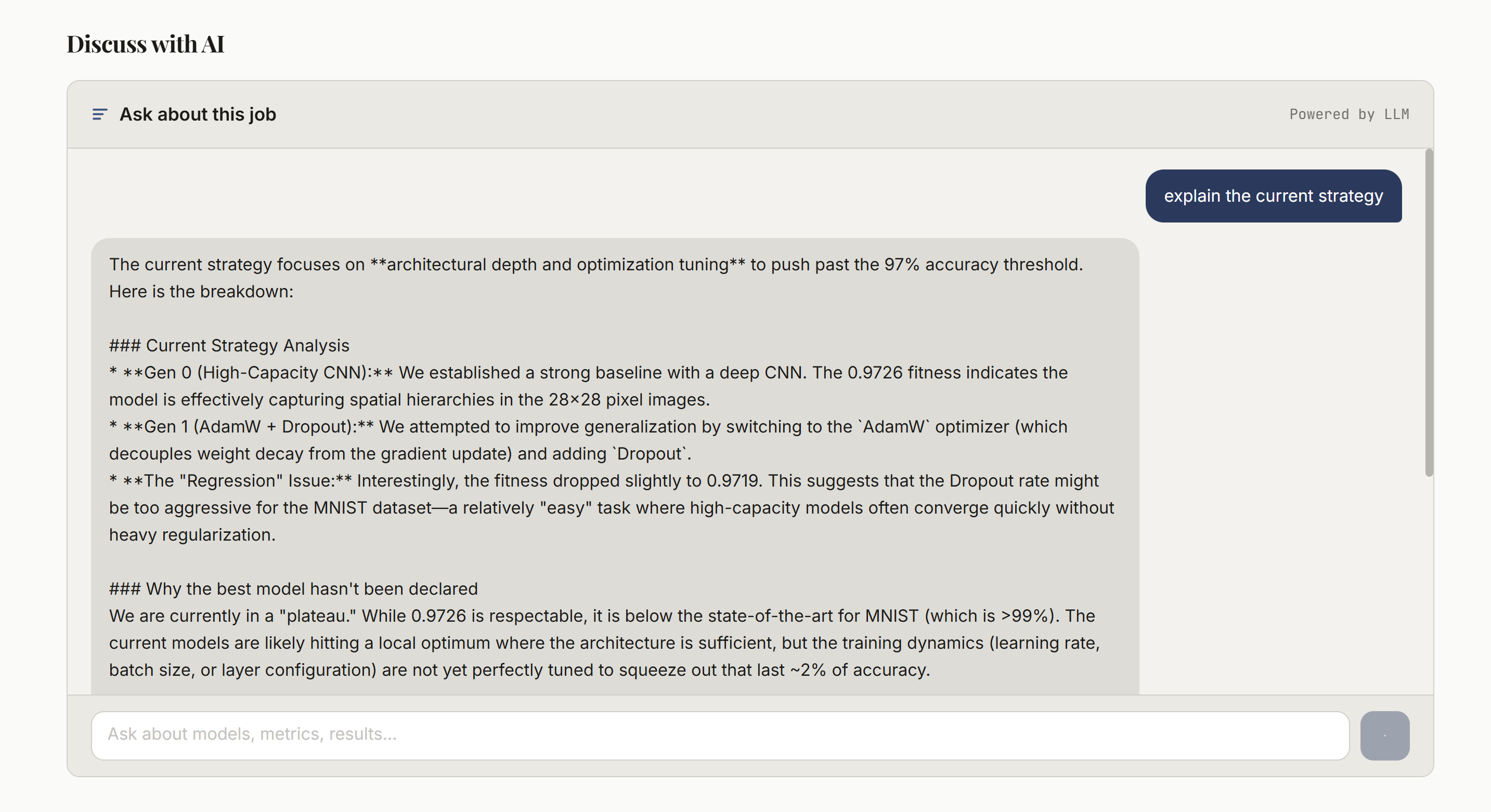
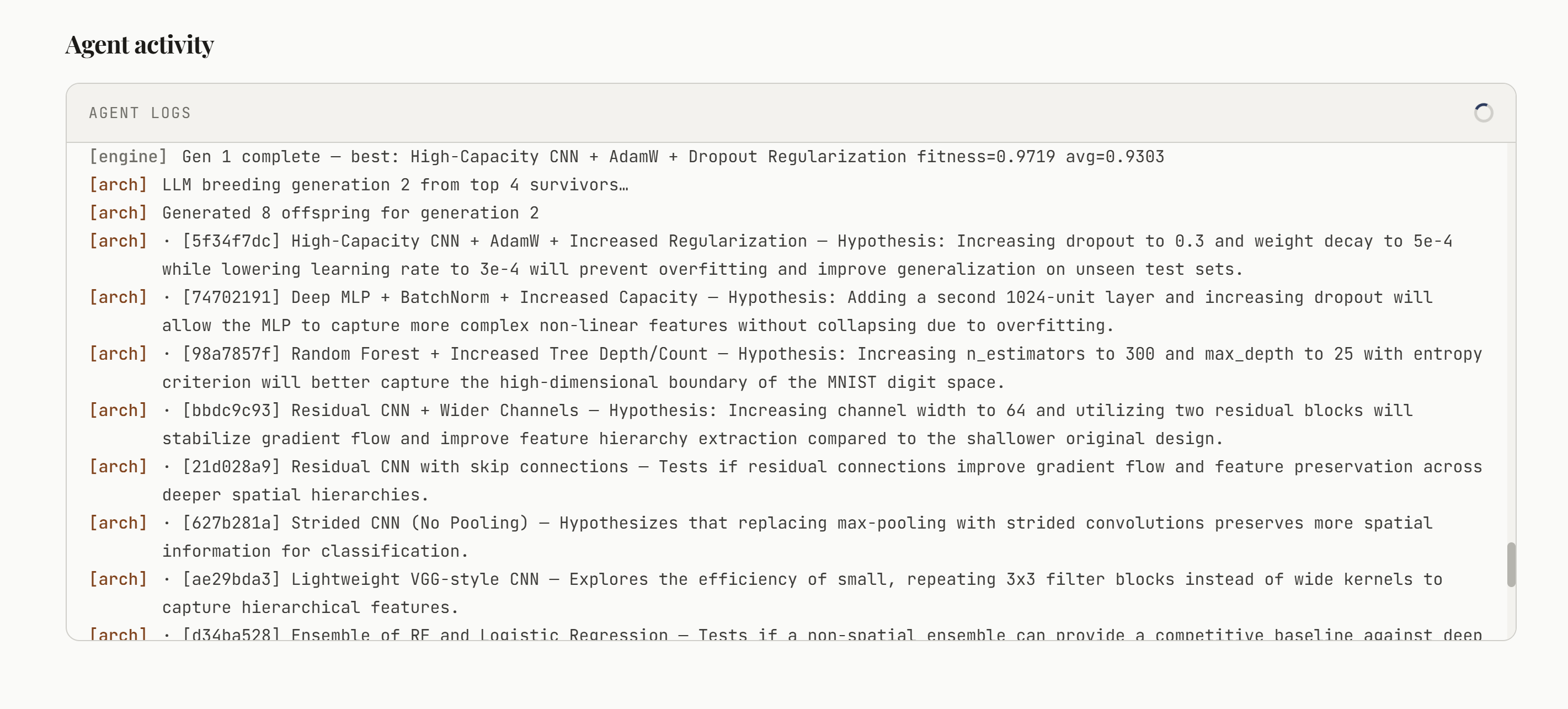
Model Chat
-
Data Upload
-
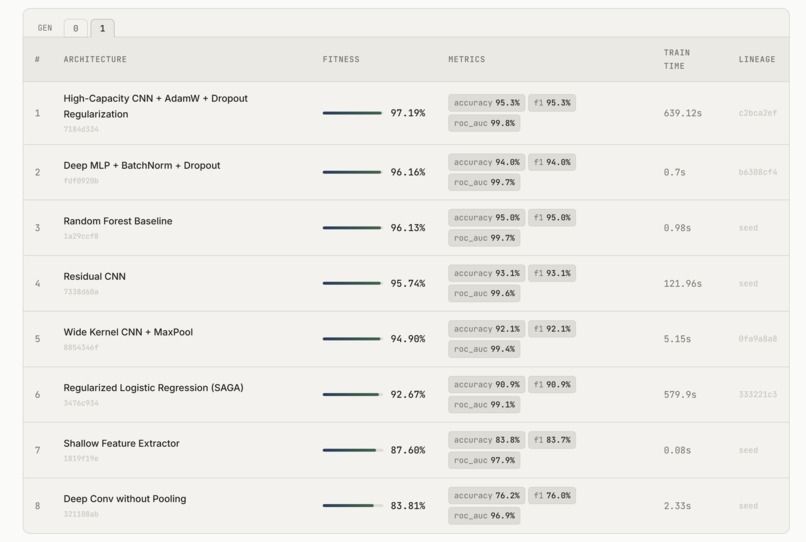
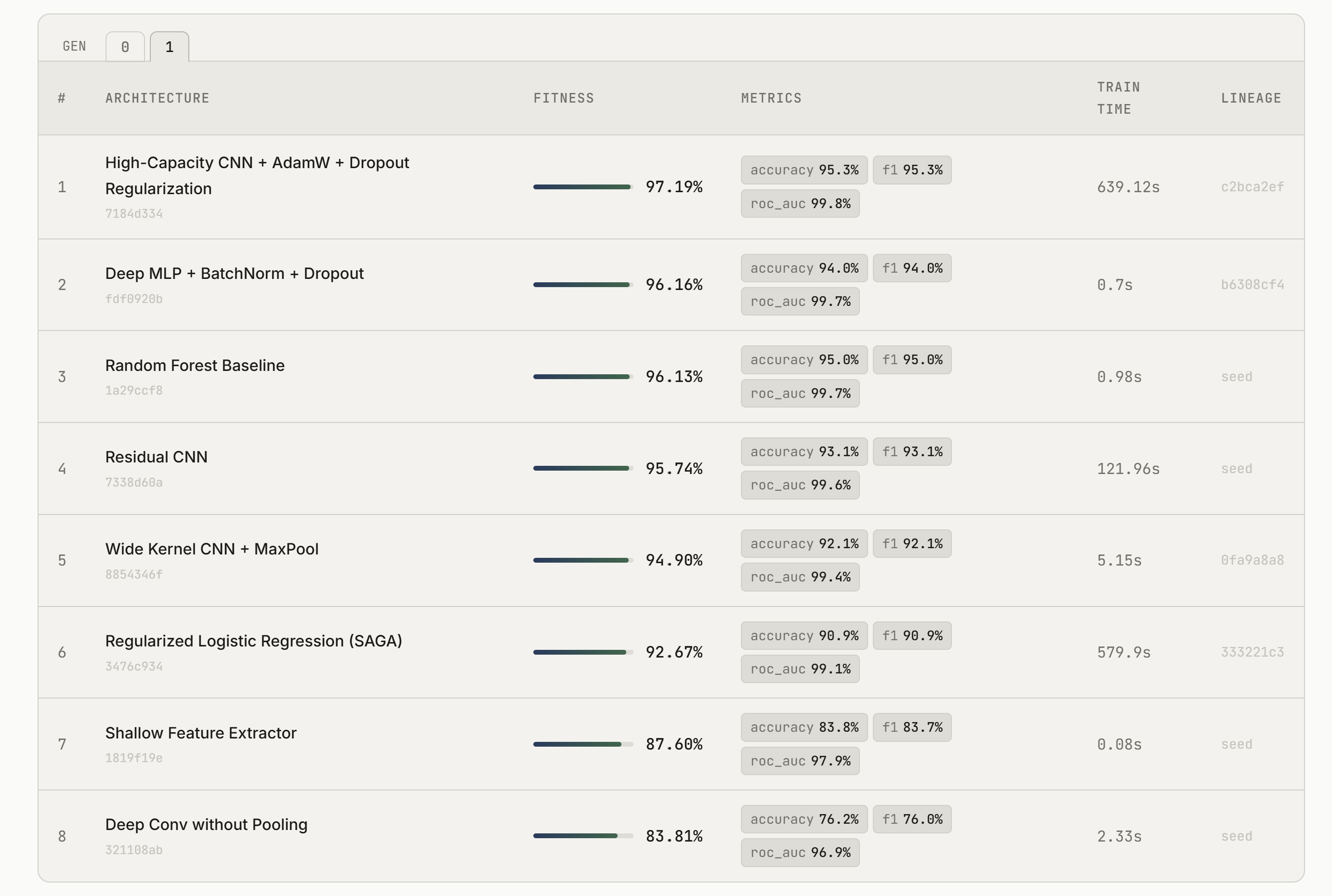
Model Architectures
-
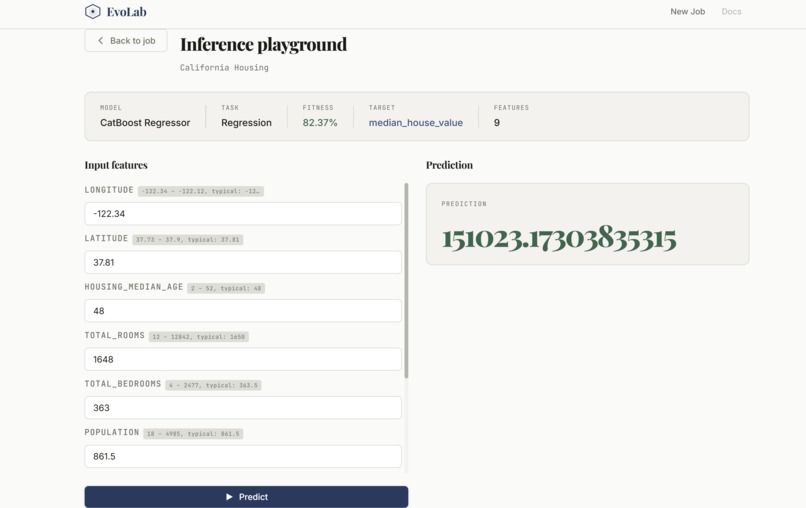
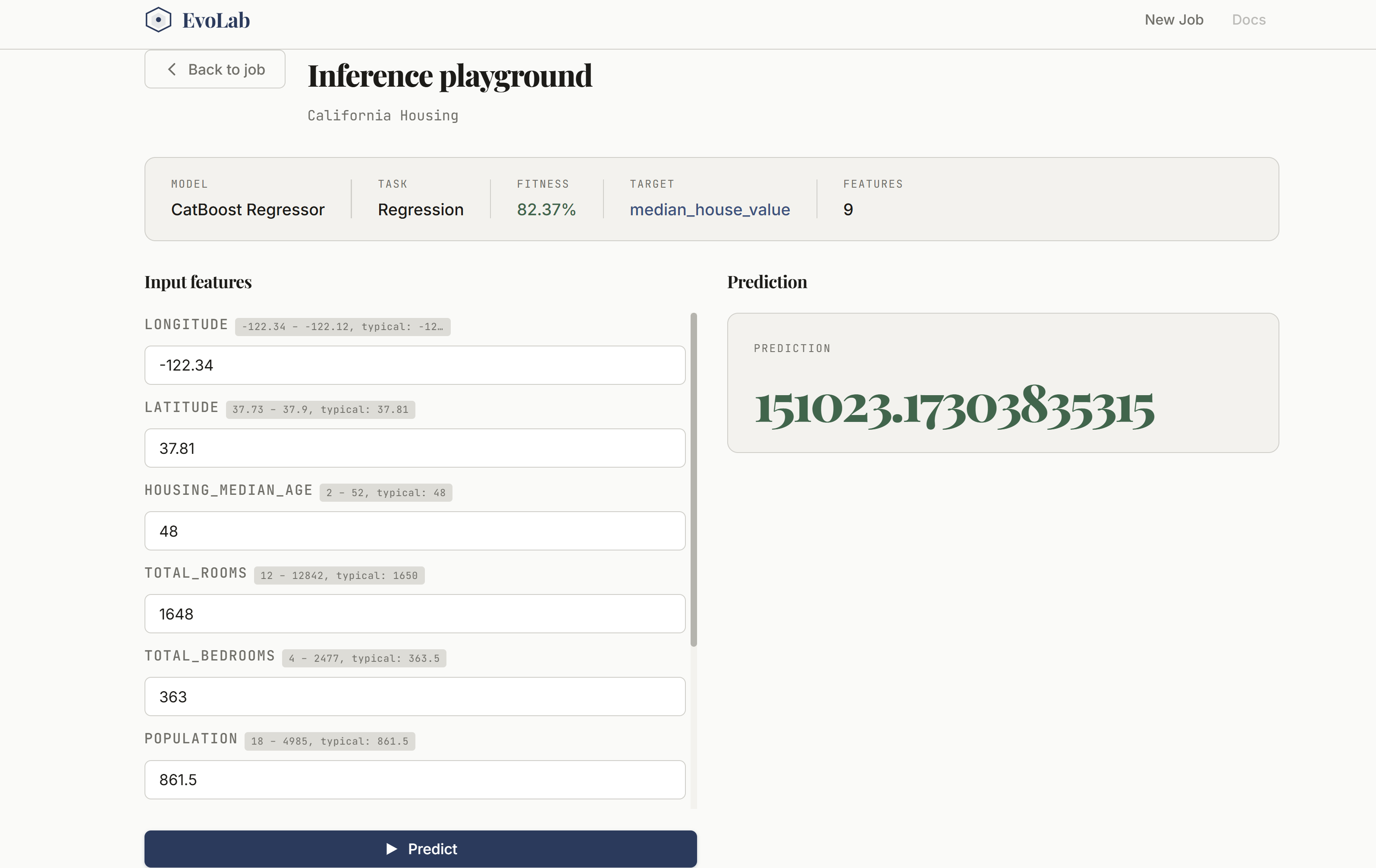
Inference Playground
-
Models

Inspiration
Creating and training ML models has always been something we thought was awesome, but it was super hard to actually do in practice. There are so many decisions—model choice, hyperparameters, data processing—that it becomes overwhelming fast. We wanted to make something that lowers that barrier and lets people actually experiment and learn without getting stuck in the setup.
What it does
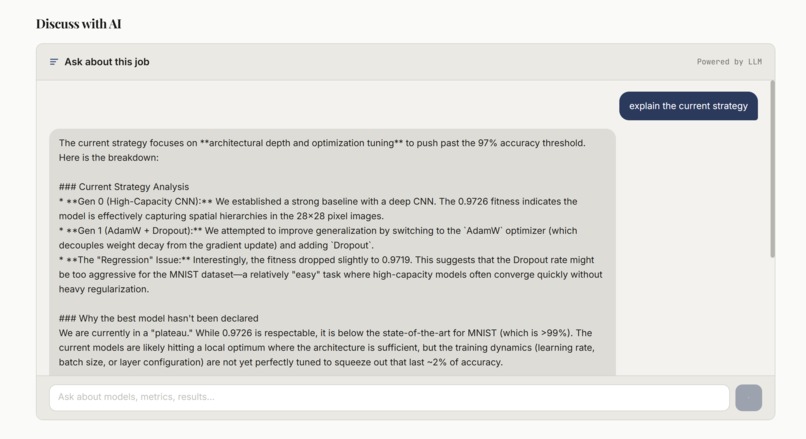
Trains optimized ML models for you and explains its thought process along the way, giving you both a strong model and the knowledge needed to create the next one yourself. Instead of just outputting a model, it shows why certain architectures were chosen, what worked, what didn’t, and how the model improved over time. It’s meant to feel less like a black box and more like a guided ML workflow.
How we built it
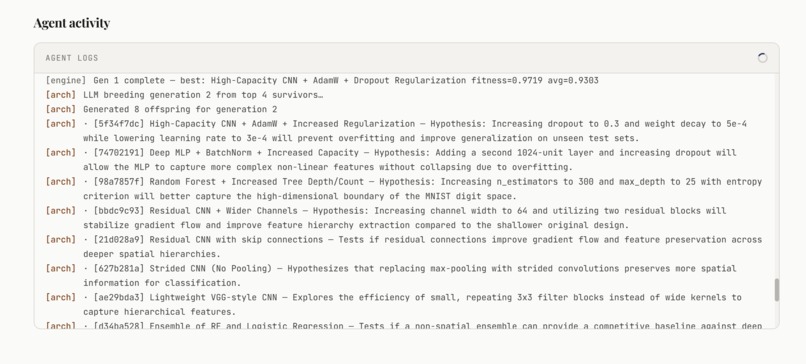
React frontend, Python Flask backend. We used a planner–executor–critic agent cycle where a top-level planner proposes model ideas, executor agents train them, and a critic evaluates performance and suggests improvements. This loops for multiple iterations to refine results.
For ML, we used libraries like PyTorch and scikit-learn depending on the task. We used Lava for API management and Gemini as the core model driving planning and reasoning. The system samples from the top-performing models and mutates them with new ideas, similar to a genetic algorithm, which helps explore the search space efficiently.
Challenges we ran into
Computation load for training is high, but we solved this by training on small subsets for evaluation before scaling to full datasets. Parallelization was tricky—we used Python threads to run experiments concurrently, but managing shared state and avoiding bottlenecks took some effort.
Debugging was also challenging, especially with multiple agents interacting, so we built a custom error logger to track failures across runs. Another challenge was finding the right balance of model architectures (for example, giving deep learning models a fitness boost since they train slower but can perform better). We also had to make sure the system didn’t just overfit to quick wins like simple models.
Accomplishments that we're proud of
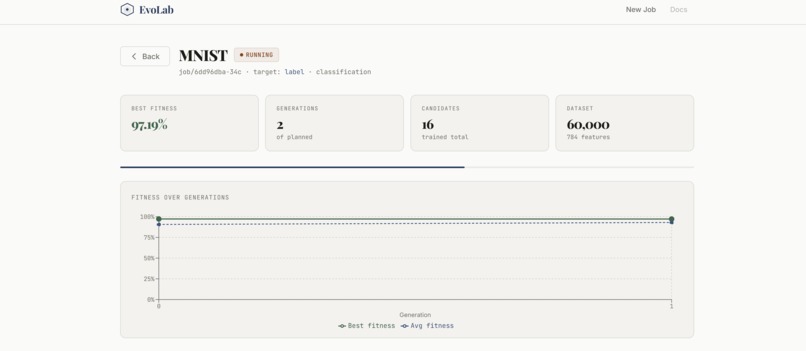
Putting this together in such a short time scale. The UI looks clean and usable, and the system actually feels interactive instead of static. We also got strong results on datasets like MNIST and California Housing, showing that the approach works across both deep learning and traditional ML tasks.
The agent loop working end-to-end was a big win—it can generate ideas, test them, and improve without manual intervention.
What we learned
How to use agents in a more sophisticated way, especially coordinating multiple agents with different roles. We learned a lot about ML models from EvoLab itself, since it surfaces patterns in what works and what doesn’t.
We also learned a lot about time management and prioritization—figuring out what actually matters to get something working in a hackathon setting versus what can be left for later.
What's next for EvoLab
Generalize to more complicated tasks and datasets, including larger-scale and real-world problems. Improve parallelization and scaling so we can handle more experiments at once and explore bigger model spaces.
We also want to improve the explanation side, making the reasoning even clearer, and potentially integrate more advanced optimization strategies to push performance further.


Log in or sign up for Devpost to join the conversation.